DeepLab系列
论文:
(DeepLabV1)Semantic image segmentation with deep convolutional nets and fully connected CRFs
(DeepLabV3)Rethinking Atrous Convolution for SemanticImage Segmentation
(DeepLabV3+)
目录
0.简介
DeepLab为一系列的工作,从14年到现在跨度也比较久,我会把每篇工作的关键点都梳理一下,这四篇工作本身也是一代代改进来的,所以会有一些一直延用并改进的东西,也会有DeepLab放弃了的东西,前者我们深入学习,后者简单了解。
1.DeepLab V1
这里只简单说下V1做了什么,详细的讲解我想放到V2里开始讲,因为那时候的研究已经有更深的认识。这里就当作个前情提要吧。
2014年,正是DCNN在图像领域爆发后的那段时间,图像分类、目标检测等领域基于DCNN取得空前进展,语义分割领域当然也会一头扎进去。但对于语义分割这一需要准确位置信息的像素级任务,使用DCNN还需要解决如下问题:
- 重复池化下采样导致分辨率大幅下降,位置信息难以恢复。
- DCNN的空间不变性,位置信息丢失会使最后的分割结果粗糙,丢失细节。
所以本文也出一下两点来解决:
空洞卷积。基于VGG-16改造:
- 因为是做分割,所以把全连接层改成卷积层。
- 把最后两个池化层去掉,后续使用空洞卷积。

Fully Connected CRFs(条件随机场)。
改善DCNN的输出结果,更好捕捉边缘细节。
2. DeepLab V2
到了DeepLabV2的时候,多尺度问题已经被研究着们广泛且深刻的认识到,所以在V2的原文中,把DCNN应用到语义分割需要解决的问题又多了一个多尺度方面的,由原来v1中的两大问题变成此时的三个:
- 重复池化下采样导致分辨率大幅下降,位置信息难以恢复。
- 不同尺度物体的存在。
- DCNN的空间不变性,位置信息丢失会使最后的分割结果粗糙,丢失细节
然后原文给出了对应的三个解决方法:
- 空洞卷积
- ASSP(Atrous Spatial Pyramid Pooling)
- Fully Connected CRF
整体结构
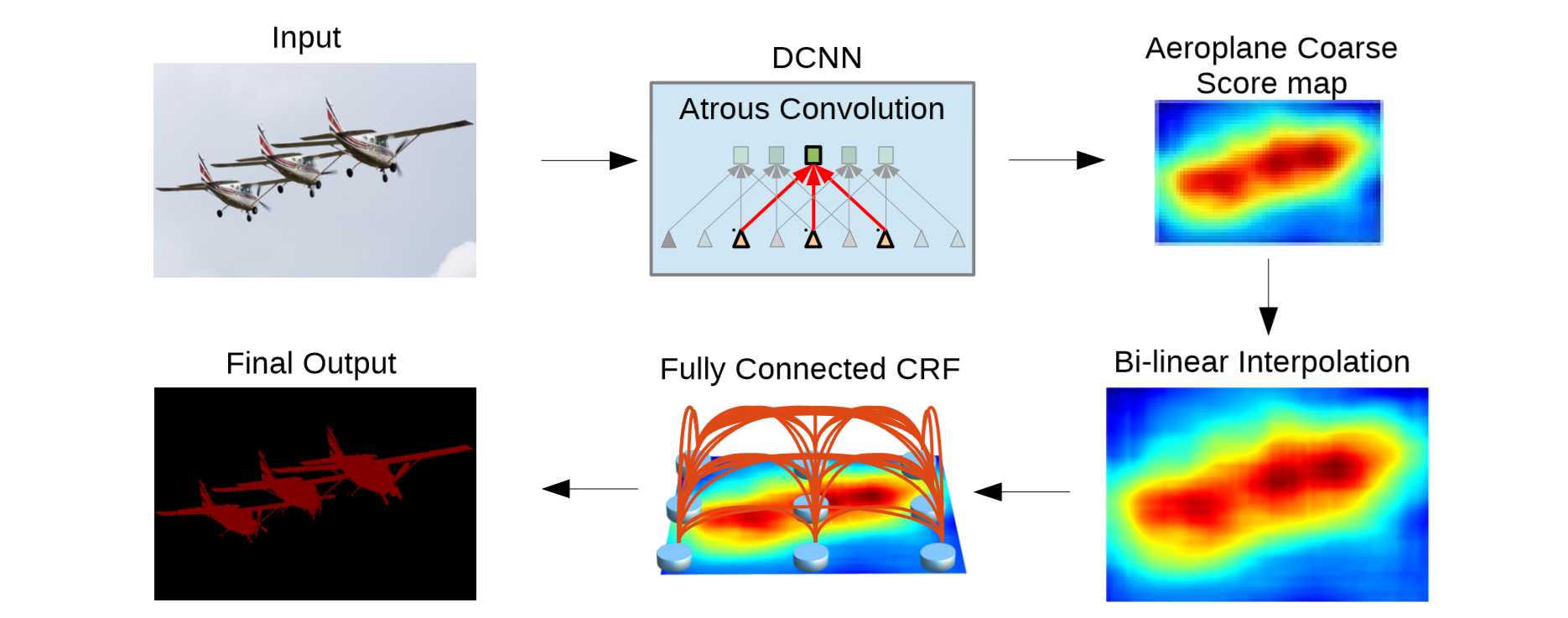
图像输入,进入到改造过的DCNN(VGG-16或ResNet-101,空洞卷积、ASSP都是在这里),得到分辨率略小的特征图,然后进行双线性插值恢复分辨率,使用全连接CRFl来改善分割结果(去噪、平滑、更好的捕捉边界)。
空洞卷积
DCNN随着进行,会使feature map变小,得到更high-level的特征。主要是因为:
- conv的stride>1 —— 为了得到更大感受野
- max pooling操作 —— 为了得到更high-level的特征
得到这样high-level的特征有利于图像分类、目标检测等任务,但DCNN这样的特点不能直接用于语义分割这样的要求高精密的像素级任务。
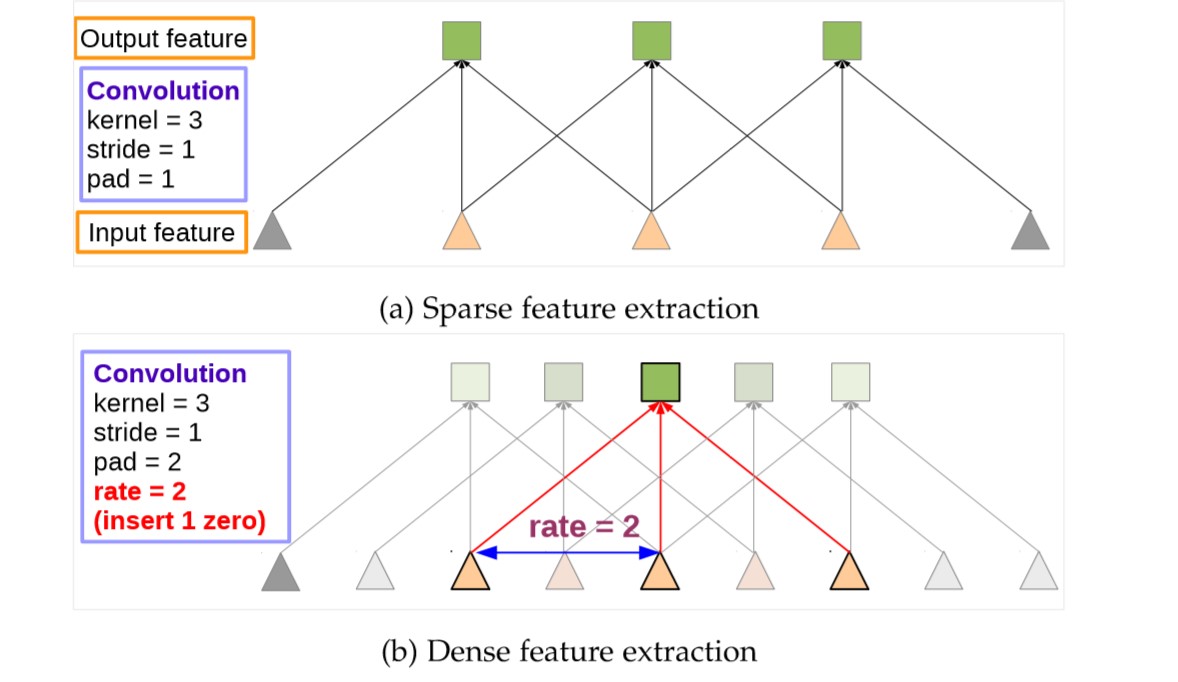
对于这一问题,作者强调(卷积+上采样滤波器)or(空洞卷积)是有力的解决工具,实际使用空洞卷积来解决,空洞卷积由两个优势:一是可以控制图像的分辨率不至于太小,解决上述问题;二是增加感受野。
首先要明白,通过控制参数,在紧密特征图上的空洞卷积可以产生和在系数特征图上标准卷积一模一样的结果;也可以产生更紧密的特征,即高分辨率的特征图,如下图所示:
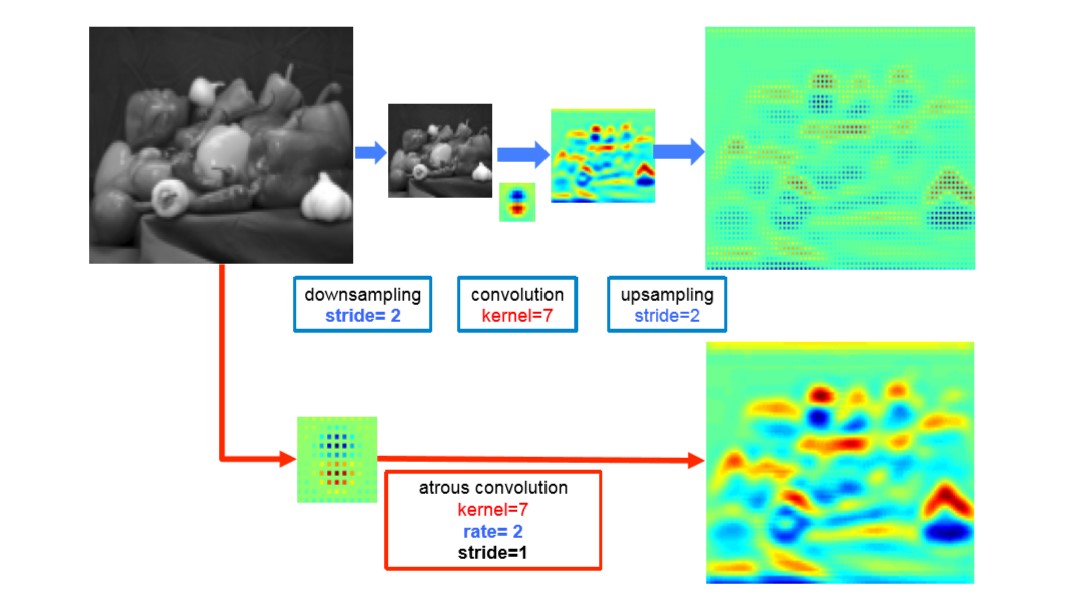
再结合第三节DeepLabV3串联结构中讲的,应该就完全理解了。
ASSP
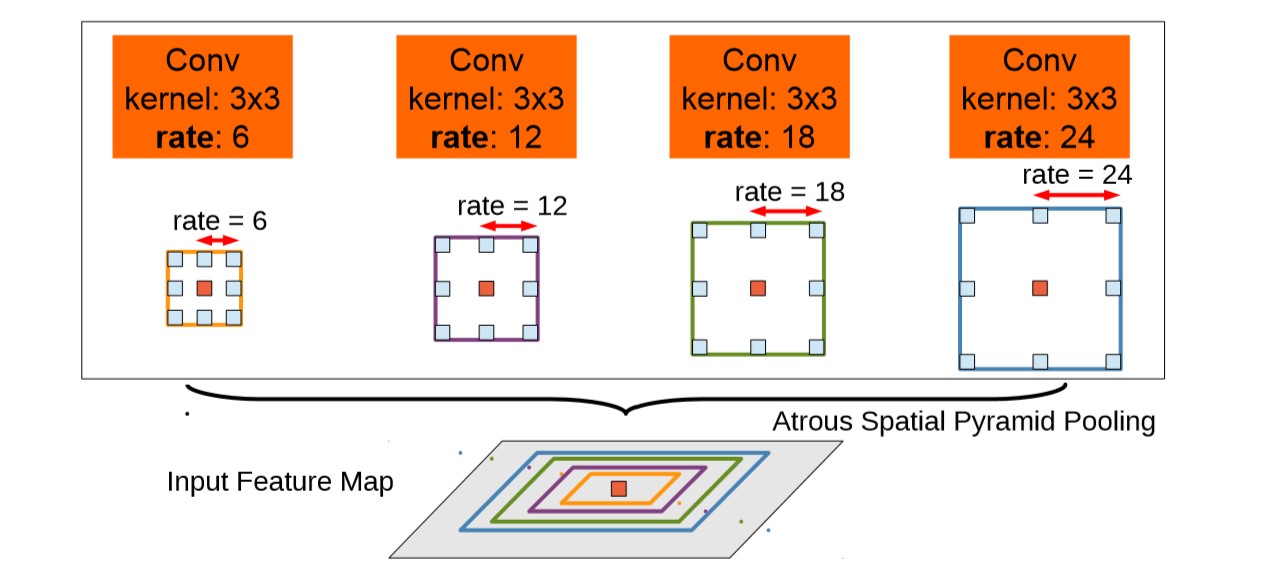
图像中存在多种尺度的物体,这是影响视觉检测、分割等任务精度的一大问题,如果网络抽象能力较强则更容易识别大尺度的物体但会忽略小尺度的物体,如果抽象能力较弱则可以较好识别小物体但抽象大物体的能力势必较弱,就是这样一种矛盾,研究者们提出各种方法来解决,本文基于空洞卷积设计了ASSP结构(Atrous Spatial Pyramid Pooling)。
即得到一feature map后,接入一个并行结构,并行结构中的每个分支结构都一样,唯一不一样的就是各自卷积的膨胀率。如下图所示。不同膨胀率的卷积可以得到不同的感受野,膨胀率小的卷积感受野小,对小尺度的物体识别效果较好;膨胀率大的卷积感受野大,对大尺度的物体识别效果好。空洞卷积对于感受野、并行空洞卷积解决多尺度问题,推荐阅读目标检测领域的一项工作,原理解释、实验非常充实——TridentNet。Scale-Aware Trident Networks for Object Detection
Fully Connected CRF
(这一方法在之后的版本就放弃了,我对此暂时也没有多大兴趣,仅限于跟着论文学习了一遍,这里就简单介绍吧,数学及原理就不再梳理了)
条件随机场(CRF,Conditional Random Field)一般用来处理分割不平滑问题,它只考虑到目标像素点的附近点,是一个短距离的CRFs。由于网络中得到的结果已经比较光滑了,更希望的是修复一些小的结构,处理边缘细节,所以用到了全连接CRF模型。能量函数中有一部分高斯核函数,其值由两点间的位置和颜色决定,位置为主,颜色为辅,算是一句话说一下浅显的说明一下原理吧。
3.DeepLab V3
串联结构
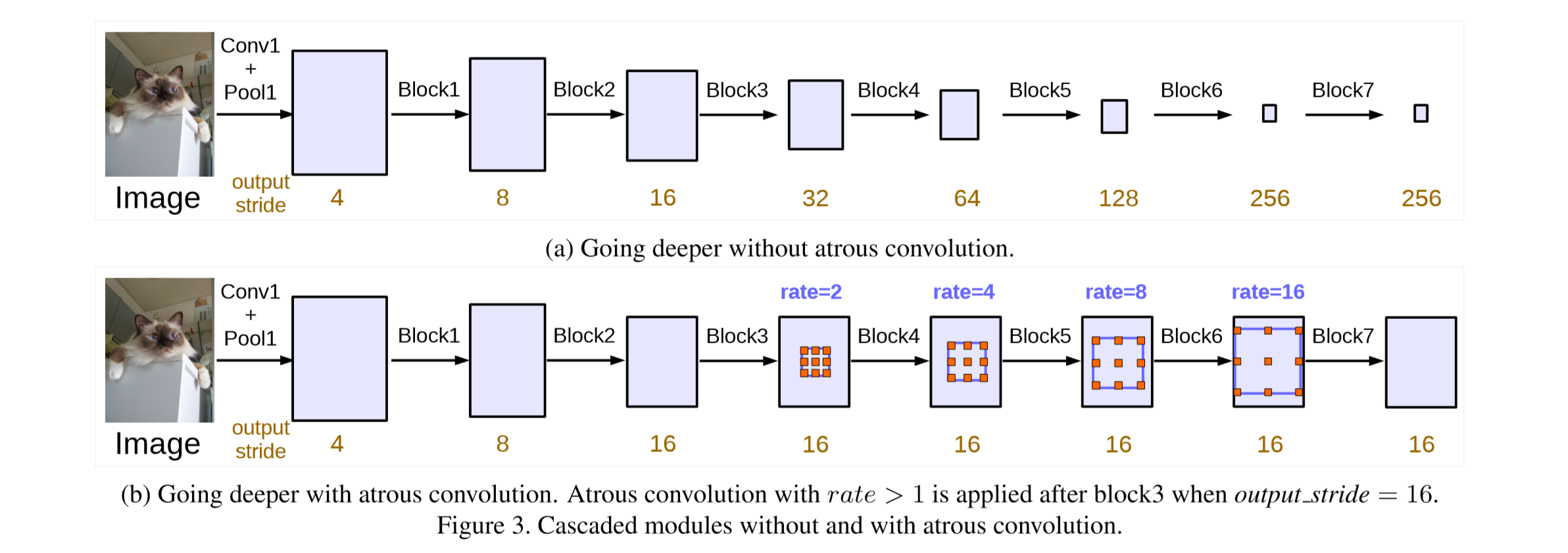
基于ResNet。使用标准卷积时,当网络越来越深,output stride越大,feature map越小。每一个block中有三个3×3的卷积,最后一个卷积的stride=2,feature map就是因为这个变小的(除最后一个block的最后一个卷积,它的stride=1)。
低分辨率的feature map难以恢复位置信息得到好的分割结果。分辨率变低是因为stride=2,令stride=2的原因是,希望随着网络的深入,感受野越来越大,越有利于获得high-level的信息。
那有没有什么办法既能获得较大感受野,又能有高分辨率(output stride低)的特征图呢?就是DeepLab在使用的空洞卷积了!有了第二节DeepLabV2中的空洞卷积介绍基础,看到这里应该完全理解了。
作者设计的这一使用空洞卷积的串联结构,把block4重复了四遍,即block5, block6, block7都是block4的复制品,唯一不同的是其中的膨胀率(rate / dilation),取决于想要的output stride。
作者还考虑了multi-grid方法,即每个block中的三个卷积有各自unit rate,例如Multi Grid = (1, 2, 4),block的dilate rate=2,则block中每个卷积的实际膨胀率=2* (1, 2, 4)=(2,4,8)。
并联结构
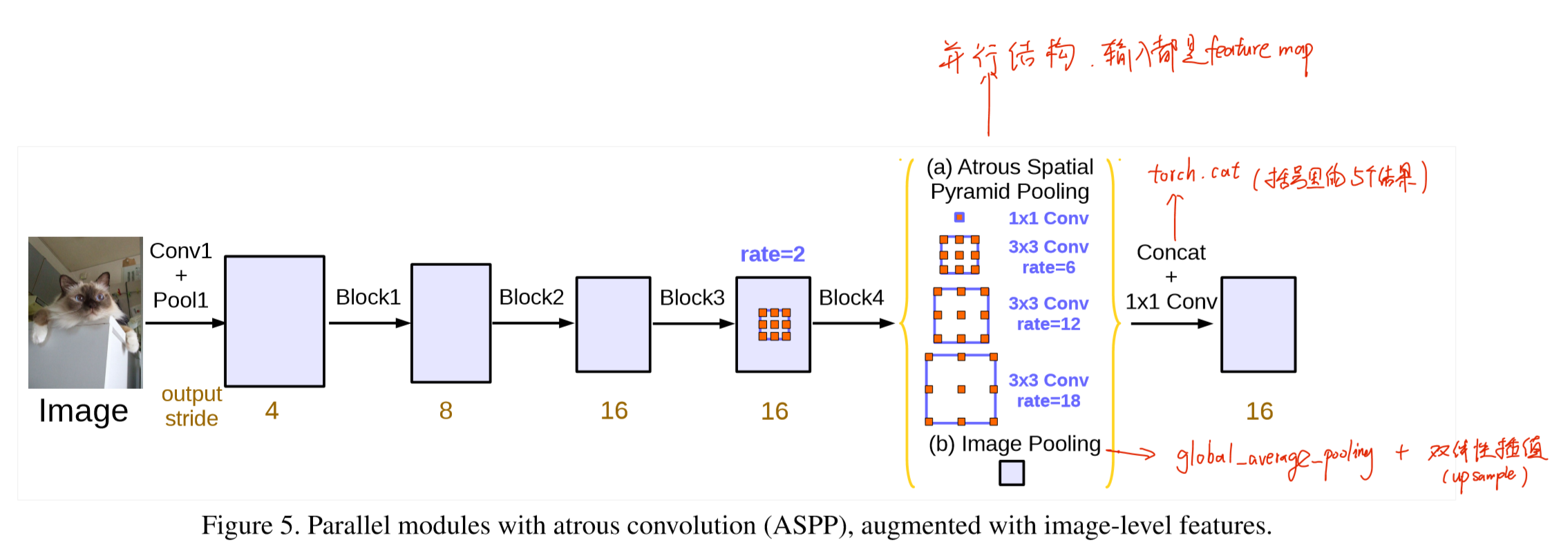
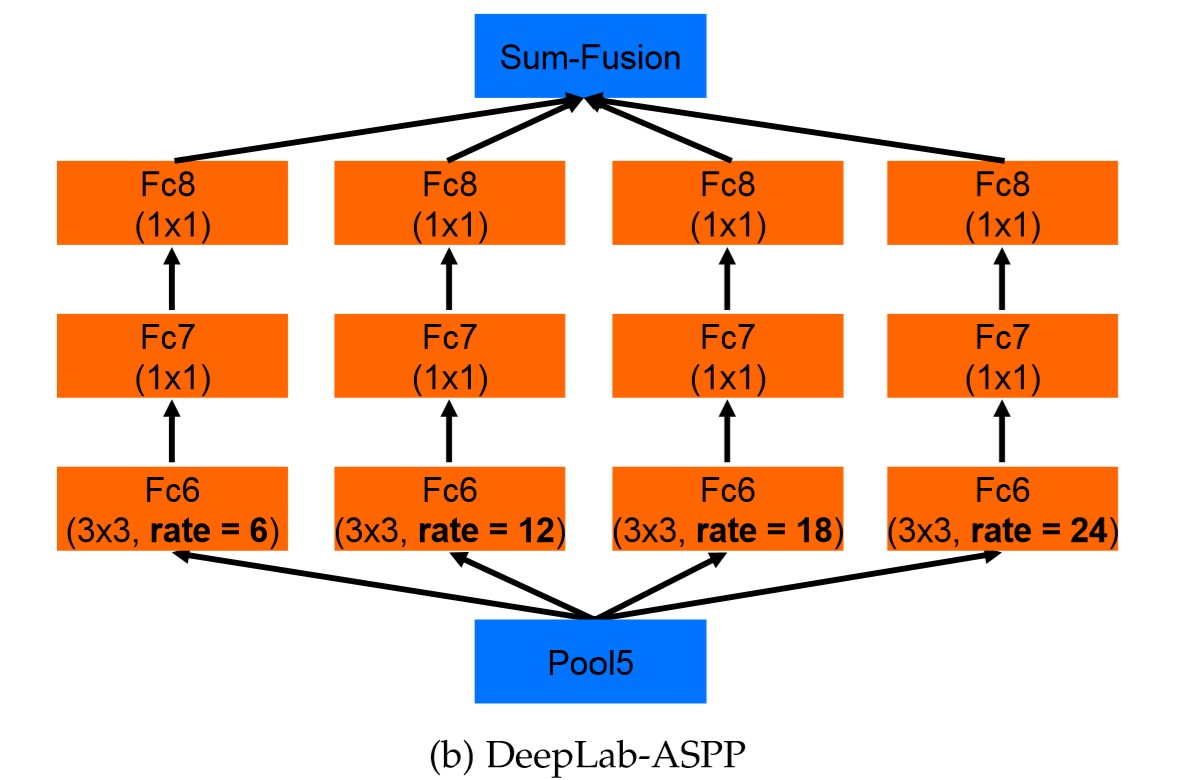
如上图所示,block4之后连接并联结构,其中上面四个为ASSP,下面一个为image-level feature,他们的输入都为前面的feature map,最后这五个结果拼接成一组特征,看源码torch.cat就很好理解了。
ASSP改进
相校对DeepLabV2的ASSP,唯一的区别就是加了BN层...
当想让output stride=16时,ASSP包括了一个1×1卷积,和rate=(6,12 ,18)的3×3卷积,都是256通道。
image-level feature
用ASSP并列加入image-level feature是因为作者为了解决空洞卷积带来的一个问题:
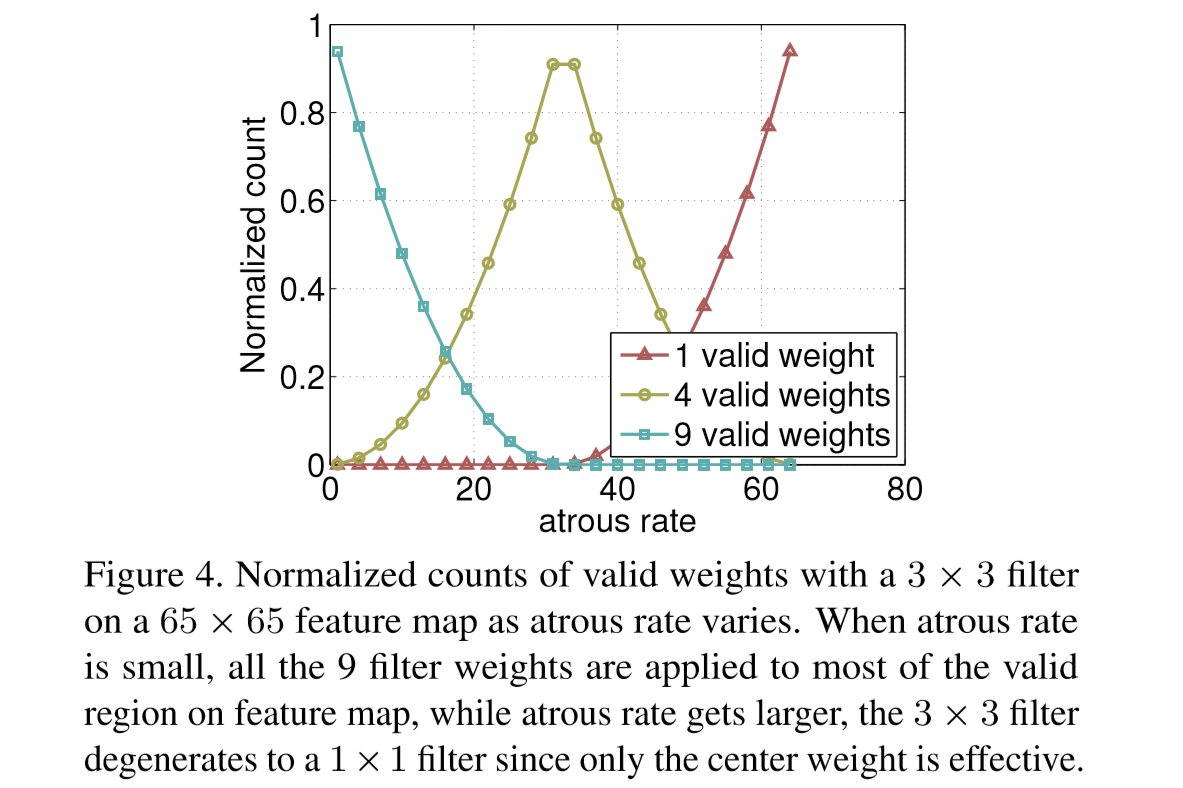
随着空洞卷积的膨胀率(rate/dilation)增大,卷积核有效参数越来越少。是的,这个很容易理解,3×3、rate=1即标准卷积,只有在feature map最外面一圈会有卷积核参数超出边界而无效,当rate变大,越来越多外圈的位置是有卷积核参数失效的,用极限思想思考一下,如果rate=size(feature map),那么每次卷积都是卷核中心对应的feature map像素点被计算了,卷积核参数也只有中心那个点没有失效,退化成了1×1卷积核。
作者正式为了解决这一问题,才在并联结构中加入image-level feature。做法是对输入的feature map全局平均池化(global average pooling),256通道的1×1卷积层,BN层,最后用户双线性插值的方法上采样到目标大小,即与ASSP输出的feature map尺寸相同。
4.DeepLab V3+
加入decoder
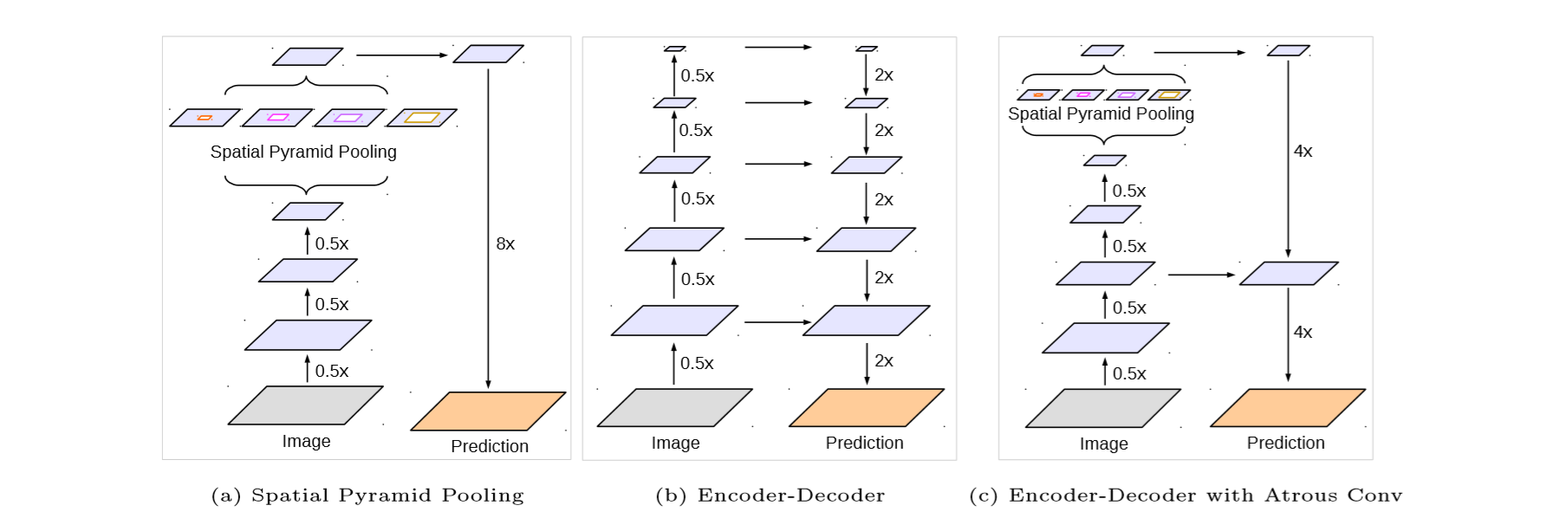
作者把DeepLavV3作为Encoder部分,加入decoder部分,称形成了一种融合了SSP和Encoder-Decoder的新方法。
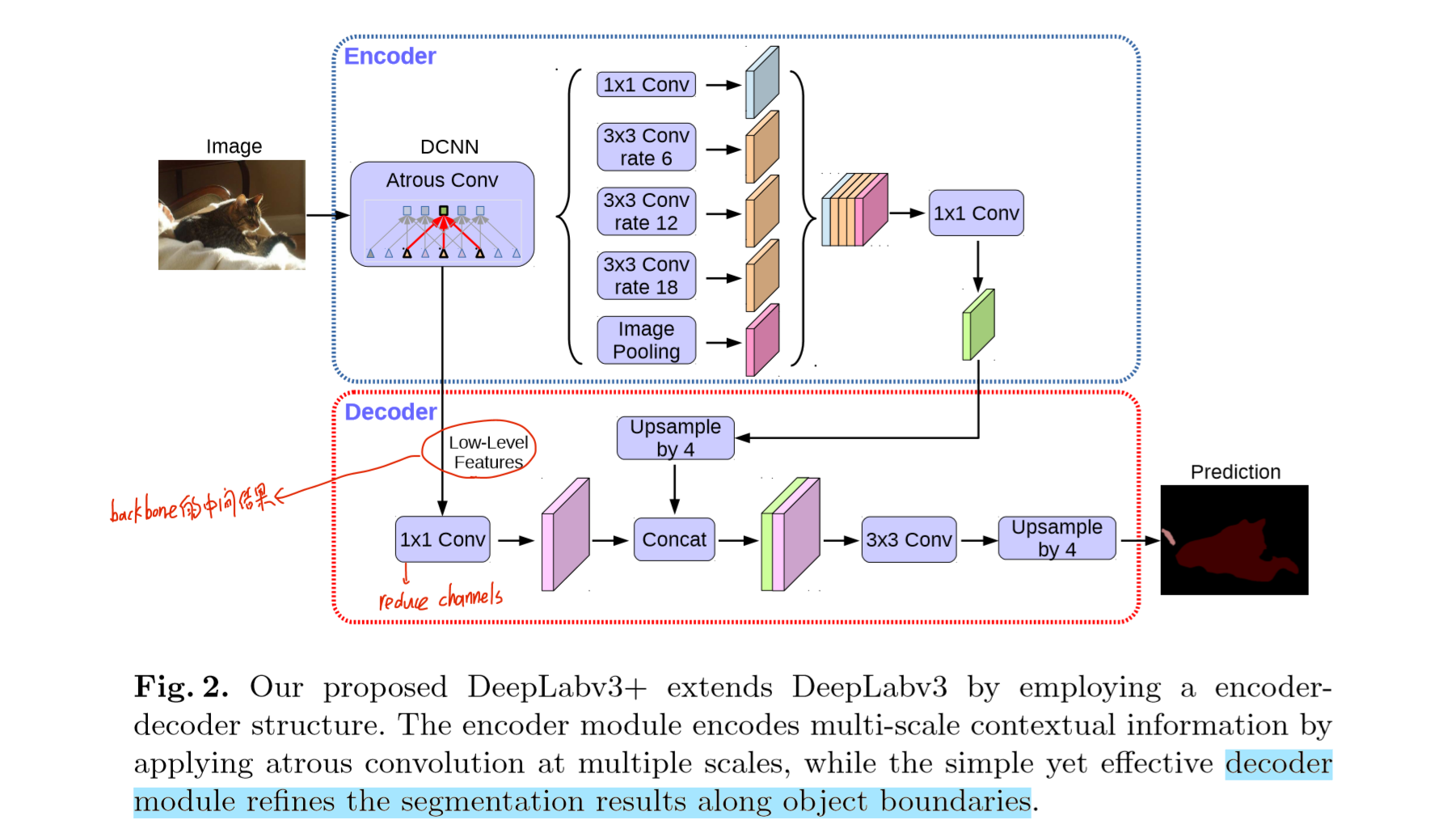
把整个网络DeepLabV3作为Encoder,提取融合多尺度特征;加入一个简单的结构作为Decoder,能够改善分割结构的物体边界。
图中的decoder的输入,即low-level features,并不是和ASSP的输入一样,而是backbone的某个中间计算结果,然后通过一个1×1卷积(为了减少通道数),结果与encoder输出(1×1卷积减少通道数,也上采样了到原来4倍)融合,再经过3×3卷积,再上采样4倍(至此16倍,已经恢复到原图大小)。
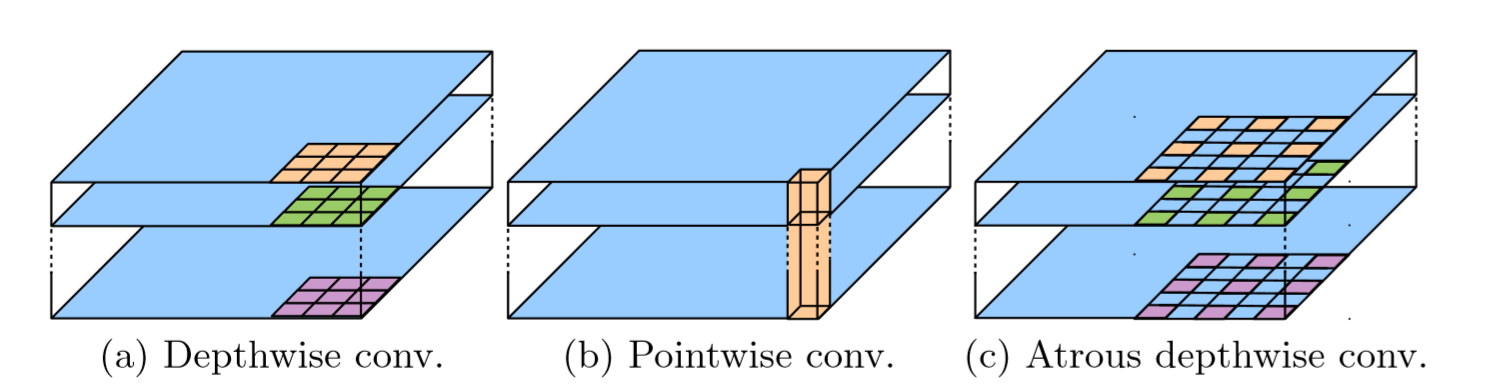
深度可分离卷积(depthwise separable convolution)
本作中使用了depthwise separable convolution代替标准卷积,Depthwise separable convolution由depthwise convolution和pointwise convoution两步完成。因为它能通过将标准卷积运算分为两步从而减少参数,但实现和标准卷积操作相同的效果。即depthwise separable convolution = depthwise convolution + pointwise convolution(既指流程,也值参数量)。详细内容和具体参数量计算请见下面的个人独立博客,因为我也是学习来的,而且博主写的很清晰明了,所以就不板门弄斧了:https://yinguobing.com/separable-convolution/
当然作者虽然使用了depthwise separable convolution方法来代替标准卷积操作,但依然是还是空洞卷积,看完上面那篇博客(或者本身就掌握深度可分离卷积),应该很容易就明白这句话。Atrous separable convolution只需要更改第一步为间隔取样,第二部pointwise convolution无需特别处理。
DeepLab系列,尤其是后面两作,他们的贡献除了提出新算法模型以外,还包括进行了大量的实验,包括模型中选择某些小结构、参数的对比实验,对于后面的研究者提供了宝贵的经验,节省了大量的实验资源与时间。
另外,学习时参考的代码是第三方pytorch实现的,Github地址放在参考链接里。
参考及引图:
Semantic image segmentation with deep convolutional nets and fully connected CRFs
Rethinking Atrous Convolution for SemanticImage Segmentation
Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
DeepLab系列的更多相关文章
- 语义分割丨DeepLab系列总结「v1、v2、v3、v3+」
花了点时间梳理了一下DeepLab系列的工作,主要关注每篇工作的背景和贡献,理清它们之间的联系,而实验和部分细节并没有过多介绍,请见谅. DeepLabv1 Semantic image segmen ...
- Deeplab
Deeplab系列是谷歌团队的分割网络. DeepLab V1 CNN处理图像分割的两个问题 下采样导致信息丢失 maxpool造成feature map尺寸减小,细节信息丢失. 空间不变性 所谓空间 ...
- struct2depth 记录
把效果图放在前面 03.28 handle_motion False architecture simple joint_encoder False depth_normalization ...
- 人工智能必须要知道的语义分割模型:DeepLabv3+
图像分割是计算机视觉中除了分类和检测外的另一项基本任务,它意味着要将图片根据内容分割成不同的块.相比图像分类和检测,分割是一项更精细的工作,因为需要对每个像素点分类,如下图的街景分割,由于对每个像素点 ...
- pytorch中检测分割模型中图像预处理探究
Object Detection and Classification using R-CNNs 目标检测:数据增强(Numpy+Pytorch) - 主要探究检测分割模型数据增强操作有哪些? - 检 ...
- 全景分割pipeline搭建
全景分割pipeline搭建 整体方法使用语义分割和实例分割结果,融合标签得到全景分割结果: 数据集使用:panoptic_annotations_trainval2017和cityscapes; p ...
- 理解CNN中的感受野(receptive-field)
1. 阅读论文:Understanding the Effective Receptive Field in Deep Convolutional Neural Networks 理解感受野 定义:r ...
- 自动网络搜索(NAS)在语义分割上的应用(二)
前言: 本文将介绍如何基于ProxylessNAS搜索semantic segmentation模型,最终搜索得到的模型结构可在CPU上达到36 fps的测试结果,展示自动网络搜索(NAS)在语义分割 ...
- SPG-Net: Segmentation Prediction and Guidance Network for Image Inpainting
SPG-Net: Segmentation Prediction and Guidance Network for Image Inpainting pytorch 引言 利用语义分割获取空洞的边缘信 ...
随机推荐
- P4554 小明的游戏 (洛谷) 双端队列BFS
最近没有更新博客,全是因为英语,英语太难了QWQ 洛谷春令营的作业我也不会(我是弱鸡),随机跳了2个题,难度不高,还是讲讲吧,学学新算法也好(可以拿来水博客) 第一题就是这个小明的游戏 小明最近喜欢玩 ...
- SpringBoot整合Swagger3生成接口文档
前后端分离的项目,接口文档的存在十分重要.与手动编写接口文档不同,swagger是一个自动生成接口文档的工具,在需求不断变更的环境下,手动编写文档的效率实在太低.与swagger2相比新版的swagg ...
- 图灵学院笔记-java虚拟机底层原理
Table of Contents generated with DocToc 一.java虚拟机概述 二.栈内存解析 2.1 概述 2.2 栈帧内部结构 2.2.1 我们来解析一下compute() ...
- 题解 洛谷 P4098 【[HEOI2013]ALO 】
考虑原序列中的每一个值作为构成最终答案的那个次大值,那么其所在的合法区间最大时,其对答案的贡献最大. 一个值作为最大值时有两个合法的最大区间,一个是左边第二个比其大的位置和右边第一个比其大的位置构成的 ...
- .net core 自带分布式事务的微服务开源框架JMS
事务的统一性是微服务的一个重点问题,简洁有效的控制事务,更是程序员所需要的.JMS的诞生,就是为了更简单.更有效的控制事务. 先看一段调用微服务的代码: using (var ms = new JMS ...
- Spring的SchedulingConfigurer实现定时任务
前提:在做业务平台的时候我们经常会遇到,某些跟时间打交道的需要修改状态,比如说在时间区间之前,属于未生效状态,区间之内属于有效期,区间之后,属于过期,或者需要每天 每周 每月,甚至是年为单位的做一些固 ...
- MySQL(四)数据备份与还原
数据备份与还原: 备份:将当前已有的数据或者记录保留 还原:将已经保留的数据恢复到对应的表中 为什么要做备份还原: 1.防止数据丢失:被盗.误操作 2.保护数据的记录 数据备份还原的方式很多:数据表备 ...
- 学Python入门应该先学什么?看完本文你就知道了
学Python应先从Python开发基础部分入手:1.如学习Python语言介绍2.环境安装3.Python基本语法4.基本数据类型5.二进制运算6.来流程控制.7.字符编码.文件处理8.数据类型9. ...
- PHP array_unique() 函数
实例 移除数组中重复的值: <?php$a=array("a"=>"red","b"=>"green" ...
- PHP cal_from_jd() 函数
------------恢复内容开始------------ 实例 把儒略日计数转换为格利高里历法的日期: <?php$d=unixtojd(mktime(0,0,0,6,20,2007));p ...