Windows10系统下使用Docker搭建ClickHouse开发环境
前提
随着现在业务开展,几个业务系统的数据量开始急剧膨胀。之前使用了关系型数据库MySQL进行了一次数据仓库的建模,发现了数据量上来后,大量的JOIN操作在提高了云MySQL的配置后依然有点吃不消,加之开发了一个基于关系型数据库设计的标签服务,日全量标签数据(无法避免的笛卡尔积)单表超过5000W。目前采取了基于用户ID分段配合多进程处理的方式暂时延缓了性能的恶化,但是考虑到不远将来,还是需要做一个小型的数据平台。Hadoop的那套体系过于庞大,组件过多,硬件和软件的学习成本比较高,不是一朝一夕可以让小团队的所有成员掌握。考虑到这么多因素的前提下,需要调用ClickHouse这项黑科技,看看使用他能不能突围困局。

软件版本
这里就不对ClickHouse进行简介,其官方网站https://clickhouse.tech有详细的文档。一般使用Windows系统进行开发,如果是Windows10则可以直接安装Docker,利用Hyper-V的特性直接运行ClickHouse的镜像即可。下面列出开发环境搭建需要的软件:
| 软件 | 版本 | 备注 |
|---|---|---|
Windows |
10 |
确保使用了Windows10并且开启了Hyper-V才能使用Docker |
Docker Desktop |
任意 | Docker的Windows桌面版 |
ClickHouse Server |
20.3.x |
直接拉取latest的镜像即可 |
ClickHouse Client |
20.3.x |
直接拉取latest的镜像即可 |
Cmder |
最新版 | 可选,用来代替自带的不好用控制台 |
Windows10下可以通过:控制面板 -> 程序 -> 启用或关闭Windows功能 -> Hyper-V(勾选Hyper-V管理平台和Hyper-V平台,然后重启生效)开启Hyper-V特性:

然后在Docker官方站点的https://www.docker.com/get-started子页面可以找到Docker Desktop的下载入口:

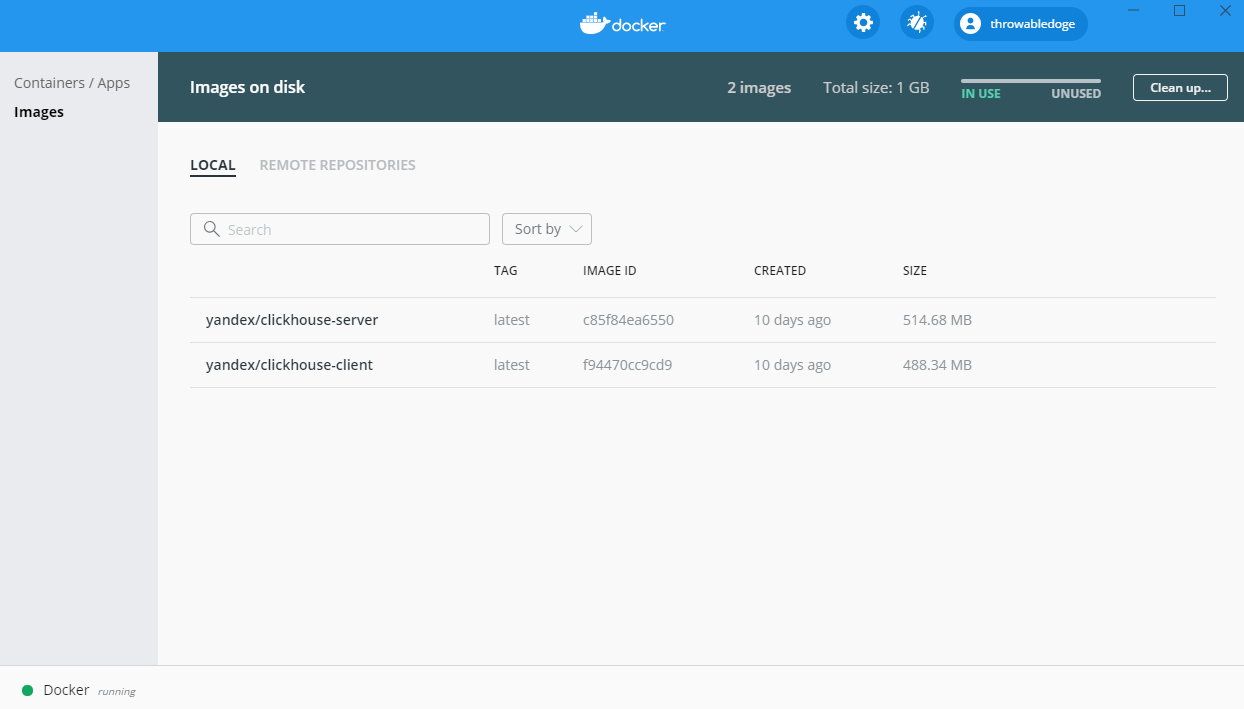
安装完之后Docker Desktop会随着系统自启,软件界面如下:
安装和使用ClickHouse
注意需要先初步了解ClickHouse的核心目录,再进行容器安装启动。
镜像拉取和核心目录
先下载ClickHouse Server和ClickHouse Client的镜像:
docker pull yandex/clickhouse-server
docker pull yandex/clickhouse-client
下载完毕后提示如下:

可以通过docker images验证一下:
λ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
yandex/clickhouse-server latest c85f84ea6550 10 days ago 515MB
yandex/clickhouse-client latest f94470cc9cd9 10 days ago 488MB
两个镜像其实都是包裹在一个微型的Ubuntu系统中,所以启动后的容器可以使用当作是一个Linux系统这样操作。ClickHouse Server在容器中的核心目录部分如下:
/etc/clickhouse-server:这个是ClickHouse Server默认的配置文件目录,包括全局配置config.xml和用户配置users.xml等等。/var/lib/clickhouse:这个是ClickHouse Server默认的数据存储目录。/var/log/clickhouse-server:这个是ClickHouse Server默认的日志输出目录。
为了方便管理配置、查看数据和搜索日志,可以把上面这三个目录直接映射到宿主机的具体目录,笔者在本开发机做了如下的映射:
| Docker容器目录 | 宿主机目录 |
|---|---|
/etc/clickhouse-server |
E:/Docker/images/clickhouse-server/single/conf |
/var/lib/clickhouse |
E:/Docker/images/clickhouse-server/single/data |
/var/log/clickhouse-server |
E:/Docker/images/clickhouse-server/single/log |
ClickHouse Server启动前需要注意几点:
ClickHouse Server服务本身依赖三个端口,这三个端口的默认值是9000(TCP协议)、8123(HTTP协议)和9009(集群数据复制),映射到宿主机的时候尽可能一一对应,所以需要确保宿主机的这三个端口没有被占用,可以使用Docker的参数-p指定容器和宿主机的端口映射。ClickHouse Server正常使用需要修改容器系统的文件句柄数量配置ulimit nofile,可以使用Docker参数--ulimit nofile=262144:262144指定文件句柄数。- 可以运用一个技巧,使用
Docker的--rm参数创建临时容器,先获取到/etc/clickhouse-server目录下配置文件,通过docker cp 容器目录 宿主机目录命令可以拷贝容器的配置文件到宿主机目录下,容器停止之后会被直接删除,这样就能保留宿主机的配置文件模板。
临时容器拷贝配置
先执行命令docker run --rm -d --name=temp-clickhouse-server yandex/clickhouse-server运行一个临时容器,成功后通过下面的命令拷贝容器的config.xml和users.xml文件到宿主机:
docker cp temp-clickhouse-server:/etc/clickhouse-server/config.xml E:/Docker/images/clickhouse-server/single/conf/config.xmldocker cp temp-clickhouse-server:/etc/clickhouse-server/users.xml E:/Docker/images/clickhouse-server/single/conf/users.xml
这两个命令执行完毕后,可以看到宿主机的磁盘目录已经生成了config.xml和users.xml,接着需要做几项配置:
- 创建
default账号的密码。 - 创建一个新的
root账号。 - 开放客户端监听的
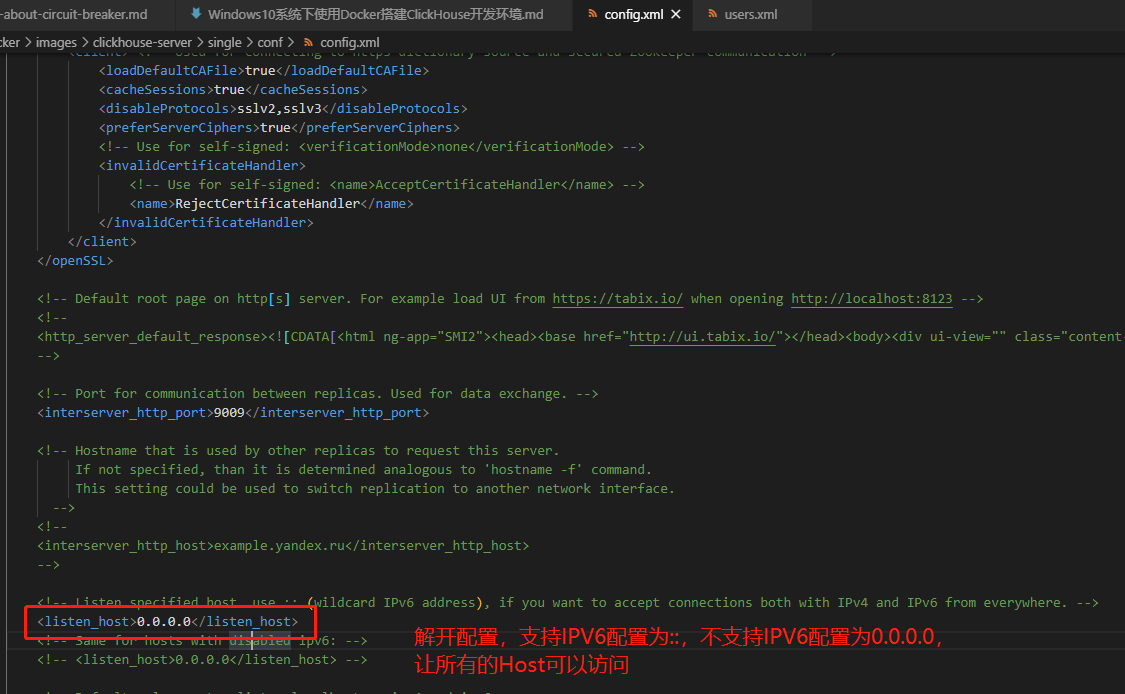
Host,避免后面使用JDBC客户端或者ClickHouse Client的时候无法连接ClickHouse Server。
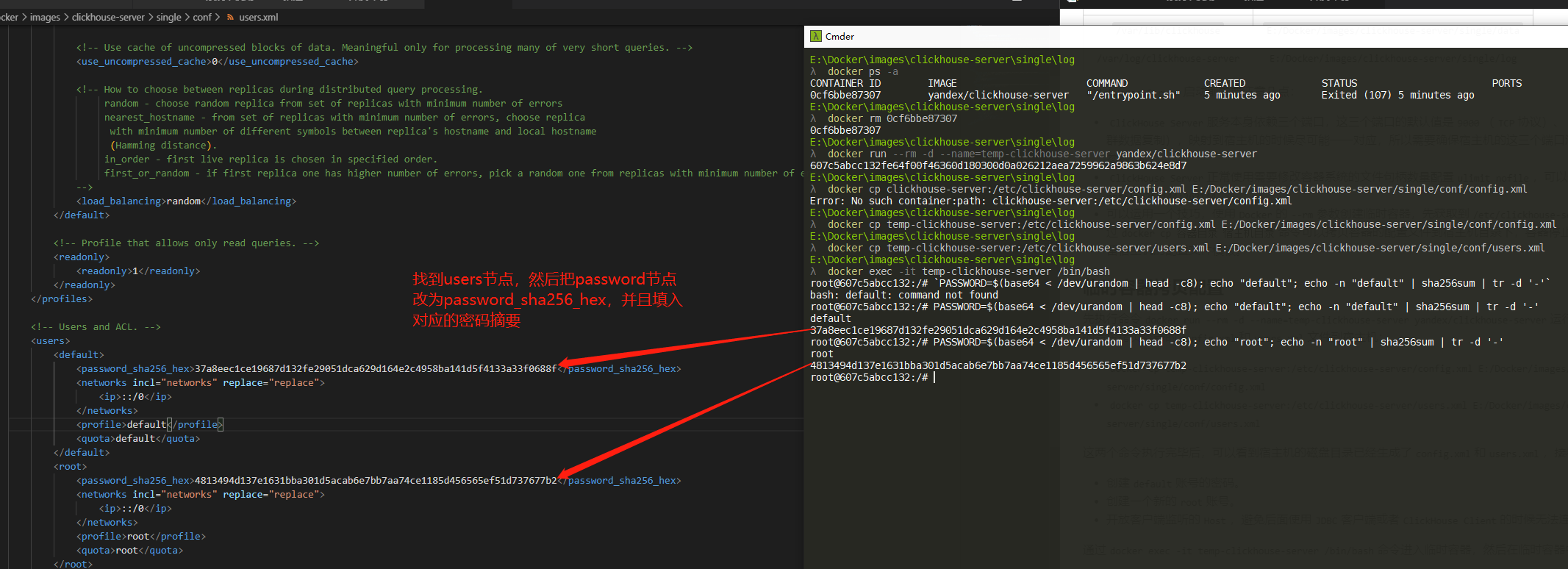
通过docker exec -it temp-clickhouse-server /bin/bash命令进入临时容器,然后在临时容器中执行:
PASSWORD=$(base64 < /dev/urandom | head -c8); echo "default"; echo -n "default" | sha256sum | tr -d '-'PASSWORD=$(base64 < /dev/urandom | head -c8); echo "root"; echo -n "root" | sha256sum | tr -d '-'
root@607c5abcc132:/# PASSWORD=$(base64 < /dev/urandom | head -c8); echo "default"; echo -n "default" | sha256sum | tr -d '-'
default
37a8eec1ce19687d132fe29051dca629d164e2c4958ba141d5f4133a33f0688f
root@607c5abcc132:/# PASSWORD=$(base64 < /dev/urandom | head -c8); echo "root"; echo -n "root" | sha256sum | tr -d '-'
root
4813494d137e1631bba301d5acab6e7bb7aa74ce1185d456565ef51d737677b2
这样就得到了default:default和root:root两个账号密码的SHA256摘要。修改宿主机上的users.xml文件:
然后修改宿主机上的config.xml文件:
最后通过docker stop temp-clickhouse-server停止和销毁临时容器。
运行ClickHouse服务
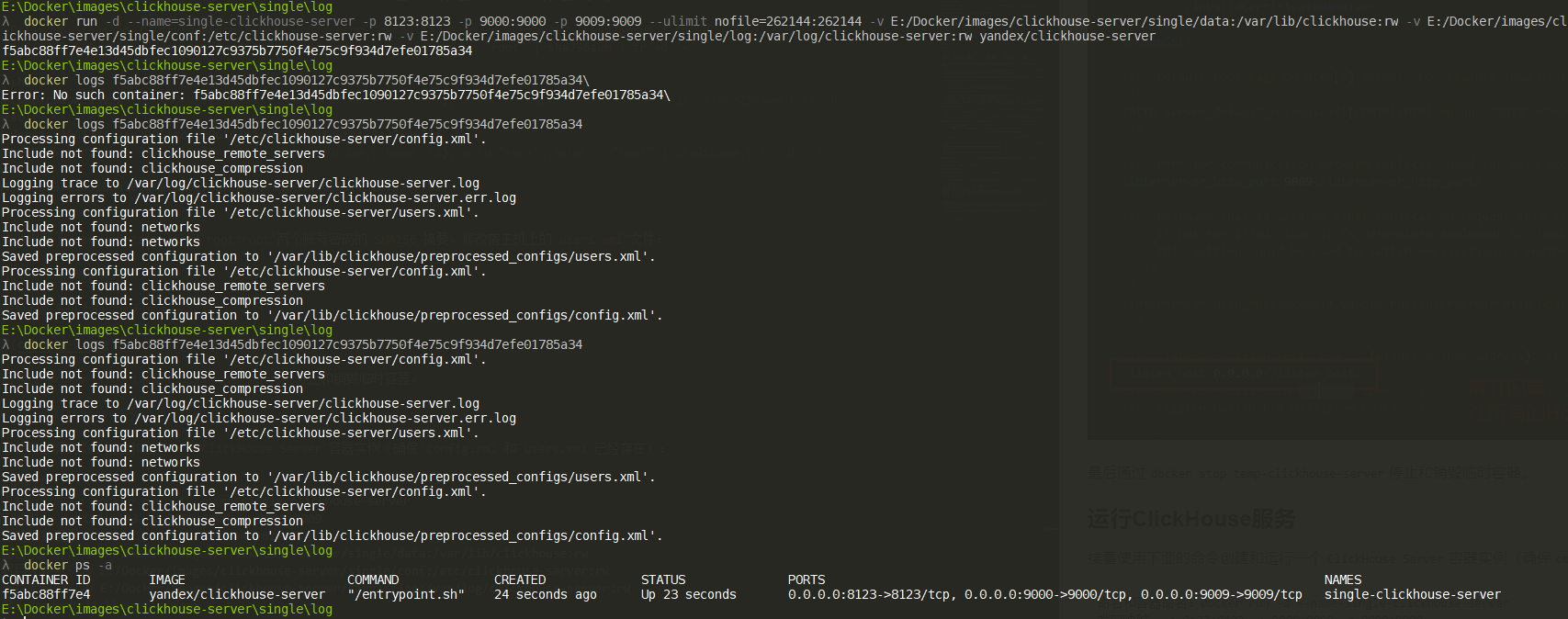
接着使用下面的命令创建和运行一个ClickHouse Server容器实例(确保config.xml和users.xml已经存在):
命名和容器命名:docker run -d --name=single-clickhouse-server
端口映射:-p 8123:8123 -p 9000:9000 -p 9009:9009
文件句柄数配置:--ulimit nofile=262144:262144
数据目录映射:-v E:/Docker/images/clickhouse-server/single/data:/var/lib/clickhouse:rw
配置目录映射:-v E:/Docker/images/clickhouse-server/single/conf:/etc/clickhouse-server:rw
日志目录映射:-v E:/Docker/images/clickhouse-server/single/log:/var/log/clickhouse-server:rw
镜像:yandex/clickhouse-server
上面的命令合成一行执行docker run -d --name=single-clickhouse-server -p 8123:8123 -p 9000:9000 -p 9009:9009 --ulimit nofile=262144:262144 -v E:/Docker/images/clickhouse-server/single/data:/var/lib/clickhouse:rw -v E:/Docker/images/clickhouse-server/single/conf:/etc/clickhouse-server:rw -v E:/Docker/images/clickhouse-server/single/log:/var/log/clickhouse-server:rw yandex/clickhouse-server。
上面的命令执行完后,Docker Desktop会有几个弹出框确认是否共享宿主机的目录,直接按share it按钮即可。
最后使用原生的命令行客户端ClickHouse Client进行连接,使用命令docker run -it --rm --link single-clickhouse-server:clickhouse-server yandex/clickhouse-client -uroot --password root --host clickhouse-server:
λ docker run -it --rm --link single-clickhouse-server:clickhouse-server yandex/clickhouse-client -uroot --password root --host clickhouse-server
ClickHouse client version 20.10.3.30 (official build).
Connecting to clickhouse-server:9000 as user root.
Connected to ClickHouse server version 20.10.3 revision 54441.
f5abc88ff7e4 :) select 1;
SELECT 1
┌─1─┐
│ 1 │
└───┘
1 rows in set. Elapsed: 0.004 sec.
下次如果电脑重启ClickHouse Server的容器没有启动,只需要使用命令docker (re)start single-clickhouse-server拉起容器实例即可。
使用JDBC连接ClickHouse服务
ClickHouse的JDBC驱动目前有三个:
clickhouse-jdbc(官方):地址是https://github.com/ClickHouse/clickhouse-jdbc,目前版本是基于Apache Http Client实现。ClickHouse-Native-JDBC(第三方):地址是https://github.com/housepower/ClickHouse-Native-JDBC,基于Socket实现。clickhouse4j(第三方):地址是https://github.com/blynkkk/clickhouse4j,比官方驱动轻量级。
说实话有点尴尬,官方的驱动包竟然没有对接TCP私有协议栈,而是使用了HTTP协议进行交互,这里不知道性能会下降多少,但是基于"官方更好"的思维这里还是选用官方的驱动包进行Demo演示。引入clickhouse-jdbc依赖:
<dependency>
<groupId>ru.yandex.clickhouse</groupId>
<artifactId>clickhouse-jdbc</artifactId>
<version>0.2.4</version>
</dependency>
编写一个测试类:
public class ClickHouseTest {
@Test
public void testCh() throws Exception {
ClickHouseProperties props = new ClickHouseProperties();
props.setUser("root");
props.setPassword("root");
// 不创建数据库的时候会有有个全局default数据库
ClickHouseDataSource dataSource = new ClickHouseDataSource("jdbc:clickhouse://localhost:8123/default", props);
ClickHouseConnection connection = dataSource.getConnection();
ClickHouseStatement statement = connection.createStatement();
// 创建一张表,表引擎为Memory,这类表在服务重启后会自动删除
boolean execute = statement.execute("CREATE TABLE IF NOT EXISTS t_test(id UInt64,name String) ENGINE = Memory");
if (execute) {
System.out.println("创建表default.t_test成功");
} else {
System.out.println("表default.t_test已经存在");
}
ResultSet rs = statement.executeQuery("SHOW TABLES");
List<String> tables = Lists.newArrayList();
while (rs.next()) {
tables.add(rs.getString(1));
}
System.out.println("default数据库中的表:" + tables);
PreparedStatement ps = connection.prepareStatement("INSERT INTO t_test(*) VALUES (?,?),(?,?)");
ps.setLong(1, 1L);
ps.setString(2, "throwable");
ps.setLong(3, 2L);
ps.setString(4, "doge");
ps.execute();
statement = connection.createStatement();
rs = statement.executeQuery("SELECT * FROM t_test");
while (rs.next()) {
System.out.println(String.format("查询结果,id:%s,name:%s", rs.getLong("id"), rs.getString("name")));
}
}
}
执行结果如下:
表default.t_test已经存在 # <--- 这里估计是驱动包的实现有BUG,首次创建成功返回结果为false
default数据库中的表:[t_test]
查询结果,id:1,name:throwable
查询结果,id:2,name:doge
小结
ClickHouse开发环境初步搭建完毕,后面会开始学习ClickHouse的基本语法、各类引擎的特性和使用场景以及集群搭建(分片和多副本)等等。
参考资料:
https://clickhouse.tech
提醒
这个是笔者在某次直接断电后发现Docker中的ClickHouse服务虽然重启成功,但是错误日志疯狂输出File not found,导致所有客户端无法连接服务。初步判断为元数据和实际存储的数据因为"断电"后造成不一致导致的。所以建议在开发环境中关机前要先进入容器调用service clickhouse-server stop,然后在宿主机调用docker stop 容器名|容器ID停止容器再进行关机,否则需要递归删除数据目录下的store目录中的所有文件才能正常重启ClickHouse Server和使用(这个是十分粗暴的办法,有比较大几率会直接导致数据丢失,一定要谨慎操作)。
(本文完 c-2-d e-a-20201108 开始搞小数据)
个人博客
Windows10系统下使用Docker搭建ClickHouse开发环境的更多相关文章
- Windows系统下Eclipse上搭建Python开发环境
参考网站: https://blog.csdn.net/zhangphil/article/details/78962159 1.先安装JDK 和python,参考网站:https://www.c ...
- Windows系统上搭建Clickhouse开发环境
Windows系统上搭建Clickhouse开发环境 总体思路 微软的开发IDE是很棒的,有两种:Visual Studio 和 VS Code,一个重量级,一个轻量级.近年来VS Code越来越受欢 ...
- Docker最全教程之使用Docker搭建Java开发环境(十七)
前言 Java是一门面向对象的优秀编程语言,市场占有率极高,但是在容器化实践过程中,发现官方支持并不友好,同时与其他编程语言的基础镜像相比(具体见各语言镜像比较),确实是非常臃肿. 本篇仅作探索,希望 ...
- 【Hadoop】:Windows下使用IDEA搭建Hadoop开发环境
笔者鼓弄了两个星期,终于把所有有关hadoop的环境配置好了,一是虚拟机上的完全分布式集群,但是为了平时写代码的方便,则在windows上也配置了hadoop的伪分布式集群,同时在IDEA上就可以编写 ...
- Windows系统 为 QT5软件 搭建 OpenCV2 开发环境
Windows系统 为 QT5软件 搭建 OpenCV2 开发环境 我们的电脑系统:Windows 10 64位 Qt5 软件:Qt 5. 7. 0 OpenCV2 版本:OpenCV2.4.10 1 ...
- mac 下 用 glfw3 搭建opengl开发环境
mac 下 用 glfw3 搭建opengl开发环境 下载编译 glfw3 Build Setting 里面, Library Search Paths -> 设置好编译 glfw 库的路径 H ...
- (转)Lua学习笔记1:Windows7下使用VS2015搭建Lua开发环境
Lua学习笔记1:Windows7下使用VS2015搭建Lua开发环境(一)注意:工程必须添加两个宏:“配置属性”/“C或C++”/“预处理器”/“预处理器定义”,添加两个宏:_CRT_SECURE_ ...
- 在windows环境里,用Docker搭建Redis开发环境(新书第一个章节)
大家都知道高并发分布式组件的重要性,而且如果要进大厂,这些技术不可或缺.但这些技术的学习难点在于,大多数项目里的分布式组件,都是搭建在Linux系统上,在自己的windows机器上很难搭建开发环境,如 ...
- Win7系统下,docker构建nginx+php7环境实践
前面两章介绍的是Windows系统下如何安装和配置docker,主要原因在于,公司大多人数用的是Windows环境,想通过在Windows环境上,通过docker,构建一个公用的配置. 首先要说明的是 ...
随机推荐
- centos8平台使用wkhtmltopdf实现html网页转pdf
一,wkhtmltopdf的用途 wkhtmltopdf可以直接把任何一个可以在浏览器中浏览的网页直接转换成一个pdf 说明:刘宏缔的架构森林是一个专注架构的博客,地址:https://www.cnb ...
- html的keywords标签
<link rel="shortcut icon" href="favicon.ico" type="image/x-icon" /& ...
- GoogleHacking基本语法使用
查看网络后台 intitle:admin 搜索url中的关键字:asp?id= inurl:asp?id=
- C# 将dataset数据导出到excel中
//添加引用 NPOI.dll //添加 using NPOI.HSSF.UserModel; /// <summary> /// 导出数据到Excel /// </summary& ...
- 判断是否是胖子的shell脚本
read -p "请输入身高(m为单位): " HIGH if [[ ! "$HIGH" =~ [1].?[0-9]{,2}$ ]];then echo &qu ...
- centos7启用EPEL Repository
1,下载库文件 http://dl.fedoraproject.org/pub/epel/7/x86_64/Packages/e/epel-release-7-11.noarch.rpm 2,安装 r ...
- OLTP与OLAP的介绍(理论知识)
OLTP与OLAP的介绍 数据处理大致可以分成两大类:联机事务处理OLTP(on-line transaction processing).联机分析处理OLAP(On-Line Analytical ...
- A. Arena of Greed 解析(思維)
Codeforce 1425 A. Arena of Greed 解析(思維) 今天我們來看看CF1425A 題目連結 題目 略,請直接看原題. 前言 明明是難度1400的題目,但總感覺不是很好寫阿, ...
- liunx命令的运用
工作中用到了一些命令,记忆才深刻 1.查看服务器内存:free -h 2.查看服务器磁盘空间:df -h 3.切root用户:sudo su root 输入密码 4.查看liunx服务器下的所有用户: ...
- eclipse配置springMVC
基础还是创建一个Dynamic web project. WEB-INF/lib中添加必需的jar. commons-logging-1.1.3.jar spring-aop-4.3.6.RELEAS ...