Spark Job-Stage-Task实例理解
Spark Job-Stage-Task实例理解
基于一个word count的简单例子理解Job、Stage、Task的关系,以及各自产生的方式和对并行、分区等的联系;
相关概念
- Job:Job是由Action触发的,因此一个Job包含一个Action和N个Transform操作;
- Stage:Stage是由于shuffle操作而进行划分的Task集合,Stage的划分是根据其宽窄依赖关系;
- Task:最小执行单元,因为每个Task只是负责一个分区的数据
处理,因此一般有多少个分区就有多少个Task,这一类的Task其实是在不同的分区上执行一样的动作;
例子代码
'''
DAG: Job vs Stage vs Task
'''
# 初始化spark环境
from pyspark import SparkContext,SparkConf
conf = SparkConf()
conf.setMaster('local').setAppName('Job vs Stage vs Task')
sc = SparkContext(conf=conf)
alpha_rdd1 = sc.parallelize(['a c','a b','b c','b d','c d'],10)
word_count1 = alpha_rdd1.flatMap(lambda a:a.split(' ')).map(lambda a:(a,1)).reduceByKey(lambda x,y:x+y)
alpha_rdd2 = sc.parallelize(['a c','a b','b c','b d','c d'],10)
word_count2 = alpha_rdd2.flatMap(lambda a:a.split(' ')).map(lambda a:(a,1)).reduceByKey(lambda x,y:x+y)
word_count1.join(word_count2).collect()
print('END')
input() # input是方便脚本运行不会终止导致web ui不能正常浏览
可以看到,主要的数据处理逻辑分为三部分,分别是两个word count,以及最后对两个结果的join,事实上这也对应了3个stage,下面是代码与stage的对应图,注意图中的并行关系:
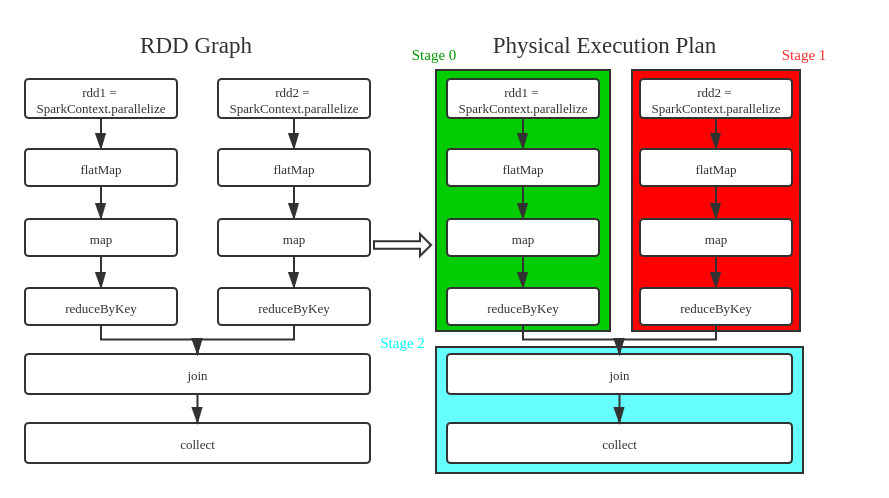
从图中可以看出,原代码只有一个action(collect),因此只有一个Job,这个Job被换分为3个Stage,划分原因是有shuffle出现(reductByKey),而明显看出的是Stage 0和Stage 1互相没有依赖关系,因此可以并行,而Stage 2则是依赖于0和1的,因此会最后一个执行;
Spark Web UI
下面通过Web UI来进一步查看Job、Stage、Task的关系;

从上图看到,只有一个已完成的Job,该Job包含3个Stage,30个Task(注意之前的代码里parallelize设置的分区数为10,3*10=30);

上图表示该Job的运行时间线图,可以明显的看到Stage0和Stage1在时间上有大部分重叠,也就是并行进行,而Stage2是在Stage1结束后才开始,因为Stage0结束的更早,这里对于依赖关系的展示还是很明显的;
另外,对于stage0和stage1,虽然处理的数据量很小,但是依然可以看出二者的运行时间比较接近,也就是没有明显的数据偏斜的情况出现,当然,这里因为只是测试数据,而真实场景下很容易出现个别stage执行时间远远超过其他的stage,导致整体的时间被拖长;

上图是该Job对应的DAG可视化图,它是直接的对Stage以及Stage间的依赖关系进行展示,也验证了我们之前的分析,这里每个Stage还可以继续点进去;

上图中可以更清晰的看到,每个Stage中都包含10个Task,其实就是对应10个partition,对于Stage0和Stage1,他们都是在shuffle前的Stage,因此他们都有Shuffle Write的动作,大小都是514,而Stage2则是join这两部分数据,因此有Shuffle Read动作,大小而前二者之和,也就是1028;
Spark Job-Stage-Task实例理解的更多相关文章
- Spark分区数、task数目、core数目、worker节点数目、executor数目梳理
Spark分区数.task数目.core数目.worker节点数目.executor数目梳理 spark隐式创建由操作组成的逻辑上的有向无环图.驱动器执行时,它会把这个逻辑图转换为物理执行计划,然后将 ...
- 【原】Spark中Stage的提交源码解读
版权声明:本文为原创文章,未经允许不得转载. 复习内容: Spark中Job如何划分为Stage http://www.cnblogs.com/yourarebest/p/5342424.html 1 ...
- 大话Spark(3)-一图深入理解WordCount程序在Spark中的执行过程
本文以WordCount为例, 画图说明spark程序的执行过程 WordCount就是统计一段数据中每个单词出现的次数, 例如hello spark hello you 这段文本中hello出现2次 ...
- 【Spark】Stage生成和Stage源代码浅析
引入 上一篇文章<DAGScheduler源代码浅析>中,介绍了handleJobSubmitted函数,它作为生成finalStage的重要函数存在.这一篇文章中,我将就DAGSched ...
- spark 笔记 9: Task/TaskContext
DAGScheduler最终创建了task set,并提交给了taskScheduler.那先得看看task是怎么定义和执行的. Task是execution执行的一个单元. Task: execut ...
- 【C# Task】理解Task中的ConfigureAwait配置同步上下文
原文:https://devblogs.microsoft.com/dotnet/configureawait-faq/ 作者:Stephen 翻译:xiaoxiaotank 静下心来,你一定会有收获 ...
- Spark Streaming揭秘 Day29 深入理解Spark2.x中的Structured Streaming
Spark Streaming揭秘 Day29 深入理解Spark2.x中的Structured Streaming 在Spark2.x中,Spark Streaming获得了比较全面的升级,称为St ...
- 通过实例理解 RabbitMQ 的基本概念
先说下自己开发的实例. 最近在使用 Spring Cloud Config 做分布式配置中心(基于 SVN/Git),当所有服务启动后,SVN/Git 中的配置文件更改后,客户端服务读取的还是旧的配置 ...
- [学习笔记]一个实例理解Lingo的灵敏性分析
一个实例理解Lingo的灵敏性分析 线性规划问题的三个重要概念: 最优解就是反应取得最优值的决策变量所对应的向量. 最优基就是最优单纯形表的基本变量所对应的系数矩阵如果其行列式是非 ...
随机推荐
- JavaScript学习系列博客_32_JavaScript 包装类
包装类 - 在JS中为我们提供了三个包装类: String() Boolean() Number() - 通过这三个包装类可以创建基本数据类型的对象 例子: var num = new Number( ...
- 12c RAC 用Rman 恢复到异机单实例
准备工作 原服务器软件部署:Redhat 6.6 + Oracle 12.2.0.1 rac Oracle12c单实例安装 1.创建恢复服务器,设置大于原库数据大小的磁盘容量.设置相同的服务器主机名参 ...
- muduo源码解析1-timestamp类
timestamp class timestamp:public mymuduo::copyable, public boost::equality_comparable<timestamp&g ...
- JVM大作业5——指令集
JVM的每一个线程都有一个虚拟机栈,方法调用时,JVM会在虚拟机栈内为该方法创建一个栈帧. 一条线程,只有正在执行的方法对应的栈帧时可活动的,这个栈帧被称为当前栈帧,当前栈帧对应的方法被称为当前方法, ...
- HttpWatch汉化版带详细的使用教程下载
http://www.wocaoseo.com/thread-303-1-1.html HttpWatch是强大的网页数据分析工具.集成在Internet Explorer工具栏.包括网页摘要.Coo ...
- Angular 之我见
很久没有写过技术软文了,虽然 Angular 发布已有四年,得到了越来越多人的关注,但是仍然有很多人不分青红皂白的进行诋毁.我打算结合自己的经历从客观的角度说聊一聊我眼中的 Angular. 本人刚做 ...
- vue前端获取env中的常量
process.env.常量名 如:process.env.MIX_APP_URL
- iOS NSOperation
iOS NSOperation 一.简介 除了,NSThread和GCD实现多线程,配合使用NSOperation和NSOperationQueue也能实现多线程编程 NSOperation和NSOp ...
- Spine学习八 - 幻影特效
Spine支持一些自带的特效,这些特效,不需要在spine中制作,而只是通过在unity中添加一些脚本便可实现. 这里先讲解一个比较使用又酷炫的效果,幻影特效: 1. 首先,在SkeletonAnim ...
- java中equals与hashCode的重写问题
这几天有一个朋友问我在重写equals和hashCode上出现了问题,最后我帮她解决了问题,同时也整理出来分享给大家 现上Object的equals与HashCode的代码 public boolea ...