Python之人工智能:PyAudio 实现录音 自动化交互实现问答
Python 很强大其原因就是因为它庞大的三方库 , 资源是非常的丰富 , 当然也不会缺少关于音频的库
关于音频, PyAudio 这个库, 可以实现开启麦克风录音, 可以播放音频文件等等,此刻我们不去了解其他的功能,只了解一下它如何实现录音的
首先要先 pip 一个 PyAudio
pip install pyaudio
一.PyAudio 实现麦克风录音
然后建立一个py文件,复制如下代码
import pyaudio
import wave CHUNK = 1024
FORMAT = pyaudio.paInt16
CHANNELS = 2
RATE = 16000
RECORD_SECONDS = 2
WAVE_OUTPUT_FILENAME = "Oldboy.wav" p = pyaudio.PyAudio() stream = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=CHUNK) print("开始录音,请说话......") frames = [] for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)):
data = stream.read(CHUNK)
frames.append(data) print("录音结束,请闭嘴!") stream.stop_stream()
stream.close()
p.terminate() wf = wave.open(WAVE_OUTPUT_FILENAME, 'wb')
wf.setnchannels(CHANNELS)
wf.setsampwidth(p.get_sample_size(FORMAT))
wf.setframerate(RATE)
wf.writeframes(b''.join(frames))
wf.close()
尝试一下,在目录中出现了一个 Oldboy.wav 文件 , 听一听,还是很清晰的嘛
接下来,我们将这段录音代码,写在一个函数里面,如果要录音的话就调用
建立一个文件 pyrec.py 并将录音代码和函数写在内
import pyaudio
import wave CHUNK = 1024
FORMAT = pyaudio.paInt16
CHANNELS = 2
RATE = 16000
RECORD_SECONDS = 2 def rec(file_name):
p = pyaudio.PyAudio() stream = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=CHUNK) print("开始录音,请说话......") frames = [] for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)):
data = stream.read(CHUNK)
frames.append(data) print("录音结束,请闭嘴!") stream.stop_stream()
stream.close()
p.terminate() wf = wave.open(file_name, 'wb')
wf.setnchannels(CHANNELS)
wf.setsampwidth(p.get_sample_size(FORMAT))
wf.setframerate(RATE)
wf.writeframes(b''.join(frames))
wf.close()
rec 函数就是我们调用的录音函数,并且给他一个文件名,他就会自动将声音写入到文件中了
二.实现音频格式自动转换 并 调用语音识别
录音的问题解决了,赶快和百度语音识别接在一起使用一下:
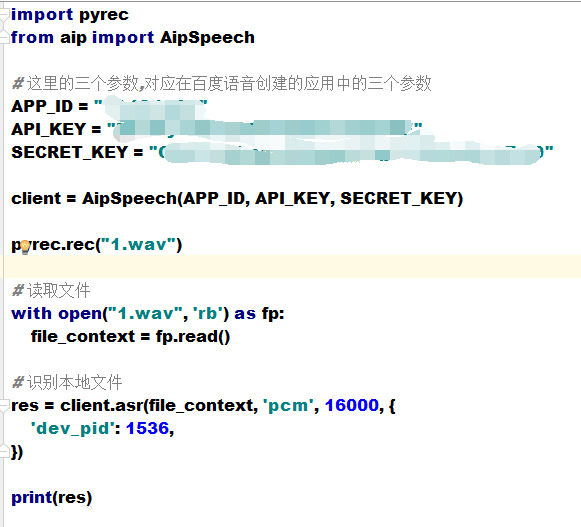
不管你的录音有多么多么清晰,你发现百度给你返回的永远是:
{'err_msg': 'speech quality error.', 'err_no': 3301, 'sn': '6397933501529645284'} # 音质不清晰
其实不是没听清,而是百度支持的音频格式PCM搞的鬼
所以,我们要将录制的wav音频文件转换为pcm文件
写一个文件 wav2pcm.py 这个文件里面的函数是专门为我们转换wav文件的
使用 os 模块中的 os.system()方法 这个方法是执行系统命令用的, 在windows系统中的命令就是 cmd 里面写的东西,dir , cd 这类的命令
# wav2pcm.py 文件内容
import os def wav_to_pcm(wav_file):
# 假设 wav_file = "音频文件.wav"
# wav_file.split(".") 得到["音频文件","wav"] 拿出第一个结果"音频文件" 与 ".pcm" 拼接 等到结果 "音频文件.pcm"
pcm_file = "%s.pcm" %(wav_file.split(".")[0]) # 就是此前我们在cmd窗口中输入命令,这里面就是在让Python帮我们在cmd中执行命令
os.system("ffmpeg -y -i %s -acodec pcm_s16le -f s16le -ac 1 -ar 16000 %s"%(wav_file,pcm_file)) return pcm_file
这样我们就有了把wav转为pcm的函数了 , 再重新构建一次咱们的代码
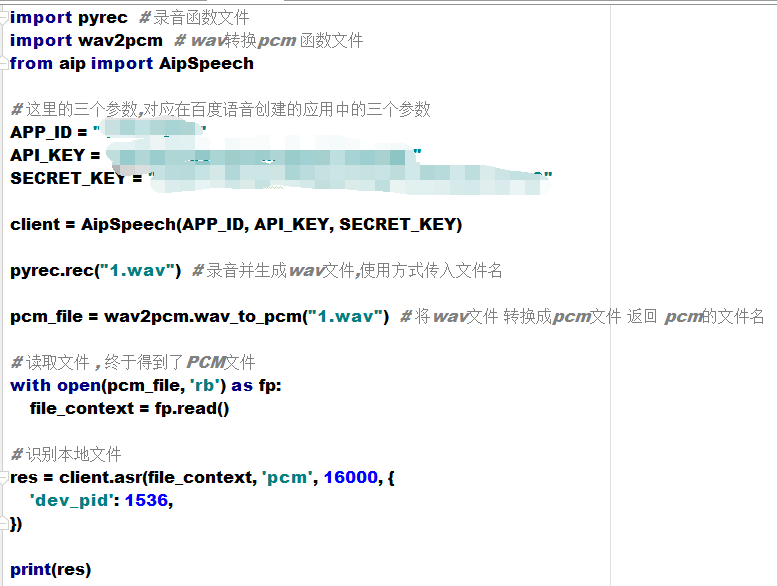
这次的返回结果还挺让人满意的嘛
{'corpus_no': '6569869134617218414', 'err_msg': 'success.', 'err_no': 0, 'result': ['你好'], 'sn': '8116162981529666859'}
拿到语音识别的字符串了,接下来用这段字符串 语音合成, 学习咱们说出来的话
三.语音合成 与 FFmpeg 播放mp3 文件
拿到字符串了,直接调用synthesis方法去合成吧

这段代码衔接上一段代码,成功获得了 synth.mp3 音频文件,并且确定了实在学习我们说的话
接下来就是让我们的程序自动将 synth.mp3 音频文件播放了 其实PyAudio 有播放的功能,但是操作有点复杂
所以我们还是选择用简单的方式解决复杂的问题,就是这么简单粗暴,是否还记得FFmpeg 呢?
FFmpeg 这个系统工具中,有一个 ffplay 的工具用来打开并播放音频文件的,使用方法大概是: ffplay 音频文件.mp3
建立一个playmp3.py文件, 写一个 play_mp3 的函数用来播放已经合成的语音
# playmp3.py 文件内容
import os def play_mp3(file_name):
os.system("ffplay %s"%(file_name))
回到主文件,调用playmp3.py文件中的 play_mp3 函数

执行代码,当你看到 : 开始录音,请说话......
请大声的说出: 学IT 找老男孩教育
然后你就会听到,一个娇滴滴声音重复你说的话
四.简单问答
首先我们要把代码重新梳理一下:
把语音合成 语音识别部分的代码独立成函数放到baidu_ai.py文件中
# baidu_ai.py 文件内容
from aip import AipSpeech # 这里的三个参数,对应在百度语音创建的应用中的三个参数
APP_ID = "xxxxx"
API_KEY = "xxxxxxx"
SECRET_KEY = "xxxxxxxx" client = AipSpeech(APP_ID, API_KEY, SECRET_KEY) def audio_to_text(pcm_file):
# 读取文件 , 终于得到了PCM文件
with open(pcm_file, 'rb') as fp:
file_context = fp.read() # 识别本地文件
res = client.asr(file_context, 'pcm', 16000, {
'dev_pid': 1536,
}) # 从字典里面获取"result"的value 列表中第1个元素,就是识别出来的字符串"老男孩教育"
res_str = res.get("result")[0] return res_str def text_to_audio(res_str):
synth_file = "synth.mp3"
synth_context = client.synthesis(res_str, "zh", 1, {
"vol": 5,
"spd": 4,
"pit": 9,
"per": 4
}) with open(synth_file, "wb") as f:
f.write(synth_context) return synth_file
然后把我们的主文件进行一下修改
import pyrec # 录音函数文件
import wav2pcm # wav转换pcm 函数文件
import baidu_ai # 语音合成函数,语音识别函数 文件
import playmp3 # 播放mp3 函数 文件 pyrec.rec("1.wav") # 录音并生成wav文件,使用方式传入文件名 pcm_file = wav2pcm.wav_to_pcm("1.wav") # 将wav文件 转换成pcm文件 返回 pcm的文件名 res_str = baidu_ai.audio_to_text(pcm_file) # 将转换后的pcm音频文件识别成 文字 res_str synth_file = baidu_ai.text_to_audio(res_str) # 将res_str 字符串 合成语音 返回文件名 synth_file playmp3.play_mp3(synth_file) # 播放 synth_file
然后就是大展宏图的时候了,展开你们的想象力:
res_str 是字符串,如果字符串等于"你叫什么名字"的时候,我们就要给他一个回答:我的名字叫老男孩教育
新建一个FAQ.py的文件然后建立一个函数faq:
# FAQ.py 文件内容
def faq(Q):
if Q == "你叫什么名字": # 问题
return "我的名字是老男孩教育" # 答案 return "我不知道你在说什么" #问题没有答案时返
在主文件中导入这个函数,并将语音识别后的字符串传入函数中

现在来尝试一下:"你叫什么名字","你今年几岁了"
成功了,现在你可以对 FAQ.py 这个文件进行更多的问题匹配了
还是那句话,别玩儿坏了
Python之人工智能:PyAudio 实现录音 自动化交互实现问答的更多相关文章
- Python人工智能之路 - 第三篇 : PyAudio 实现录音 自动化交互实现问答
Python 很强大其原因就是因为它庞大的三方库 , 资源是非常的丰富 , 当然也不会缺少关于音频的库 关于音频, PyAudio 这个库, 可以实现开启麦克风录音, 可以播放音频文件等等,此刻我们不 ...
- 2,PyAudio 实现录音 自动化交互实现问答
Python 很强大其原因就是因为它庞大的三方库 , 资源是非常的丰富 , 当然也不会缺少关于音频的库 关于音频, PyAudio 这个库, 可以实现开启麦克风录音, 可以播放音频文件等等,此刻我们不 ...
- PyAudio 实现录音 自动化交互实现问答
Python 很强大其原因就是因为它庞大的三方库 , 资源是非常的丰富 , 当然也不会缺少关于音频的库 关于音频, PyAudio 这个库, 可以实现开启麦克风录音, 可以播放音频文件等等,此刻我们不 ...
- python 全栈开发,Day123(图灵机器人,web录音实现自动化交互问答)
昨日内容回顾 . 百度ai开放平台 . AipSpeech技术,语言合成,语言识别 . Nlp技术,短文本相似度 . 实现一个简单的问答机器人 . 语言识别 ffmpeg (目前所有音乐,视频领域,这 ...
- 图灵机器人,web录音实现自动化交互问答
一.图灵机器人 介绍 图灵机器人 是以语义技术为核心驱动力的人工智能公司,致力于“让机器理解世界”,产品服务包括机器人开放平台.机器人OS和场景方案. 官方地址为: http://www.tuling ...
- 『开发技巧』Python音频操作工具PyAudio上手教程
『开发技巧』Python音频操作工具PyAudio上手教程 0.引子 当需要使用Python处理音频数据时,使用python读取与播放声音必不可少,下面介绍一个好用的处理音频PyAudio工具包. ...
- python数据处理(九)之自动化与规模化
1 前沿 1.1 适合自动化的任务 每周二输出一些新的分析结果,编制一份报告,并发送给相关方 其他部门或同事需要能够在没有你的指导和支持下运行报告工具和清洗工具 每周进行一次数据下载.清洗和发送 每次 ...
- 使用expect的自动化交互
Q:利用shell脚本实现ssh自动登录远程服务器? A:expect命令 #!/usr/bin/expect spawn ssh root@172.16.11.99 expect "*pa ...
- Python搭建Web服务器,与Ajax交互,接收处理Get和Post请求的简易结构
用python搭建web服务器,与ajax交互,接收处理Get和Post请求:简单实用,没有用框架,适用于简单需求,更多功能可进行扩展. python有自带模块BaseHTTPServer.CGIHT ...
随机推荐
- HDU4624 Endless Spin(概率&&dp)
2013年多校的题目,那个时候不太懂怎么做,最近重新拾起来,看了一下出题人当初的解题报告,再结合一下各种情况的理解,终于知道整个大致的做法,这里具体写一下做法. 题意:给你一段长度为[1..n]的白色 ...
- 从100PV到1亿级PV网站架构演变(转)
http://www.linuxde.net/2013/05/13581.html 一个网站就像一个人,存在一个从小到大的过程.养一个网站和养一个人一样,不同时期需要不同的方法,不同的方法下有共同的原 ...
- P2389 电脑班的裁员
题意:长度为n的序列,选出k个连续的字段,使和最大(有负数) 暴力只选正数且不考虑k的边界问题50(数据...) 正解从$O(n^3)到O(n)$不等,($O(n)$不会) DP 1.$O(n^3)$ ...
- php 顺序线性表
<?php /* * 线性顺序表 ,其是按照顺序在内存进行存储,出起始和结尾以外都是一一连接的(一般都是用一维数组的形式表现) * * GetElem: 返回线性表中第$index个数据元素 * ...
- 阿里云服务器部署Tornado应用指南
本篇详细介绍tornado应用部署到阿里云服务器上的全过程. Tornado程序地址:github https://github.com/ddong8/ihasy.git 准备工作:阿里云服务器Cen ...
- Codeforces-Salem and Sticks(枚举+思维)
Salem gave you nn sticks with integer positive lengths a1,a2,-,ana1,a2,-,an. For every stick, you ca ...
- Java高级工程师应该掌握的东东
今天偶然看了膜拜单车官网对java程序员的招聘要求,如下,可以对照发现自己的不足 职责 负责APP SERVER中间层等模块开发 完成各类需求开发任务,同时保证服务稳定性.茁壮性 要求 精通Java语 ...
- CROSS APPLY和 OUTER APPLY 区别详解
SQL Server 2005 新增 cross apply 和 outer apply 联接语句,增加这两个东东有啥作用呢? 我们知道有个 SQL Server 2000 中有个 cross joi ...
- hive参数设置
-- 设置hive的计算引擎为spark set hive.execution.engine=spark; -- 修复分区 set hive.msck.path.validation=ignore; ...
- RequireJS -Javascript模块化(一、简介)
1.认识RequireJS RequireJs官网(http://requirejs.org/)的描述: RequireJS is a JavaScript file and module loade ...