ElasticSearch 结构化搜索
1、介绍
结构化搜索(Structured search) 是指有关探询那些具有内在结构数据的过程。比如日期、时间和数字都是结构化的:它们有精确的格式,我们可以对这些格式进行逻辑操作。
比较常见的操作包括比较数字或时间的范围,或判定两个值的大小。
文本也可以是结构化的。如彩色笔可以有离散的颜色集合: 红(red) 、 绿(green) 、 蓝(blue) 。一个博客可能被标记了关键词 分布式(distributed) 和 搜索(search) 。
电商网站上的商品都有 UPCs(通用产品码 Universal Product Codes)或其他的唯一标识,它们都需要遵从严格规定的、结构化的格式。
在结构化查询中,我们得到的结果 总是 非是即否,要么存于集合之中,要么存在集合之外。结构化查询不关心文件的相关度或评分;它简单的对文档包括或排除处理。
这在逻辑上是能说通的,因为一个数字不能比其他数字 更 适合存于某个相同范围。结果只能是:存于范围之中,抑或反之。同样,对于结构化文本来说,一个值要么相等,要么不等。没有 更似 这种概念。
当进行精确值查找时, 要使用过滤器(filters)。过滤器很重要,因为它们执行速度非常快,不会计算相关度(直接跳过了整个评分阶段)而且很容易被缓存,因此尽可能多的使用过滤式查询。
2、term查询数字
最为常用的 term 查询, 可以用它处理数字(numbers)、布尔值(Booleans)、日期(dates)以及文本(text)
创建并索引一些表示产品的文档,文档里有字段 `price` 和 `productID` ( `价格` 和 `产品ID` ):
POST /my_store/products/_bulk
{ "index": { "_id": 1 }}
{ "price" : 10, "productID" : "XHDK-A-1293-#fJ3" }
{ "index": { "_id": 2 }}
{ "price" : 20, "productID" : "KDKE-B-9947-#kL5" }
{ "index": { "_id": 3 }}
{ "price" : 30, "productID" : "JODL-X-1937-#pV7" }
{ "index": { "_id": 4 }}
{ "price" : 30, "productID" : "QQPX-R-3956-#aD8" }
通常当查找一个精确值的时候,我们不希望对查询进行评分计算。只希望对文档进行包括或排除的计算,所以我们会使用 constant_score 查询以非评分模式来执行 term 查询并以一作为统一评分。
最终组合的结果是一个 constant_score 查询,它包含一个 term 查询:
GET /my_store/products/_search
{
"query" : {
"constant_score" : {
"filter" : {
"term" : {
"price" : 10
}
}
}
}
}
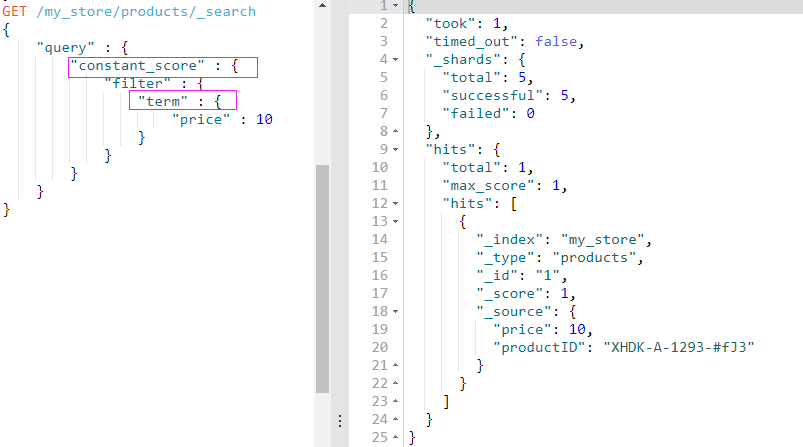
我们用 constant_score 将 term 查询转化成为过滤器,这个查询所搜索到的结果与我们期望的一致:只有文档 1 命中并作为结果返回(因为只有 1 的价格是 10)
3、term查询文本
使用 term 查询匹配字符串和匹配数字一样容易。例如查询产品号是XHDK-A-1293-#fJ3 的数据,也就是查询文档1
GET /my_store/products/_search
{
"query" : {
"constant_score" : {
"filter" : {
"term" : {
"productID" : "XHDK-A-1293-#fJ3"
}
}
}
}
}

显然没有查询到想要的结果,为什么呢?问题不在 term 查询,而在于索引数据的方式,先查看productID的索引方式
GET /my_store/_analyze
{
"field": "productID",
"text": "XHDK-A-1293-#fJ3"
}
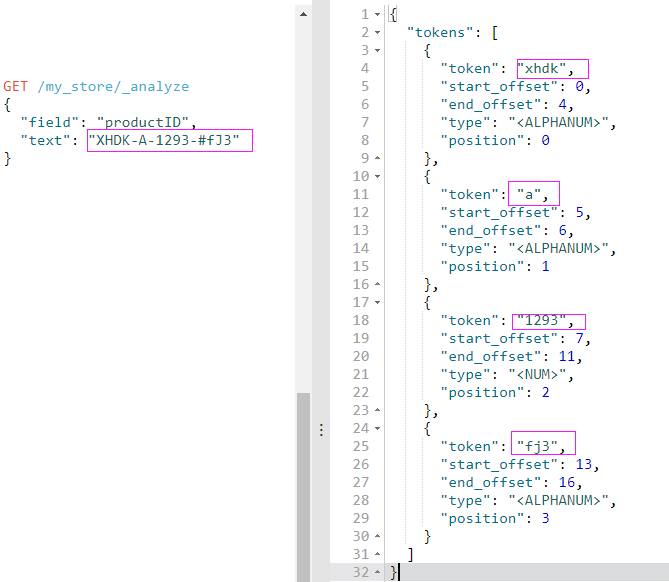
通过上面的结果,可以看到"XHDK-A-1293-#fJ3"这个数据被分成了四个部分,所以当我们用 term 查询查找精确值 XHDK-A-1293-#fJ3 的时候,找不到任何文档,因为它并不在我们的倒排索引中,
显然这种对 ID 码或其他任何精确值的处理方式并不是我们想要的。
为了避免这种问题,我们需要告诉 Elasticsearch 该字段具有精确值,要将其设置成 not_analyzed 无需分析的。
DELETE /my_store PUT /my_store
{
"mappings" : {
"products" : {
"properties" : {
"productID" : {
"type" : "string",
"index" : "not_analyzed"
}
}
}
} }

注意:对Elastic 5.5版本以后的,string被text代替了,不过string还能用,而index对应的值是true或false。对应string类型的数据而言,not_analyzed这个数据还可以用,但是针对string类型数据,其它类型的数据不行。
删除索引是必须的,因为我们不能更新已存在的映射。
在索引被删除后,我们可以创建新的索引并为其指定自定义映射。
这里我们告诉 Elasticsearch ,我们不想对 productID 做任何分析。
现在我们可以为文档重建索引:
POST /my_store/products/_bulk
{ "index": { "_id": 1 }}
{ "price" : 10, "productID" : "XHDK-A-1293-#fJ3" }
{ "index": { "_id": 2 }}
{ "price" : 20, "productID" : "KDKE-B-9947-#kL5" }
{ "index": { "_id": 3 }}
{ "price" : 30, "productID" : "JODL-X-1937-#pV7" }
{ "index": { "_id": 4 }}
{ "price" : 30, "productID" : "QQPX-R-3956-#aD8" }
再次查看productID的索引方式:

显然XHDK-A-1293-#fJ3数据没有被分析
重新查询产品号是XHDK-A-1293-#fJ3 的数据
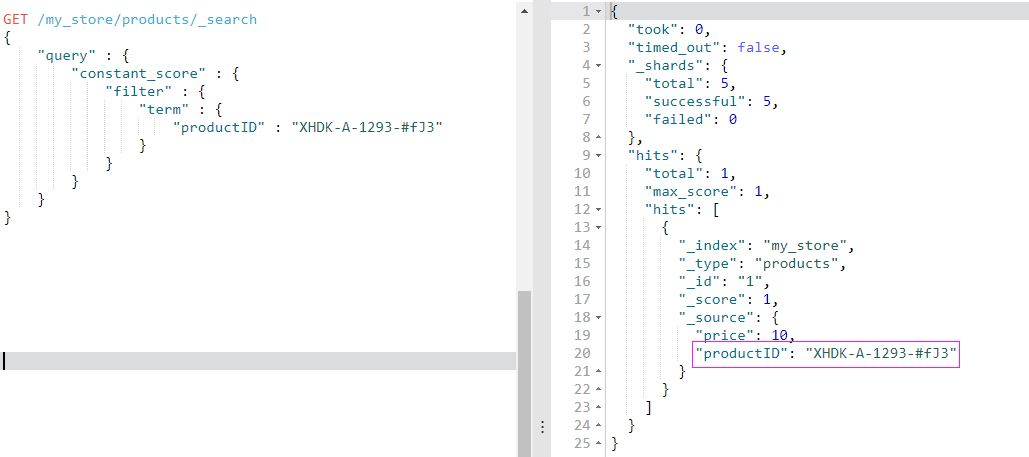
查询成功
4、查找多个精确值
term 查询对于查找单个值非常有用,但通常我们可能想搜索多个值。 如果我们想要查找价格字段值为 $20 或 $30 的文档该如何处理呢?
不需要使用多个 term 查询,我们只要用单个 terms 查询(注意末尾的 s ), terms 查询好比是 term 查询的复数形式(以英语名词的单复数做比)。
它几乎与 term 的使用方式一模一样,与指定单个价格不同,我们只要将 term 字段的值改为数组即可:
与 term 查询一样,也需要将其置入 filter 语句的常量评分查询中使用:
GET /my_store/products/_search
{
"query" : {
"constant_score" : {
"filter" : {
"terms" : {
"price" : [20, 30]
}
}
}
}
}
运行结果返回第二、第三和第四个文档:
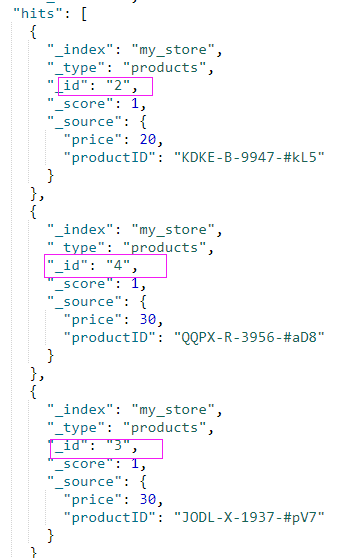
包含而不是相等
一定要了解 term 和 terms 是 包含(contains) 操作,而非 等值(equals) (判断)。 如何理解这句话呢?
如果我们有一个 term(词项)过滤器 { "term" : { "tags" : "search" } } ,它会与以下两个文档 同时匹配
5、范围查找
实际上,对数字范围进行过滤有时会更有用。例如,我们可能想要查找所有价格大于 $20 且小于 $40 美元的产品。
在 SQL 中,范围查询可以表示为:

Elasticsearch 有 range 查询, 不出所料地,可以用它来查找处于某个范围内的文档:

range 查询可同时提供包含(inclusive)和不包含(exclusive)这两种范围表达式,可供组合的选项如下:
gt: > 大于(greater than)
lt: < 小于(less than)
gte: >= 大于或等于(greater than or equal to)
lte: <= 小于或等于(less than or equal to)
下面是一个范围查询的例子:.
GET /my_store/products/_search
{
"query" : {
"constant_score" : {
"filter" : {
"range" : {
"price" : {
"gte" : 20,
"lt" : 40
}
}
}
}
}
}
如果想要范围无界(比方说 >20 ),只须省略其中一边的限制:
"range" : {
"price" : {
"gt" : 20
}
}
日期范围
range 查询同样可以应用在日期字段上:
"range" : {
"timestamp" : {
"gt" : "2014-01-01 00:00:00",
"lt" : "2014-01-07 00:00:00"
}
}
当使用它处理日期字段时, range 查询支持对 日期计算(date math) 进行操作,比方说,如果我们想查找时间戳在过去一小时内的所有文档:
"range" : {
"timestamp" : {
"gt" : "now-1h"
}
}
这个过滤器会一直查找时间戳在过去一个小时内的所有文档,让过滤器作为一个时间 滑动窗口(sliding window) 来过滤文档。
日期计算还可以被应用到某个具体的时间,并非只能是一个像 now 这样的占位符。只要在某个日期后加上一个双管符号 (||) 并紧跟一个日期数学表达式就能做到:
"range" : {
"timestamp" : {
"gt" : "2014-01-01 00:00:00",
"lt" : "2014-01-01 00:00:00||+1M"
}
}
早于 2014 年 1 月 1 日加 1 月(2014 年 2 月 1 日 零时)
字符串范围
range 查询同样可以处理字符串字段, 字符串范围可采用 字典顺序(lexicographically) 或字母顺序(alphabetically)。例如,下面这些字符串是采用字典序(lexicographically)排序的:
5, 50, 6, B, C, a, ab, abb, abc, b
在倒排索引中的词项就是采取字典顺序(lexicographically)排列的,这也是字符串范围可以使用这个顺序来确定的原因。
如果我们想查找从 a 到 b (不包含)的字符串,同样可以使用 range 查询语法:
"range" : {
"title" : {
"gte" : "a",
"lt" : "b"
}
}
注意基数
数字和日期字段的索引方式使高效地范围计算成为可能。 但字符串却并非如此,要想对其使用范围过滤,Elasticsearch 实际上是在为范围内的每个词项都执行 term 过滤器,这会比日期或数字的范围过滤慢许多。
字符串范围在过滤 低基数(low cardinality) 字段(即只有少量唯一词项)时可以正常工作,但是唯一词项越多,字符串范围的计算会越慢。
6、处理Null值
有的文档有名为 tags (标签)的字段,它是个多值字段, 一个文档可能有一个或多个标签,也可能根本就没有标签。如果一个字段没有值,那么如何将它存入倒排索引中的呢?
这是个有欺骗性的问题,因为答案是:什么都不存。
如何将某个不存在的字段存储在这个数据结构中呢?无法做到!简单的说,一个倒排索引只是一个 token 列表和与之相关的文档信息,如果字段不存在,那么它也不会持有任何 token,也就无法在倒排索引结构中表现。
最终,这也就意味着 ,null, [] (空数组)和 [null] 所有这些都是等价的,它们无法存于倒排索引中。
显然,世界并不简单,数据往往会有缺失字段,或有显式的空值或空数组。为了应对这些状况,Elasticsearch 提供了一些工具来处理空或缺失值
存在查询
第一件武器就是 exists 存在查询。 这个查询会返回那些在指定字段有任何值的文档,让我们索引一些示例文档并用标签的例子来说明:
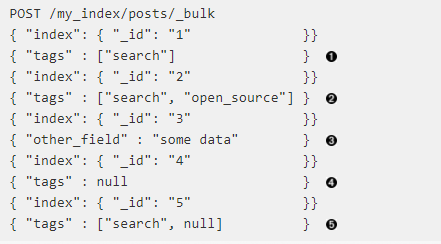
1、tags 字段有 1 个值。
2、tags 字段有 2 个值。
3、tags 字段缺失。
4、tags 字段被置为 null 。
5、tags 字段有 1 个值和 1 个 null 。
以上文档集合中 tags 字段对应的倒排索引如下:

我们的目标是找到那些被设置过标签字段的文档,并不关心标签的具体内容。只要它存在于文档中即可,用 SQL 的话就是用 IS NOT NULL 非空进行查询:
在 Elasticsearch 中,使用 exists 查询的方式如下:
GET /my_index/posts/_search
{
"query" : {
"constant_score" : {
"filter" : {
"exists" : { "field" : "tags" }
}
}
}
}
#或
GET /my_index/posts/_search
{
"query" : {
"bool" : {
"must":{
"exists" : { "field" : "tags" }
}
}
}
}
这个查询返回 3 个文档:
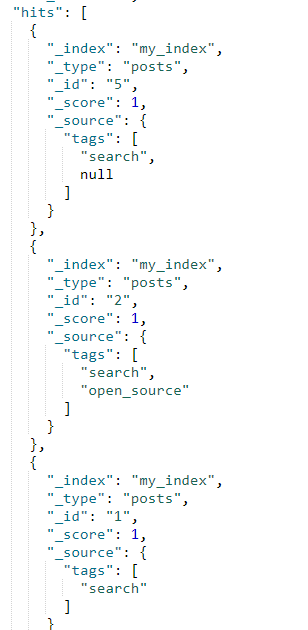
尽管文档 5 有 null 值,但它仍会被命中返回。字段之所以存在,是因为标签有实际值( search )可以被索引,所以 null 对过滤不会产生任何影响
显而易见,只要 tags 字段存在项(term)的文档都会命中并作为结果返回,只有 3 和 4 两个文档被排除
缺失查询
它返回某个特定 _无_ 值字段的文档,与以下 SQL 表达的意思类似:

转成ElasticSearch语句如下:
GET /my_index/posts/_search
{
"query" : {
"bool" : {
"must_not":{
"exists" : { "field" : "tags" }
}
}
}
}
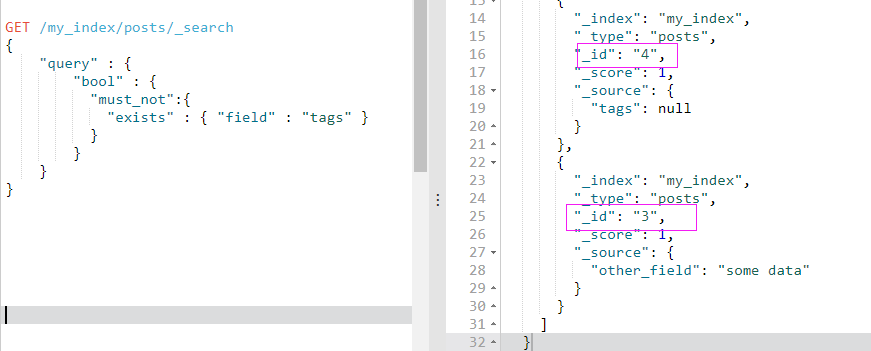
按照期望的那样,我们得到 3 和 4 两个文档(这两个文档的 tags 字段没有实际值):
ElasticSearch 结构化搜索的更多相关文章
- Elasticsearch结构化搜索与查询
Elasticsearch 的功能之一就是搜索,搜索主要分为两种类型,结构化搜索和全文搜索.结构化搜索是指有关查询那些具有内在结构数据的过程.比如日期.时间和数字都是结构化的:它们有精确的格式,我们可 ...
- Elasticsearch 结构化搜索、keyword、Term查询
前言 Elasticsearch 中的结构化搜索,即面向数值.日期.时间.布尔等类型数据的搜索,这些数据类型格式精确,通常使用基于词项的term精确匹配或者prefix前缀匹配.本文还将新版本的&qu ...
- ElasticSearch 结构化搜索全文
1.介绍 上篇介绍了搜索结构化数据的简单应用示例,现在来探寻 全文搜索(full-text search) :怎样在全文字段中搜索到最相关的文档. 全文搜索两个最重要的方面是: 相关性(Relevan ...
- Elasticsearch结构化搜索_在案例中实战使用term filter来搜索数据
1.根据用户ID.是否隐藏.帖子ID.发帖日期来搜索帖子 (1)插入一些测试帖子数据 POST /forum/article/_bulk { "index": { "_i ...
- ElasticSearch 2 (13) - 深入搜索系列之结构化搜索
ElasticSearch 2 (13) - 深入搜索系列之结构化搜索 摘要 结构化查询指的是查询那些具有内在结构的数据,比如日期.时间.数字都是结构化的.它们都有精确的格式,我们可以对这些数据进行逻 ...
- ElasticSearch常用结构化搜索
最近,需要用到ES的一些常用的结构化搜索命令,因此,看了一些官方的文档,学习了一下.结构化查询指的是查询那些具有内在结构的数据,比如日期.时间.数字都是结构化的. 它们都有精确的格式,我们可以对这些数 ...
- ElasticStack学习(九):深入ElasticSearch搜索之词项、全文本、结构化搜索及相关性算分
一.基于词项与全文的搜索 1.词项 Term(词项)是表达语意的最小单位,搜索和利用统计语言模型进行自然语言处理都需要处理Term. Term的使用说明: 1)Term Level Query:Ter ...
- elasticsearch 深入 —— 结构化搜索
结构化搜索 结构化搜索(Structured search) 是指有关探询那些具有内在结构数据的过程.比如日期.时间和数字都是结构化的:它们有精确的格式,我们可以对这些格式进行逻辑操作.比较常见的操作 ...
- Elasticsearch系列---结构化搜索
概要 结构化搜索针对日期.时间.数字等结构化数据的搜索,它们有自己的格式,我们可以对它们进行范围,比较大小等逻辑操作,这些逻辑操作得到的结果非黑即白,要么符合条件在结果集里,要么不符合条件在结果集之外 ...
随机推荐
- P3153 [CQOI2009]跳舞
题目描述 一次舞会有n个男孩和n个女孩.每首曲子开始时,所有男孩和女孩恰好配成n对跳交谊舞.每个男孩都不会和同一个女孩跳两首(或更多)舞曲.有一些男孩女孩相互喜欢,而其他相互不喜欢(不会”单向喜欢“) ...
- HDU 2546 饭卡(01 背包)
链接:http://acm.hdu.edu.cn/showproblem.php?pid=2546 思路:需要首先处理一下的的01背包,当饭卡余额大于等于5时,是什么都能买的,所以题目要饭卡余额最小, ...
- BZOJ5297 [Cqoi2018]社交网络 【矩阵树定理】
题目链接 BZOJ5297 题解 最近这玩意这么那么火 这题要用到有向图的矩阵树定理 主对角线上对应入度 剩余位置如果有边则为\(-1\),不然为\(0\) \(M_{i,i}\)即为以\(i\)为根 ...
- AGC007 - C Pushing Ball
Description 题目链接 懒得写详细题意了, 放个链接 \(n\le 2*10^5\) 个球, \(n+1\) 个坑, 排成数轴, 球坑交替. 相邻球-坑距离为等差数列 \(d\). 给定首项 ...
- NuGet Package Manager 实用命令
Creating Help Pages for ASP.NET Web API Install-Package Microsoft.AspNet.WebApi.HelpPage Install-Pac ...
- glOrthof 与glFrustumf
http://www.java123.net/v/533543.html glViewport()函数和glOrtho()函数的理解(转) 在OpenGL中有两个比较重要的投影变换函数,glViewp ...
- 手一抖误删了根目录 /usr 之后的挽救过程
一切悲剧来源于写的Shell没有好好检查,执行后把开发机的根目录 /usr 目录给删除了,而且是root执行,众所周知,/usr目录里有大量的应用层程序,删除之后导致大量命令无法使用,如 ssh / ...
- Windows基础-使用XAudio2播放音频(本质是WASAPI)
对于常见的音频播放,使用XAudio2足够了. 时间是把杀猪刀,滑稽的是我成了猪 早在Windows Vista中,M$推出了新的音频架构UAA,其中的CoreAudio接替了DSound.WaveX ...
- android的百度地图开发(一)
1,注册百度开发者账号 2,申请key ,注意开发版SH和发布版的SH 获取开发版SHA1: 输入命令:keytool -list -v -keystore debug.keystore,回车输入 ...
- postman的使用(转载)
Postman介绍 Postman是google开发的一款功能强大的网页调试与发送网页HTTP请求,并能运行测试用例的的Chrome插件.其主要功能包括: 模拟各种HTTP requests 从常用的 ...