MapReduce Input Split(输入分/切片)具体解释
看了非常多博客。感觉没有一个说的非常清楚,所以我来整理一下。
先看一下这个图
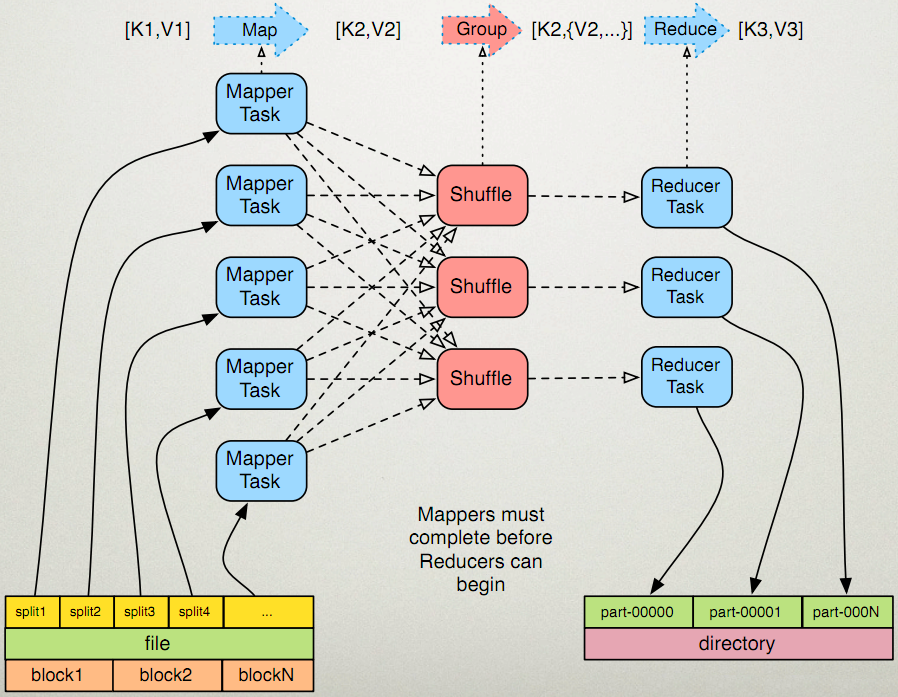
输入分片(Input Split):在进行map计算之前,mapreduce会依据输入文件计算输入分片(input split),每一个输入分片(input split)针对一个map任务。输入分片(input split)存储的并不是数据本身,而是一个分片长度和一个记录数据的位置的数组。
Hadoop 2.x默认的block大小是128MB,Hadoop 1.x默认的block大小是64MB,能够在hdfs-site.xml中设置dfs.block.size。注意单位是byte。
分片大小范围能够在mapred-site.xml中设置。mapred.min.split.size mapred.max.split.size。minSplitSize大小默觉得1B,maxSplitSize大小默觉得Long.MAX_VALUE
= 9223372036854775807
那么分片究竟是多大呢?
minSize=max{minSplitSize,mapred.min.split.size}
maxSize=mapred.max.split.size
splitSize=max{minSize,min{maxSize,blockSize}}
我们再来看一下源代码

所以在我们没有设置分片的范围的时候,分片大小是由block块大小决定的。和它的大小一样。比方把一个258MB的文件上传到HDFS上,如果block块大小是128MB。那么它就会被分成三个block块。与之相应产生三个split,所以终于会产生三个map task。我又发现了还有一个问题,第三个block块里存的文件大小仅仅有2MB,而它的block块大小是128MB,那它实际占用Linux
file system的多大空间?
答案是实际的文件大小,而非一个块的大小。
有大神已经验证这个答案了:http://blog.csdn.net/samhacker/article/details/23089157
1、往hdfs里面加入新文件前,hadoop在linux上面所占的空间为 464 MB:
watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvc2FtaGFja2Vy/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/Center">
2、往hdfs里面加入大小为2673375 byte(大概2.5 MB)的文件:
2673375 derby.jar
3、此时,hadoop在linux上面所占的空间为 467 MB——添加了一个实际文件大小(2.5 MB)的空间,而非一个block size(128 MB):

4、使用hadoop dfs -stat查看文件信息:
watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvc2FtaGFja2Vy/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/Center">
这里就非常清楚地反映出: 文件的实际大小(file size)是2673375 byte, 但它的block size是128 MB。
5、通过NameNode的web console来查看文件信息:
watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvc2FtaGFja2Vy/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/Center">
结果是一样的: 文件的实际大小(file size)是2673375 byte。 但它的block size是128 MB。
6、只是使用‘hadoop fsck’查看文件信息,看出了一些不一样的内容—— ‘1(avg.block size 2673375 B)’:

值得注意的是。结果中有一个 ‘1(avg.block size 2673375 B)’的字样。这里的 'block size' 并非指寻常说的文件块大小(Block Size)—— 后者是一个元数据的概念,相反它反映的是文件的实际大小(file size)。下面是Hadoop Community的专家给我的回复:
“The fsck is showing you an "average blocksize", not the block size metadata attribute of the file like stat shows. In this specific case, the average is just the length of your file, which is lesser than one whole block.”
最后一个问题是: 假设hdfs占用Linux file system的磁盘空间按实际文件大小算。那么这个”块大小“有必要存在吗?
事实上块大小还是必要的,一个显而易见的作用就是当文件通过append操作不断增长的过程中。能够通过来block size决定何时split文件。下面是Hadoop Community的专家给我的回复:
“The block size is a meta attribute. If you append tothe file later, it still needs to know when to split further - so it keeps that value as a mere metadata it can use to advise itself on write boundaries.”
补充:我还查到这样一段话
原文地址:http://blog.csdn.net/lylcore/article/details/9136555
一个split的大小是由goalSize, minSize, blockSize这三个值决定的。computeSplitSize的逻辑是,先从goalSize和blockSize两个值中选出最小的那个(比方一般不设置map数,这时blockSize为当前文件的块size。而goalSize是文件大小除以用户设置的map数得到的,假设没设置的话,默认是1)。
mapreduce的每个map处理的数据是不能跨越文件的,也就是说min_map_num >= input_file_num。
所以,终于的map个数应该为:
MapReduce Input Split(输入分/切片)具体解释的更多相关文章
- MapReduce Input Split 输入分/切片
MapReduce Input Split(输入分/切片)详解 public static long getMaxSplitSize(JobContext context) { return cont ...
- python使用input().split()接收多个用户输入
1.input() 接收多个用户输入需要与split()结合使用 host, port, username, passwd, dbname = input("请输入服务器地址,端口号,用户名 ...
- MapReduce深入理解输入和输出格式(2)-输入和输出完全总结
MapReduce太高深,性能也值得考虑,大家感兴趣的还是看看spark比较好. FileInputFormat类 FileInputFormat是所有使用文件为数据源的InputFormat实现的基 ...
- 【Python笔记】2020年7月30日练习【python用input函数输入一个列表】
练习课题链接:廖雪峰-Python教程-高级特性-迭代 学习记录: 1.Python当中类似于 三目运算符 的应用 2.Python用input函数输入一个列表 代码实例:对用户输入的一组数字转化成l ...
- MapReduce优化一(改变切片大小和Shuffle过程Reduce占用堆大小)
/*为防止处理超大作业时超时,将io时间设为1小时 * <property> <name>dfs.datanode.soc ...
- input框输入金额显示千分位
比如输入:1000000,则显示为1,000,000(或者是保留3位小数:1,000,000.000) 知识点: 1)JavaScript parseFloat() 函数: 定义:parseFloat ...
- JS实现input中输入数字,控制每四位加一个空格(银行卡号格式)
前言 今天来讲讲js中实现input中输入数字,控制每四位加一个空格的方法!这个主要是应用于我们在填写表单的时候,填写银行卡信息,要求我们输入的数字是四位一个空格!今天主要介绍两种方式来实现这个方法! ...
- 项目小结:手机邮箱正则,URL各种判断返回页面,input输入框输入符合却获取不到问题
1.手机邮箱正则 近两年出来很多新号码,听说199什么的都有了- -导致以前的正则不能用了....这就很难过,总是过一段时间出一种新号码.因此,我决定使用返朴归真的手机正则. 手机正则:var reg ...
- 编辑表格输入内容、根据input输入框输入数字动态生成表格行数、编辑表格内容提交传给后台数据处理
编辑表格输入内容.根据input输入框输入数字动态生成表格行数.编辑表格内容提交传给后台数据处理 记录自己学习做的东西,写的小demo,希望对大家也有帮助! 代码如下: <!DOCTYPE ht ...
随机推荐
- python核心编程学习记录之Web编程
cgi未完待续
- java 通过流的方式读取本地图片并显示在jsp 页面上(类型以jpg、png等结尾的图片)
Java代码: File filePic = new File(path+"1-ab1.png"); if(filePic.exists()){ FileInputStream i ...
- Spring配置xml版
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.sp ...
- 创建es索引{"acknowledged"=>true, "shards_acknowledged"=>false}
创建es索引{"acknowledged"=>true, "shards_acknowledged"=>false} [2018-05-19T13: ...
- [WCF菜鸟]什么是WCF
一.概述 Windows Communication Foundation(WCF)是由微软发展的一组数据通信的应用程序开发接口,可以翻译为Windows通讯接口,它是.NET框架的一部分.由 .NE ...
- 自己定义控件-LinearListView
一.描写叙述 用LinearLayout 实现的一个ListView ,重写了ListView中的经常使用函数,所以使用起来和ListView 没有区别. 比方:setAdapter.addHeade ...
- Android学习(二十)Notification通知栏
一.通知栏的内容 1.图标 2.标题 3.内容 4.时间 5.点击后的相应 二.如何实现通知栏 1.获取NotificationManager. 2.显示通知栏:notify(id,notificat ...
- 标准库Queue的实现
跟上篇实现stack的思路一致,我增加了一些成员函数模板,支持不同类型的Queue之间的复制和赋值. 同时提供一个异常类. 代码如下: #ifndef QUEUE_HPP #define QUEUE_ ...
- 你真的了解装箱(Boxing)和拆箱(Unboxing)吗?
所谓装箱就是装箱是将值类型转换为 object 类型或由此值类型实现的任一接口类型的过程.而拆箱就是反过来了.很多人可能都知道这一点,但是是否真的就很了解boxing和unboxing了呢?可以看下下 ...
- UVA - 434 Matty's Blocks
题意:给你正视和側视图,求最多多少个,最少多少个 思路:贪心的思想.求最少的时候:由于能够想象着移动,尽量让两个视图的重叠.所以我们统计每一个视图不同高度的个数.然后计算.至于的话.就是每次拿正视图的 ...