Hadoop计数器
1. MapReduce计数器是什么
计数器是用来记录Job的执行进度和状态的,其作用类似于日志。我们可以在程序的某个位置插入计数器,记录数据或进度的变化情况。
2. MapReduce计数器能做什么
计数器为我们提供了一个窗口,用于观察Job运行期间的各种细节数据,对MapReduce的性能调优很有帮助,MapReduce性能优化的评估大部分都是基于这些计数器Counter的数值来表现的。
3. MapReduce都有哪些内置计数器
MapReduce中自带了许多默认的Counter计数器,要了解这些内置计数器,必须知道计数组名称(groupName)和计数器名称(counterName)。
(1)任务计数器
在任务技术过程中,它负责采集任务的主要信息,每个作业的所有任务的结果都会被聚集起来。下面以MapReduce人事物计数器为例:
groupName:org.apache.hadoop.mapreduce.TaskCounter
counterName:
1)MAP_INPUT_RECORDS
2)REDUICE_INPUT_RECORDS
3)CPU_MILLISECONDS
(2)作业计数器
作业计数器由JobTracker或者YARN维护维护,因此无需在网络间传输数据。这些计数器都是作业级别的通缉量,其值不会随着任务运行而改变。
groupName:org.apache.hadoop.mapreduce.JobCounter
counterName:
1)TOTAL_LAUNCHED_MAPS
2)TOTAL_LAUNCHED_REDUCES
4. 计数器该如何使用
(1)定义计数器
1)枚举声明计数器
Contex contex…
//自定义枚举变量
Counter counter = contex.getCounter(Enum eum)
2)自定义计数器
Contex contex…
//自己命名groupName和counterName
Counter counter = contex.getCounter(String groupName, String counterName)
(2)为计数器赋值
1) 初始化计数器
counter.setValue(long value);//设置初始值
2) 计数器自增
counter.increment(long incr);//增加计数
(3) 获取计数器的值
1) 获取枚举计数器的值
Job job…
job.waitForCompletion(true);
Counters counters = job.getCounters();
Counter counter = counters.findCounter(BAD_RECORDS);
//查找枚举计数器,假如Enum的变量为BAD_RECORDS
long value = counter.getValue();//获取计数值
2) 获取自定义计数器的值
Job job...
job.waitForCompletion(true);
Counters counters=job.getCounters();
Counter counter=counters.findCounter("ErrorCounter","toolong");//假如groupName为ErrorCounter,counterName为toolong
long value=counter.getValue();//获取计数值
3)获取内置计数器的值
Job job...
job.waitForCompletion(true);
Counters counters=job.getCounters();
Counter counter=counters.findCounter("org.apache.hadoop.mapreduce.JobCounter", "TOTAL_LAUNCHED_REDUCES");
//假如groupName为org.apache.hadoop.mapreduce.JobCounter,counterName为TOTAL_LAUNCHED_REDUCES
long value=counter.getValue();//获取计数值
4)获取所有计数器的值
Counters counters = job.getCounters();
for (CounterGroup group : counters) {
for (Counter counter : group) {
System.out.println(counter.getDisplayName() + ": " + counter.getName() + ": "+ counter.getValue());
}
}
5. 自定义计数器
自定义计数器用的比较广泛,特别是统计无效数据条数的时候,我们就会用到计数器来记录错误日志的条数。下面我们自定义计数器,统计输入的无效数据。
数据集
假如一个文件,规范的格式是3个字段,“\t”作为分隔符,其中有2条异常数据,一条数据是只有2个字段,一条数据是有4个字段。其内容如下所示:
jim 1 28
kate 0 26
tom 1
kaka 1 22
lily 0 29 22
启动Hadoop集群,然后在HDFS中新建目录存放测试数据。
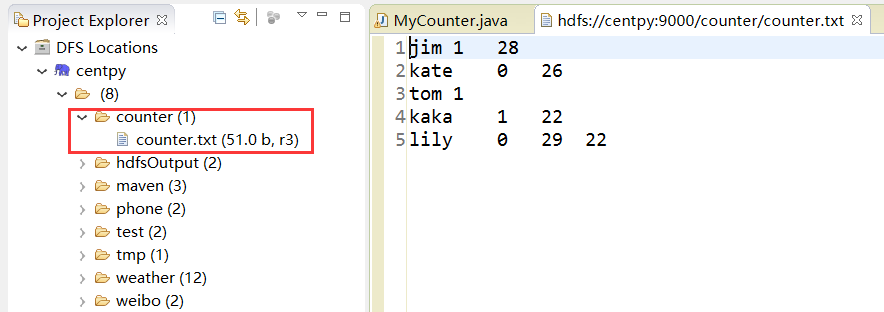
在Hadoop项目下新建MyCounter.java类
package com.hadoop.Counter; import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner; /**
* @author Zimo
* MapReduce计数器
*/
public class MyCounter extends Configured implements Tool { /**
* @param args
*/
public static class MyCounterMap extends Mapper<LongWritable, Text, Text, Text> {
//定义枚举对象
public static enum LOG_PROCESSOR_COUNTER {
//枚举对象BAD_RECORDS_LONG来统计长数据,枚举对象BAD_RECORDS_SHORT来统计短数据
BAD_RECORDS_LONG, BAD_RECORDS_SHORT
}; protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String arr_values[] = value.toString().split("/t");
if (arr_values.length > ) {
//动态自定义计数器
context.getCounter("ErrorCounter", "toolong").increment();
//枚举声明计数器
context.getCounter(LOG_PROCESSOR_COUNTER.BAD_RECORDS_LONG).increment();
} else if(arr_values.length < ) {
// 动态自定义计数器
context.getCounter("ErrorCounter", "tooshort").increment();
// 枚举声明计数器
context.getCounter(LOG_PROCESSOR_COUNTER.BAD_RECORDS_SHORT).increment();
} else {
context.write(value, new Text(""));
}
}
} public int run(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Path myPath = new Path(args[]);
FileSystem hdfs = myPath.getFileSystem(conf);
if (hdfs.isDirectory(myPath)) {
hdfs.delete(myPath);
} Job job = new Job(conf, "MyCounter");
job.setJarByClass(MyCounter.class);
job.setMapperClass(MyCounterMap.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class); FileInputFormat.addInputPath(job, new Path(args[]));
FileOutputFormat.setOutputPath(job, new Path(args[]));
job.waitForCompletion(true); return ;
} public static void main(String[] args) throws Exception {
// TODO Auto-generated method stub
String[] arg0 = {
"hdfs://centpy:9000/counter/counter.txt", "hdfs://centpy:9000/counter/out"
};
int ec = ToolRunner.run(new Configuration(), new MyCounter(), arg0);
System.exit(ec);
} }
运行程序之后,日志如下所示。
-- ::, INFO [org.apache.hadoop.mapreduce.Job] - Counters:
File System Counters
FILE: Number of bytes read=
FILE: Number of bytes written=
FILE: Number of read operations=
FILE: Number of large read operations=
FILE: Number of write operations=
HDFS: Number of bytes read=
HDFS: Number of bytes written=
HDFS: Number of read operations=
HDFS: Number of large read operations=
HDFS: Number of write operations=
Map-Reduce Framework
Map input records=
Map output records=
Map output bytes=
Map output materialized bytes=
Input split bytes=
Combine input records=
Combine output records=
Reduce input groups=
Reduce shuffle bytes=
Reduce input records=
Reduce output records=
Spilled Records=
Shuffled Maps =
Failed Shuffles=
Merged Map outputs=
GC time elapsed (ms)=
CPU time spent (ms)=
Physical memory (bytes) snapshot=
Virtual memory (bytes) snapshot=
Total committed heap usage (bytes)=
ErrorCounter
tooshort=
com.hadoop.Counter.MyCounter$MyCounterMap$LOG_PROCESSOR_COUNTER
BAD_RECORDS_SHORT=
File Input Format Counters
Bytes Read=
File Output Format Counters
Bytes Written=0
从日志中可以看出,通过枚举声明和自定义计数器两种方式,统计出的不规范数据是一样的。
以上就是博主为大家介绍的这一板块的主要内容,这都是博主自己的学习过程,希望能给大家带来一定的指导作用,有用的还望大家点个支持,如果对你没用也望包涵,有错误烦请指出。如有期待可关注博主以第一时间获取更新哦,谢谢!
版权声明:本文为博主原创文章,未经博主允许不得转载。
Hadoop计数器的更多相关文章
- hadoop 计数器
一.hadoop有非常多自带的计数器,相信看过执行log的都会看到各种数据 二.用户自己定义计数器 在开发中常常须要记录错误的数据条数,就能够用计数器来解决. 1.定义:用一个枚举来定义一组计数器,枚 ...
- Hadoop日记Day17---计数器、map规约、分区学习
一.Hadoop计数器 1.1 什么是Hadoop计数器 Haoop是处理大数据的,不适合处理小数据,有些大数据问题是小数据程序是处理不了的,他是一个高延迟的任务,有时处理一个大数据需要花费好几个小时 ...
- MapReducer Counter计数器的使用,Combiner ,Partitioner,Sort,Grop的使用,
一:Counter计数器的使用 hadoop计数器:可以让开发人员以全局的视角来审查程序的运行情况以及各项指标,及时做出错误诊断并进行相应处理. 内置计数器(MapReduce相关.文件系统相关和作业 ...
- Hadoop学习记录(4)|MapReduce原理|API操作使用
MapReduce概念 MapReduce是一种分布式计算模型,由谷歌提出,主要用于搜索领域,解决海量数据计算问题. MR由两个阶段组成:Map和Reduce,用户只需要实现map()和reduce( ...
- MapReduce的计数器
第一部分.Hadoop计数器简述 hadoop计数器: 可以让开发人员以全局的视角来审查程序的运行情况以及各项指标,及时做出错误诊断并进行相应处理. 内置计数器(MapReduce相关.文件系统相关 ...
- HIVE编程指南之HiveQL的学习笔记1
// HiveQLa) 数据定义语言1 数据库表的一个目录或命名空间,如果用户没有指定数据库的话,那么将会使用默认的数据库default-----创建数据库CREATE DATABASE guoyon ...
- HQL之动态分区调整
动态分区插入可以基于查询语句分出出要插入的分区名称.比如,下面向分区表插入数据的SQL: insert into table chavin.emp_pat partition(dname,loc) s ...
- hive从查询中获取数据插入到表或动态分区
Hive的insert语句能够从查询语句中获取数据,并同时将数据Load到目标表中.现在假定有一个已有数据的表staged_employees(雇员信息全量表),所属国家cnty和所属州st是该表的两 ...
- Hive Tutorial 阅读记录
Hive Tutorial 目录 Hive Tutorial 1.Concepts 1.1.What Is Hive 1.2.What Hive Is NOT 1.3.Getting Started ...
随机推荐
- C#某月的第一天和最后一天
1.本月的第一天===>DateTime.Now.AddDays(1 - DateTime.Now.Day);//当前日期减去当前日期和本月一号相差天数 2.本月的最后一天===>Date ...
- linux 时间处理 + 简单写log
1s ==1000ms == 1,000,000us == 1,000,000,000 nanosecond uname -a Linux scott-Z170X 4.15.0-34-generic ...
- jquery插件开发常用总结一
由于使用jquery插件后当form表单提交的时候,若发生错误,同时有验证错误文本时,即使用rules和message后,会自动生成一个label标签里面装有错误文件值. 我们可以替换它: 方式为:v ...
- k8s 基础 k8s架构和组件
k8s 的总架构图
- MS SQL 取分组后的几条数据
SELECT uploaddate ,ptnumber ,instcount FROM ( SELECT ROW_NUMBER() OVER( PARTITION BY uploaddate ORDE ...
- elasticsearch2.x插件之一:bigdesk
bigdesk是elasticsearch的一个集群监控工具,可以通过它来查看es集群的各种状态,如:cpu.内存使用情况,索引数据.搜索情况,http连接数等. 可用项目git地址:https:// ...
- 文件格式——Sam&bam文件
Sam&bam文件 SAM是一种序列比对格式标准, 由sanger制定,是以TAB为分割符的文本格式.主要应用于测序序列mapping到基因组上的结果表示,当然也可以表示任意的多重比对结果.当 ...
- 使用python已知平均数求随机数
问题描述:产生40个数,范围是363-429之间,平均值为402 思路: 1 产生一个随机数 2 使用平均数减去随机数求出第二个数,生成20组 3 将排序打乱 # -*- coding: cp936 ...
- 介绍一款“对话框”组件之 “artDialog”在项目中的使用
在实际开发项目中经常会用到对话框组件,提示一些信息.其实有很多,例如:在项目中常用到的“Jquery-UI.Jquery-EasyUI”的.Dialog,他们也很强大,Api文档也很多.今天就介绍一款 ...
- 【C#】截取字符串
几个经常用到的字符串的截取 string str="123abc456"; int i=3; 1 取字符串的前i个字符 str=str.Substring(0,i); // or ...