[原创] hadoop学习笔记:wordcout程序实践
看了官网上的示例:但是给的不是很清楚,这里依托官网给出的示例,加上自己的实践,解析worcount程序的操作
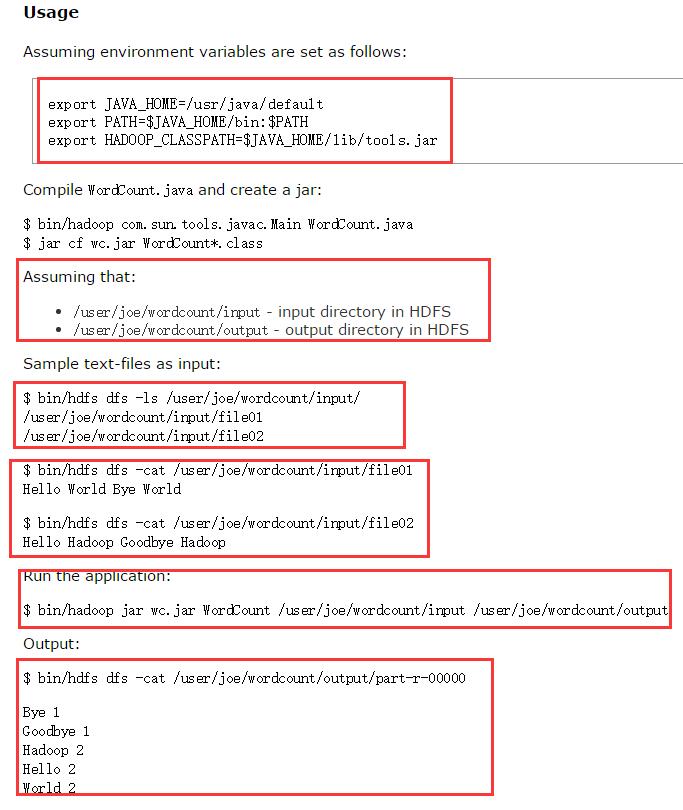
1.首先你的确定你的集群正确安装,并且启动你的集群,应为这个是hadoop2.6.0,所以你的启动以下的守护进程:
$sbin/ ./start-dfs.sh
$sbin/ ./start-yarn.sh
$sbin/ mr-jobhistory-daemon.sh start historyserver
2.在lccal系统上创建两个文件,记住是文件,命名:file01,file02
笔者在/opt/localdata 下创建的file01,file02,内容如下


3.将本地的file01,file02上传至hdfs文件系统,利用命令
首先在hdfs文件系统上创建目录:输入目录 /library/wordcount/input/ 输出目录 /library/wordcount/output/
创建输入目录:$bin/ hdfs dfs -mkdir -P /library/wordcount/input/
创建输出目录:$bin/ hdfs dfs -mkdir -P /library/wordcount/output/
将本地的文件copy到hdfs文件系统
$bin/ hdfs dfs -copyFromLocal /opt/localdata/file01 /library/wordcount/input/
$bin/ hdfs dfs -copyFromLocal /opt/localdata/file02 /library/wordcount/input/
完成之后可以查看文件是否copy过去
$bin/ hdfs dfs -ls /library/wordcount/input/

4.可以运行程序了
进入目录:cd $HADOOP_HOME/share/hadoop/mapreduce
运行命令$ hadoop jar hadoop-mapreduce-examples-2.6.0.jar wordcount /library/wordcount/input/ /library/wordcount/output/rs_wordcount
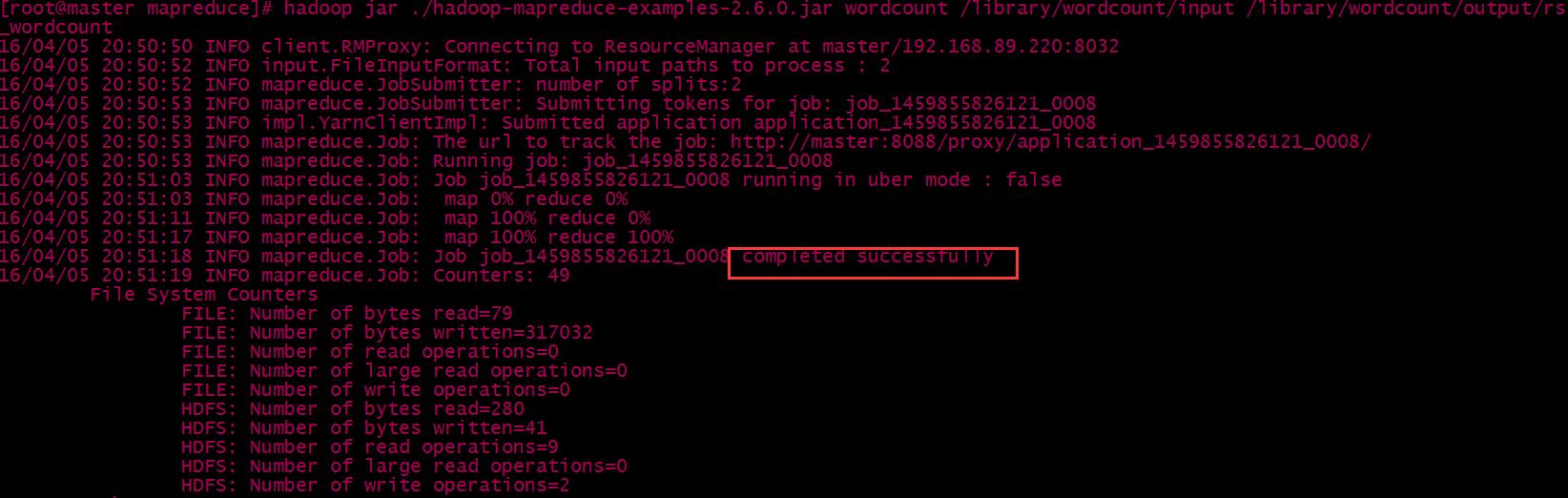
运行成功
5.查看运行结果
①web查看,首先需要设置web的,可以参考我的另外一篇博客http://www.cnblogs.com/jasonHome/p/5303040.html 自行设置
在浏览器输入:master:50070 (笔者将namenode的主机设置为master)
点击utilities ->brows the file system 如下图
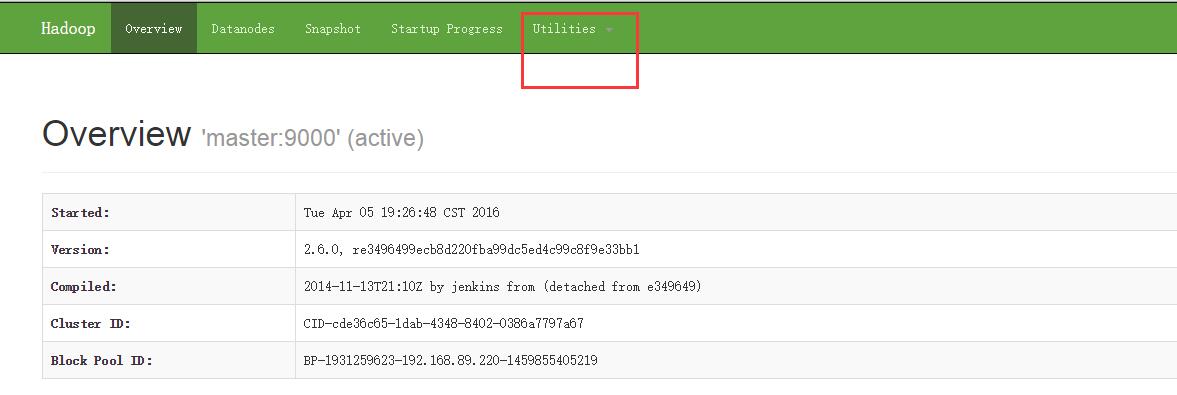
在hdfs文件系统中查看生成的文件结果文件:搜索 /library/wordcount/output/rs_wordcount
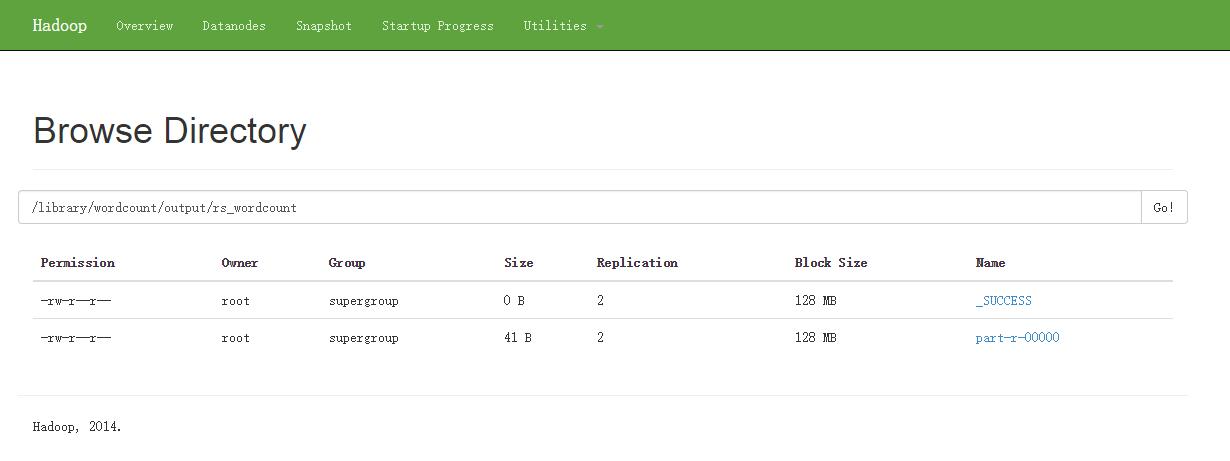
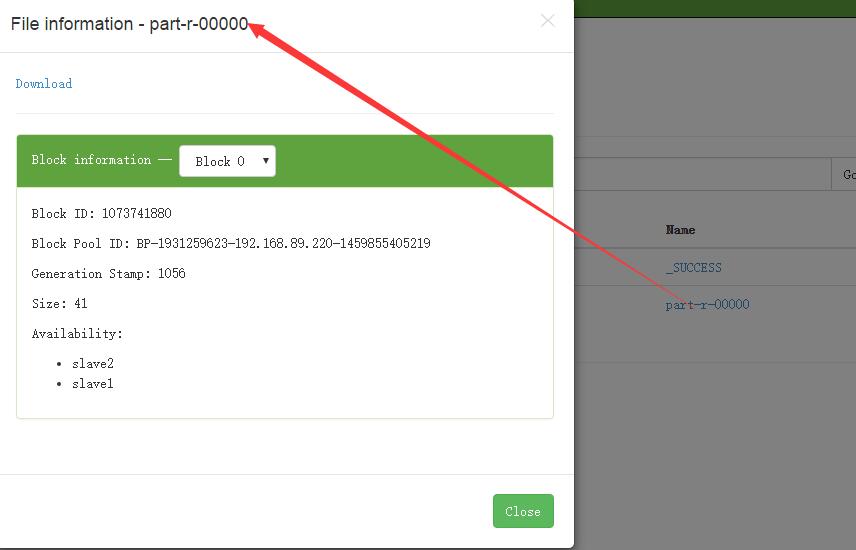
点击part-r-00000,就可以查看了
②可以通过命令行查看:
$ bin/hdfs dfs -cat /library/wordcount/output/part-r-00000
结果如下

补充:还可以通过 master:8088查看集群的情况, master:19888查看历史提交的任务和记录,如下图
master:8088

master:19888

好了,这就是我想和大家分享的,自己琢磨了 ,5个小时左右,如有问题,希望大家指正。
[原创] hadoop学习笔记:wordcout程序实践的更多相关文章
- [原创] hadoop学习笔记:卸载和安装jdk
一,卸载jdk 1.确定jdk版本 #rpm -qa | grep jak 可能的结果: java-1.7.0-openjdk-1.7.0.75-2.5.4.2.el7_0.x86_64 java- ...
- [原创] hadoop学习笔记:hadoopWEB监控
笔者安装单机版本 要想实现hadoopweb页面的监控,需要解决以下几个问题 1.关闭linux的防火墙:#service iptables stop 2.将linuxSE设置为disabled:#v ...
- [原创] hadoop学习笔记:重新格式化HDFS文件系统
所谓的重新格式化HDFS文件系统,实际意味着重新的创建一个HDFS文件系统.也就是说,必须将先前的已经有的文件系统配置删除.如下: 笔者采用的是最小化安装 这个是core-site.xml配置 这个是 ...
- Hadoop学习笔记(6) ——重新认识Hadoop
Hadoop学习笔记(6) ——重新认识Hadoop 之前,我们把hadoop从下载包部署到编写了helloworld,看到了结果.现是得开始稍微更深入地了解hadoop了. Hadoop包含了两大功 ...
- Hadoop学习笔记(5) ——编写HelloWorld(2)
Hadoop学习笔记(5) ——编写HelloWorld(2) 前面我们写了一个Hadoop程序,并让它跑起来了.但想想不对啊,Hadoop不是有两块功能么,DFS和MapReduce.没错,上一节我 ...
- Hadoop学习笔记(7) ——高级编程
Hadoop学习笔记(7) ——高级编程 从前面的学习中,我们了解到了MapReduce整个过程需要经过以下几个步骤: 1.输入(input):将输入数据分成一个个split,并将split进一步拆成 ...
- Hadoop学习笔记(2)
Hadoop学习笔记(2) ——解读Hello World 上一章中,我们把hadoop下载.安装.运行起来,最后还执行了一个Hello world程序,看到了结果.现在我们就来解读一下这个Hello ...
- Hadoop学习笔记(2) ——解读Hello World
Hadoop学习笔记(2) ——解读Hello World 上一章中,我们把hadoop下载.安装.运行起来,最后还执行了一个Hello world程序,看到了结果.现在我们就来解读一下这个Hello ...
- Hadoop学习笔记(1) ——菜鸟入门
Hadoop学习笔记(1) ——菜鸟入门 Hadoop是什么?先问一下百度吧: [百度百科]一个分布式系统基础架构,由Apache基金会所开发.用户可以在不了解分布式底层细节的情况下,开发分布式程序. ...
随机推荐
- SSH项目web.xml文件的常用配置【struts2的过滤器、spring监听器、解决Hibernate延迟加载问题的过滤器、解决中文乱码的过滤器】
配置web.xml(struts2的过滤器.spring监听器.解决Hibernate延迟加载问题的过滤器.解决中文乱码的过滤器) <!-- 解决中文乱码问题 --> <filter ...
- ListView滚动到底部判断
参考:http://blog.csdn.net/jodan179/article/details/8017693 List13介绍的是ListView.OnScrollListener的 onScro ...
- 电路板上为何要有孔洞?何谓PTH/NPTH/vias(导通孔)
推荐文章:PCBA大讲堂:用数据比较OSP及ENIG表面处理电路板的焊接强度 如果你有机会拿起一片电路板,稍微观察一下会发现这电路板上有着许多大大小小的孔洞,把它拿起来对着天花板上的电灯看,还会发 ...
- 如何去掉MapReduce输出的默认分隔符
我们在用MapReduce做数据处理的时候,经常会遇到将只需要输出键或者值的情况,如context.write(new Text(record), new Text("")),这样 ...
- 解决:Adb connection Error:远程主机强迫关闭了一个现有的连接
最近刚入手了一台G12,用它来调试程序的时候,eclipse的console总是出现如下的错误“Adb connection Error:远程主机强迫关闭了一个现有的连接” 问题出现的原因:这是ddm ...
- Effective C++ 49,50
49.熟悉标准库. C++标准库非常大. 首先标准库中函数非常多,为了避免名字冲突.使用命名空间std.而之前的库函数都存放于< .h>中,如今成为伪标准库.而不能直接将这些头文件所有直接 ...
- _DataStructure_C_Impl:图的最小生成树
#include<stdio.h> #include<stdlib.h> #include<string.h> typedef char VertexType[4] ...
- 如何使CSS--better(系列二)
上一篇文章(如何使CSS--beter 系列一)中 分析了一下 什么样子的代码是高效的 应该避免什么样子的代码, 那么什么样子的代码是更容易扩展的? 什么代码是更好维护的? 什么代码是更好的? 下边 ...
- (转)linux设备驱动之USB数据传输分析 二
3.2:控制传输过程1:root hub的控制传输在前面看到,对于root hub的情况,流程会转入rh_urb_enqueue().代码如下:static int rh_urb_enqueue (s ...
- centos7.0 增加/usr分区的容量减少home分区的大小
把/home内容备份,然后将/home文件系统所在的逻辑卷删除,扩大/root文件系统,新建/home:tar cvf /tmp/home.tar /home #备份/homeumount /home ...