[原创] hadoop学习笔记:wordcout程序实践
看了官网上的示例:但是给的不是很清楚,这里依托官网给出的示例,加上自己的实践,解析worcount程序的操作
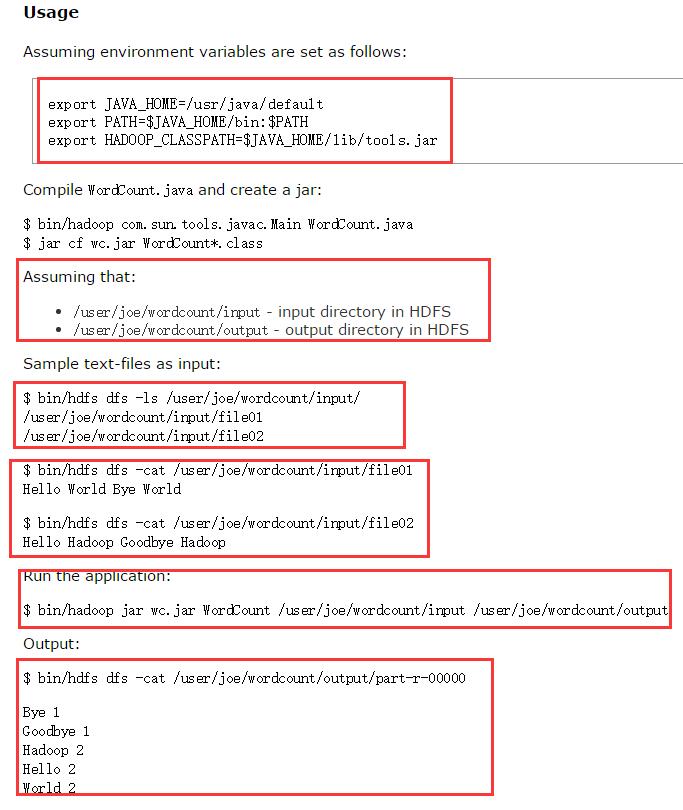
1.首先你的确定你的集群正确安装,并且启动你的集群,应为这个是hadoop2.6.0,所以你的启动以下的守护进程:
$sbin/ ./start-dfs.sh
$sbin/ ./start-yarn.sh
$sbin/ mr-jobhistory-daemon.sh start historyserver
2.在lccal系统上创建两个文件,记住是文件,命名:file01,file02
笔者在/opt/localdata 下创建的file01,file02,内容如下


3.将本地的file01,file02上传至hdfs文件系统,利用命令
首先在hdfs文件系统上创建目录:输入目录 /library/wordcount/input/ 输出目录 /library/wordcount/output/
创建输入目录:$bin/ hdfs dfs -mkdir -P /library/wordcount/input/
创建输出目录:$bin/ hdfs dfs -mkdir -P /library/wordcount/output/
将本地的文件copy到hdfs文件系统
$bin/ hdfs dfs -copyFromLocal /opt/localdata/file01 /library/wordcount/input/
$bin/ hdfs dfs -copyFromLocal /opt/localdata/file02 /library/wordcount/input/
完成之后可以查看文件是否copy过去
$bin/ hdfs dfs -ls /library/wordcount/input/

4.可以运行程序了
进入目录:cd $HADOOP_HOME/share/hadoop/mapreduce
运行命令$ hadoop jar hadoop-mapreduce-examples-2.6.0.jar wordcount /library/wordcount/input/ /library/wordcount/output/rs_wordcount
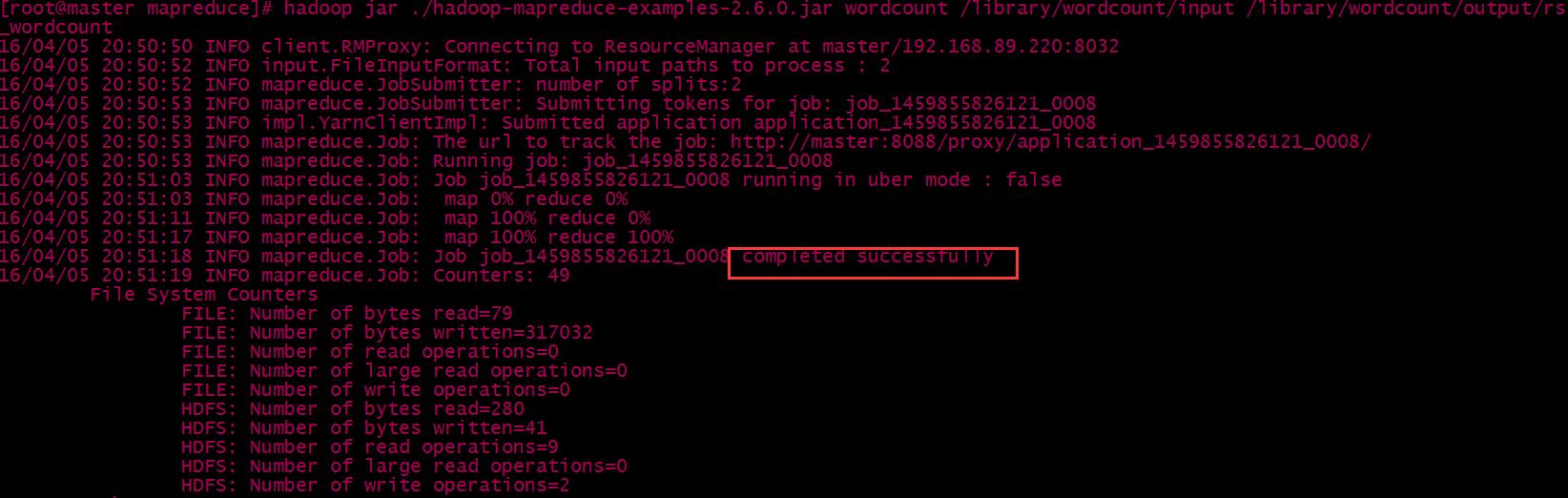
运行成功
5.查看运行结果
①web查看,首先需要设置web的,可以参考我的另外一篇博客http://www.cnblogs.com/jasonHome/p/5303040.html 自行设置
在浏览器输入:master:50070 (笔者将namenode的主机设置为master)
点击utilities ->brows the file system 如下图
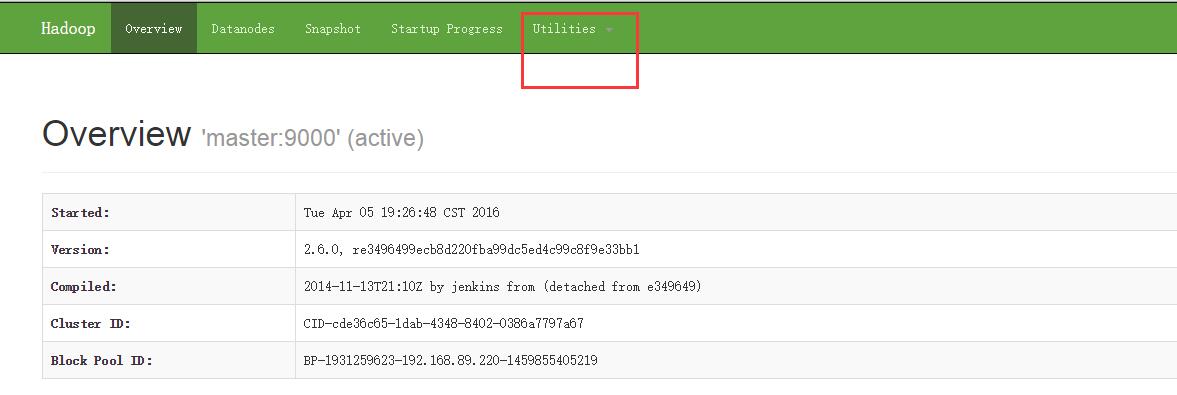
在hdfs文件系统中查看生成的文件结果文件:搜索 /library/wordcount/output/rs_wordcount
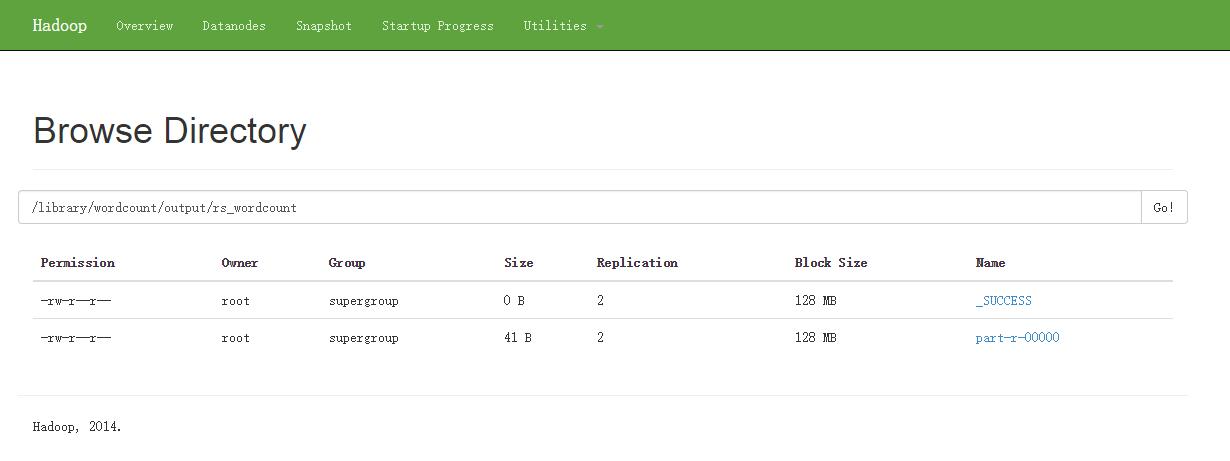
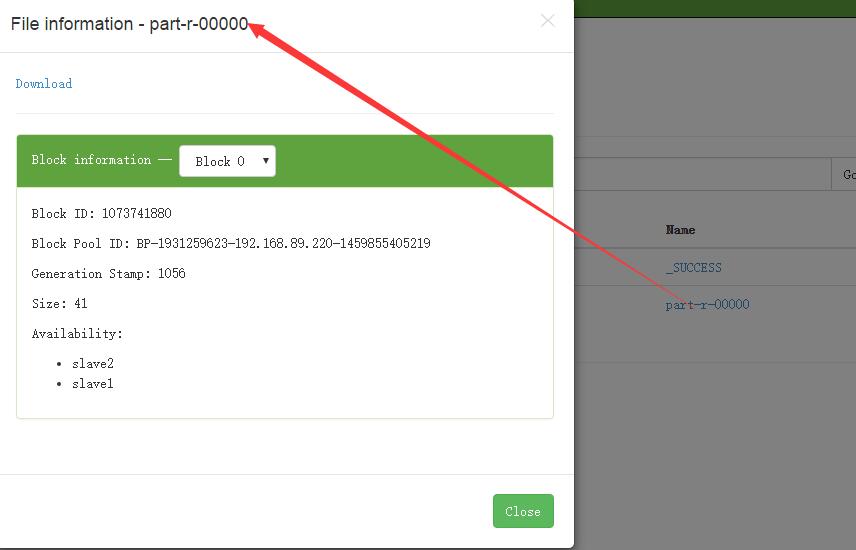
点击part-r-00000,就可以查看了
②可以通过命令行查看:
$ bin/hdfs dfs -cat /library/wordcount/output/part-r-00000
结果如下

补充:还可以通过 master:8088查看集群的情况, master:19888查看历史提交的任务和记录,如下图
master:8088

master:19888

好了,这就是我想和大家分享的,自己琢磨了 ,5个小时左右,如有问题,希望大家指正。
[原创] hadoop学习笔记:wordcout程序实践的更多相关文章
- [原创] hadoop学习笔记:卸载和安装jdk
一,卸载jdk 1.确定jdk版本 #rpm -qa | grep jak 可能的结果: java-1.7.0-openjdk-1.7.0.75-2.5.4.2.el7_0.x86_64 java- ...
- [原创] hadoop学习笔记:hadoopWEB监控
笔者安装单机版本 要想实现hadoopweb页面的监控,需要解决以下几个问题 1.关闭linux的防火墙:#service iptables stop 2.将linuxSE设置为disabled:#v ...
- [原创] hadoop学习笔记:重新格式化HDFS文件系统
所谓的重新格式化HDFS文件系统,实际意味着重新的创建一个HDFS文件系统.也就是说,必须将先前的已经有的文件系统配置删除.如下: 笔者采用的是最小化安装 这个是core-site.xml配置 这个是 ...
- Hadoop学习笔记(6) ——重新认识Hadoop
Hadoop学习笔记(6) ——重新认识Hadoop 之前,我们把hadoop从下载包部署到编写了helloworld,看到了结果.现是得开始稍微更深入地了解hadoop了. Hadoop包含了两大功 ...
- Hadoop学习笔记(5) ——编写HelloWorld(2)
Hadoop学习笔记(5) ——编写HelloWorld(2) 前面我们写了一个Hadoop程序,并让它跑起来了.但想想不对啊,Hadoop不是有两块功能么,DFS和MapReduce.没错,上一节我 ...
- Hadoop学习笔记(7) ——高级编程
Hadoop学习笔记(7) ——高级编程 从前面的学习中,我们了解到了MapReduce整个过程需要经过以下几个步骤: 1.输入(input):将输入数据分成一个个split,并将split进一步拆成 ...
- Hadoop学习笔记(2)
Hadoop学习笔记(2) ——解读Hello World 上一章中,我们把hadoop下载.安装.运行起来,最后还执行了一个Hello world程序,看到了结果.现在我们就来解读一下这个Hello ...
- Hadoop学习笔记(2) ——解读Hello World
Hadoop学习笔记(2) ——解读Hello World 上一章中,我们把hadoop下载.安装.运行起来,最后还执行了一个Hello world程序,看到了结果.现在我们就来解读一下这个Hello ...
- Hadoop学习笔记(1) ——菜鸟入门
Hadoop学习笔记(1) ——菜鸟入门 Hadoop是什么?先问一下百度吧: [百度百科]一个分布式系统基础架构,由Apache基金会所开发.用户可以在不了解分布式底层细节的情况下,开发分布式程序. ...
随机推荐
- angular中通过CSS使下拉列表默认值变灰
angular版本:angular5 先看效果图: drop down的样式是我用CSS样式控制的,没有用插件.想要改变Drop Down List里的默认值的颜色,我的思路是这样的. 在<se ...
- About the Apple Captive Network Assistant
If you’re a mac user, you likely have seen a strange popup window appear on your computer when you t ...
- Fiddler 默认不能抓取页面信息的问题
先如下配置
- Quartus和ISE调用Synplify进行综合的问题
分别尝试采用Quartus和ISE调用第三方综合软件Synplify进行综合. [软件版本] Quartus II 13.0 (SP).ISE 14.4 .Synplify 201303. [问题描述 ...
- python中wxpython用法
转载:https://wxpython.org/pages/overview/ Hello World Every programming language and UI toolkit needs ...
- 计算机图形学(二)输出图元_6_OpenGL曲线函数_2_中点画圆算法
中点画圆算法 如同光栅画线算法,我们在每一个步中以单位间隔取样并确定离指定圆近期的像素位置.对于给定半径r和屏幕中心(xc,yc),能够先使用算法计算圆心在坐标原点(0, 0)的圆的像素 ...
- CAN协议学习(一)协议介绍
一.简介 CAN 是 Controller Area Network 的缩写(以下称为 CAN),是 ISO 国际标准化的串行通信协议. 在当前的汽车产业中,出于对安全性.舒适性.方便性.低公害.低成 ...
- Android linux kernel privilege escalation vulnerability and exploit (CVE-2014-4322)
In this blog post we'll go over a Linux kernel privilege escalation vulnerability I discovered which ...
- Linux与本地上传下载文件
当出于安全原因,客户的服务器不允许使用windows第三方插件连接的时候,本地windows跟远程的linux服务器进行文件的上下传受到了限制,此时可以在linux服务器上安装一个工具:lrzsz.安 ...
- 数字证书转换cer---pem
下载openssl-1.0.1s 安装好openssl之后,进入openssl目录: 输入openssl命令,即进入命令模式: 先将要转换的cer证书也放到openssl目录下面,然后执行以下 ...