大数据学习环境搭建(CentOS6.9+Hadoop2.7.3+Hive1.2.1+Hbase1.3.1+Spark2.1.1)
|
node1 192.168.1.11 |
node2 192.168.1.12 |
node3 192.168.1.13 |
备注 | ||
|
NameNode |
Hadoop |
Y |
Y |
高可用 | |
|
DateNode |
Y |
Y |
Y |
||
|
ResourceManager |
Y |
Y |
高可用 | ||
| NodeManager |
Y |
Y |
Y |
||
|
JournalNodes |
Y |
Y |
Y |
奇数个,至少3个节点 | |
| ZKFC(DFSZKFailoverController) |
Y |
Y |
有namenode的地方就有ZKFC | ||
|
QuorumPeerMain |
Zookeeper |
Y |
Y |
Y |
|
|
MySQL |
HIVE |
Y |
Hive元数据库 | ||
|
Metastore(RunJar) |
Y |
||||
|
HIVE(RunJar) |
Y |
||||
| HMaster | HBase | Y | Y | 高可用 | |
| HRegionServer | Y | Y | Y | ||
|
Spark(Master) |
Spark |
Y |
Y |
高可用 | |
|
Spark(Worker) |
Y |
Y |
Y |
以前搭建过一套,带Federation,至少需4台机器,过于复杂,笔记本也吃不消。现为了学习Spark2.0版本,决定去掉Federation,简化学习环境,不过还是完全分布式
apache-ant-1.9.9-bin.tar.gzapache-hive-1.2.1-bin.tar.gzapache-maven-3.3.9-bin.tar.gzapache-tomcat-6.0.44.tar.gzCentOS-6.9-x86_64-minimal.isofindbugs-3.0.1.tar.gzhadoop-2.7.3-src.tar.gzhadoop-2.7.3.tar.gzhadoop-2.7.3(自已编译的centOS6.9版本).tar.gzhbase-1.3.1-bin(自己编译).tar.gzhbase-1.3.1-src.tar.gzjdk-8u121-linux-x64.tar.gzmysql-connector-java-5.6-bin.jarprotobuf-2.5.0.tar.gzscala-2.11.11.tgzsnappy-1.1.3.tar.gzspark-2.1.1-bin-hadoop2.7.tgz
关闭防火墙
zookeeper

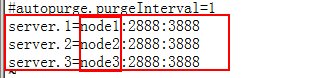


环境变量
export JAVA_HOME=/root/jdk1.8.0_121export SCALA_HOME=/root/scala-2.11.11export HADOOP_HOME=/root/hadoop-2.7.3export HIVE_HOME=/root/apache-hive-1.2.1-binexport HBASE_HOME=/root/hbase-1.3.1export SPARK_HOME=/root/spark-2.1.1-bin-hadoop2.7export PATH=.:$PATH:$JAVA_HOME/bin:$SCALA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:/root:$HIVE_HOME/bin:$HBASE_HOME/bin:$SPARK_HOMEexport CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
Hadoop
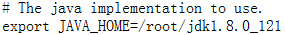

<property><name>dfs.replication</name><value>2</value></property><property><name>dfs.blocksize</name><value>64m</value></property><property><name>dfs.permissions.enabled</name><value>false</value></property><property><name>dfs.nameservices</name><value>mycluster</value></property><property><name>dfs.ha.namenodes.mycluster</name><value>nn1,nn2</value></property><property><name>dfs.namenode.rpc-address.mycluster.nn1</name><value>node1:8020</value></property><property><name>dfs.namenode.rpc-address.mycluster.nn2</name><value>node2:8020</value></property><property><name>dfs.namenode.http-address.mycluster.nn1</name><value>node1:50070</value></property><property><name>dfs.namenode.http-address.mycluster.nn2</name><value>node2:50070</value></property><property><name>dfs.namenode.shared.edits.dir</name><value>qjournal://node1:8485;node2:8485;node3:8485/mycluster</value></property><property><name>dfs.journalnode.edits.dir</name><value>/root/hadoop-2.7.3/tmp/journal</value></property><property><name>dfs.ha.automatic-failover.enabled.mycluster</name><value>true</value></property><property><name>dfs.client.failover.proxy.provider.mycluster</name><value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value></property><property><name>dfs.ha.fencing.methods</name><value>sshfence</value></property><property><name>dfs.ha.fencing.ssh.private-key-files</name><value>/root/.ssh/id_rsa</value></property>
<property><name>fs.defaultFS</name><value>hdfs://mycluster</value></property><property><name>hadoop.tmp.dir</name><value>/root/hadoop-2.7.3/tmp</value></property><property><name>ha.zookeeper.quorum</name><value>node1:2181,node2:2181,node3:2181</value></property>
node1node2node3
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property><property><name>mapreduce.jobhistory.address</name><value>node1:10020</value></property><property><name>mapreduce.jobhistory.webapp.address</name><value>node1:19888</value></property><property><name>mapreduce.jobhistory.max-age-ms</name><value>6048000000</value></property></configuration>
<property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name><value>org.apache.hadoop.mapred.ShuffleHandler</value></property><property><name>yarn.resourcemanager.ha.enabled</name><value>true</value></property><property><name>yarn.resourcemanager.cluster-id</name><value>yarn-cluster</value></property><property><name>yarn.resourcemanager.ha.rm-ids</name><value>rm1,rm2</value></property><property><name>yarn.resourcemanager.hostname.rm1</name><value>node1</value></property><property><name>yarn.resourcemanager.hostname.rm2</name><value>node2</value></property><property><name>yarn.resourcemanager.webapp.address.rm1</name><value>node1:8088</value></property><property><name>yarn.resourcemanager.webapp.address.rm2</name><value>node2:8088</value></property><property><name>yarn.resourcemanager.zk-address</name><value>node1:2181,node2:2181,node3:2181</value></property><property><name>yarn.resourcemanager.recovery.enabled</name><value>true</value></property><property><name>yarn.resourcemanager.store.class</name><value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value></property><property><name>yarn.log-aggregation-enable</name><value>true</value></property><property><name>yarn.log.server.url</name><value>http://node1:19888/jobhistory/logs</value></property>

启动ZK



格式化zkfc

启动journalnode
Namenode格式化和启动
启动zkfc
启动datanode
启动yarn
安装MySQL
[root@node1 ~]# mysql -h localhost -u root -p
[client]default-character-set=utf8[mysql]default-character-set=utf8[mysqld]character-set-server=utf8lower_case_table_names = 1
HIVE安装
Hbase编译安装
<property><name>hbase.rootdir</name><value>hdfs://mycluster:8020/hbase</value></property><property><name>hbase.cluster.distributed</name><value>true</value></property><property><name>hbase.zookeeper.quorum</name><value>node1:2181,node2:2181,node3:2181</value></property><property><name>hbase.master.port</name><value>60000</value></property><property><name>hbase.master.info.port</name><value>60010</value></property>
node1node2node3
# Configure PermSize. Only needed in JDK7. You can safely remove it for JDK8+
#export HBASE_MASTER_OPTS="$HBASE_MASTER_OPTS -XX:PermSize=128m -XX:MaxPermSize=128m"#export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS -XX:PermSize=128m -XX:MaxPermSize=128m"
spark
export SCALA_HOME=/root/scala-2.11.11export JAVA_HOME=/root/jdk1.8.0_121export HADOOP_HOME=/root/hadoop-2.7.3export HADOOP_CONF_DIR=/root/hadoop-2.7.3/etc/hadoopexport SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node1:2181,node2:2181,node3:2181 -Dspark.deploy.zookeeper.dir=/spark"
node1node2node3
./start.sh
./stop.sh
./shutdown.sh
./reboot.sh
大数据学习环境搭建(CentOS6.9+Hadoop2.7.3+Hive1.2.1+Hbase1.3.1+Spark2.1.1)的更多相关文章
- 虚拟机CentOs的安装及大数据的环境搭建
大数据问题汇总 1.安装问题 1.安装步骤,详见文档<centos虚拟机安装指南> 2.vi编辑器使用问题,详见文档<linux常用命令.pd ...
- windows下大数据开发环境搭建(2)——Hadoop环境搭建
一.所需环境 ·Java 8 二.Hadoop下载 http://hadoop.apache.org/releases.html 三.配置环境变量 HADOOP_HOME: C:\hadoop- Pa ...
- windows下大数据开发环境搭建(1)——Java环境搭建
一.Java 8下载 https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html 下载之后 ...
- windows下大数据开发环境搭建(4)——Spark环境搭建
一.所需环境 · Java 8 · Python 2.6+ · Scala · Hadoop 2.7+ 二.Spark下载与解压 http://spark.apache.org/downloads.h ...
- windows下大数据开发环境搭建(3)——Scala环境搭建
一.所需环境 ·Java 8 二.下载Scala https://www.scala-lang.org/download/ 三.配置环境变量 SCALA_HOME: C:\scala Path: ...
- windows下大数据开发环境搭建(1)——Hadoop环境搭建
所需环境 jdk 8 Hadoop下载 http://hadoop.apache.org/releases.html 配置环境变量 HADOOP_HOME: C:\hadoop-2.7.7 Path: ...
- 大数据_zookeeper环境搭建中的几个坑
文章目录 [] Zookeeper简介 关于zk的介绍, zk的paxos算法, 网上已经有各位大神在写了, 本文主要写我在搭建过程中的几个极有可能遇到的坑. Zookeeper部署中的坑 坑之一 E ...
- 大数据学习之路-Centos6安装python3.5
Centos 6.8安装python3.5.2 因为学习所需,需要用到python3.x的环境,目前Linux系统默认的版本都是python2.x的,还有一些自带的工具需要用到python2.6版本, ...
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
随机推荐
- LVM管理之减少LV的大小
LVM管理之减少LV的大小 规定动作 1.umount filesystem 2.e2fsck filesystem 3.resize2fs filesystem 4.lvredure 实例演示——— ...
- net core体系-web应用程序-4net core2.0大白话带你入门-8asp.net core 内置DI容器(DependencyInjection,控制翻转)的一点小理解
asp.net core 内置DI容器的一点小理解 DI容器本质上是一个工厂,负责提供向它请求的类型的实例. .net core内置了一个轻量级的DI容器,方便开发人员面向接口编程和依赖倒置(IO ...
- lvs-dr
第5节 dr模型 在rs上配置 :rip 和vip vip定义在lo别名上 Director 上配置:vip 和dip 都只需要一块网卡 网卡都桥接 Vip: 192.168.0.105 ...
- Codeforces 596D Wilbur and Trees dp (看题解)
一直在考虑, 每一段的贡献, 没想到这个东西能直接dp..因为所有的h都是一样的. #include<bits/stdc++.h> #define LL long long #define ...
- Java中用Scanner扫描控制台输入时的一个小问题
package com.hxl; import java.util.Scanner; public class Test { public static void main(String[] args ...
- windows下编译php7图形库php_ui.dll
CSDN博客 具有图形化编程才有意思,这几天看到了php ui 图形扩展,只是现在只能下载php 7.1的 本次教程编译php7.2.6的 php ui 要是linux下编译起来比较简单 但是 win ...
- How to check for null/empty/whitespace values with a single test?
SELECT column_name FROM table_name WHERE TRIM(column_name) IS NULL
- Java笔记(一)编程基础与二进制
编程基础与二进制 一.编程基础 函数调用的基本原理: 函数调用中的问题: 1)参数如何传递? 2)函数如何知道返回什么地方? 3)函数结果如何传递给调用方? 解决思路是使用内存来函数调用过程中需要的数 ...
- [蓝点ZigBee] Zstack 之点亮OLED液晶 ZigBee/CC2530 视频资料
这一小节主要演示如何在Zstack 下移植液晶驱动,我们选取了目前比较流行的OLED 作为移植目标. 移植关键点 1 修改 GPIO pin, 2 如何将Zstack ...
- 潭州课堂25班:Ph201805201 爬虫高级 第八课 AP抓包 SCRAPY 的图片处理 (课堂笔记)
装好模拟器设置代理到 Fiddler 中, 代理 IP 是本机 IP, 端口是 8888, 抓包 APP斗鱼 用 format 设置翻页