146. LRU缓存机制
题目描述
运用你所掌握的数据结构,设计和实现一个LRU (最近最少使用) 缓存机制。它应该支持以下操作: 获取数据 get 和 写入数据 put 。
- 获取数据
get(key)- 如果密钥 (key) 存在于缓存中,则获取密钥的值(总是正数),否则返回 -1。 - 写入数据
put(key, value)- 如果密钥不存在,则写入其数据值。当缓存容量达到上限时,它应该在写入新数据之前删除最近最少使用的数据值,从而为新的数据值留出空间。
进阶:
你是否可以在 O(1) 时间复杂度内完成这两种操作?
示例:
LRUCache cache = new LRUCache( 2 /* 缓存容量 */ );
cache.put(1, 1);
cache.put(2, 2);
cache.get(1); // 返回 1
cache.put(3, 3); // 该操作会使得密钥 2 作废
cache.get(2); // 返回 -1 (未找到)
cache.put(4, 4); // 该操作会使得密钥 1 作废
cache.get(1); // 返回 -1 (未找到)
cache.get(3); // 返回 3
cache.get(4); // 返回 4
算法
这题的时间复杂度的好坏比较依赖于所选择的数据结构。
LRU是操作系统中提出的一种应用于页置换的算法,这里不过多介绍,举个实际例子即可知道本题要求实现的功能需要什么步骤:
想象有一个队列的最大允许空间为3,
依次入队的顺序为 2,3,2,1,2,4;求LRU算法下队列的演变过程。
---------------------------------------------------
- 队列初始为空,2进入后队列情况为:2
- 队列还有2个剩余位置,3进入后队列情况为:2 3
- 队列还有1个剩余位置,这次入队的数据为2,它本来就已在队列中,根据LRU算法,需要将2调到队列末尾,因此队列情况为:3 2
- 队列还有1个剩余位置,这次入队数据为1,入队后队列情况为:2 3 1
- 队列已经没有剩余位置,但是入队数据为2,它本来就在队列中,根据LRU算法,需要将2调到队列末尾,因此队列情况为:3 1 2
- 队列已经没有剩余位置,新进入的数据为4,根据LRU需要淘汰最近最少被使用的数据,即队首的数据3,更新后队列情况为:1 2 4
---------------------------------------------------
上面即为LRU算法的一个例子
选择hash表与双向链表作为实现主体功能的两个数据结构,主要是因为双向链表便于插入删除,而hash表可以较快查找到需要返回的value。具体一点,整个LRUCache可能长下面这样:
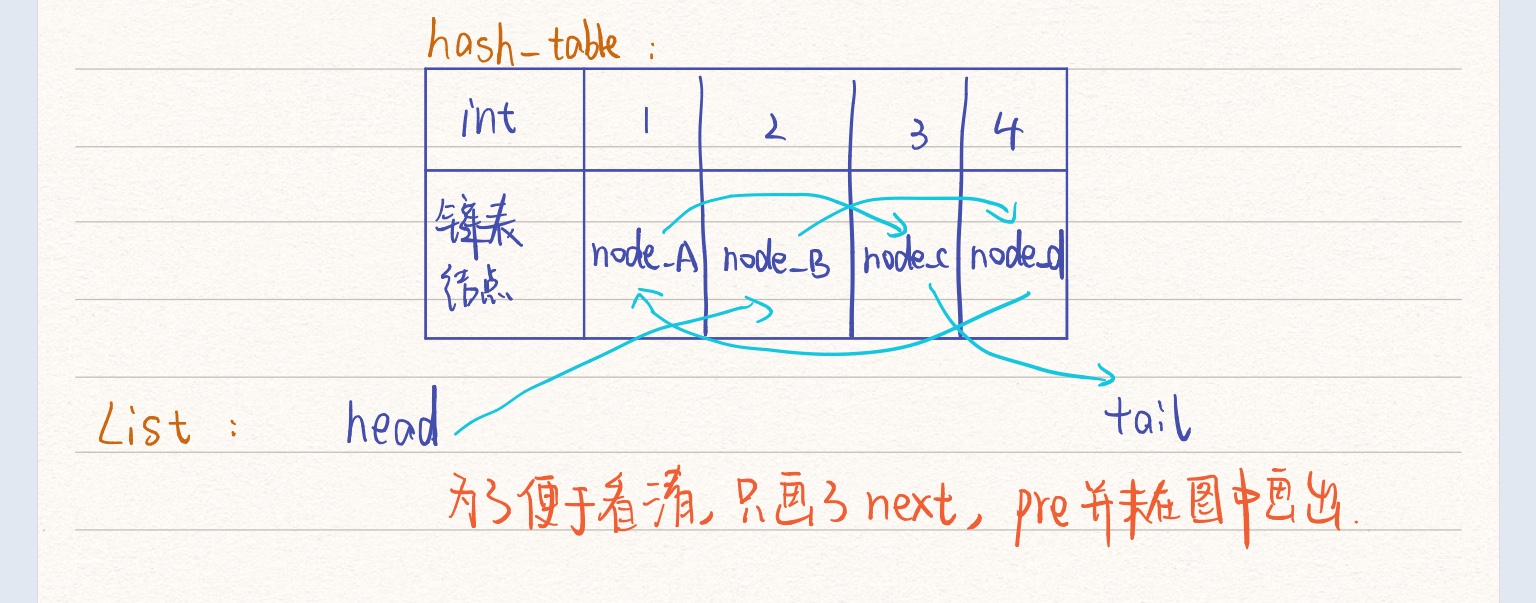
代码
#include <iostream>
#include <list>
#include <unordered_map>
using namespace std;
struct listNode{
int key, value;
listNode *pre, *next;
listNode(int _key, int _value): key(_key), value(_value)
{
pre = next = NULL;
}
};
class LRUCache {
public:
// hash_table末端保存最近刚被使用的节点,前端保存最近最少被使用节点
unordered_map<int, listNode*> hash_table;
listNode *head, *tail;
int cap, size;
LRUCache(int capacity) {
cap = capacity;
size = 0;
head = new listNode(-1, -1);
tail = new listNode(-1, -1);
head->next = tail;
tail->pre = head;
}
int get(int key) {
if (hash_table.find(key) == hash_table.end())
return -1;
else
{
// 记录该ID指向节点的指针
listNode *tmp = hash_table[key];
/*** 更改节点在表中的顺序 ***/
// 1. 删除hash_table[key]
delNode(tmp);
// 2. 将hash_table[key]插入末尾
pushNodeBack(tmp);
return tmp->value;
}
}
void put(int key, int value) {
// 这个key本身保存在表中
if (hash_table.find(key) != hash_table.end())
{
listNode *tmp = hash_table[key];
// 从链表头部去掉这个点
delNode(tmp);
// 更新表中key对应链表节点的value
tmp->value = value;
// 从链表尾部插入这个点
pushNodeBack(tmp);
return;
}
// 链表的空间已满
if (cap == size)
{
// 空间不够,踢出队列最前端的ID
listNode *tmp = head->next;
// 在表中删除这个点
hash_table.erase(tmp->key);
// 从链表头部去掉这个点
delNode(tmp);
// 释放被删除的点的空间
delete tmp;
}
else
size++;
listNode *node = new listNode(key, value);
hash_table[key] = node;
pushNodeBack(node);
}
void delNode(listNode *node)
{
node->pre->next = node->next;
node->next->pre = node->pre;
}
void pushNodeBack(listNode *node)
{
tail->pre->next = node;
node->pre = tail->pre;
node->next = tail;
tail->pre = node;
}
};
int main()
{
LRUCache *cache = new LRUCache(2);
cache->put(1, 1);
cache->put(2, 2);
cout << cache->get(1) << endl; // 返回 1
cache->put(3, 3); // 该操作会使得密钥 2 作废
cout << cache->get(2) << endl; // 返回 -1 (未找到)
cache->put(4, 4); // 该操作会使得密钥 1 作废
cout << cache->get(1) << endl; // 返回 -1
cout << cache->get(3) << endl; // 返回 3
cout << cache->get(4) << endl; // 返回 4
}
146. LRU缓存机制的更多相关文章
- Java实现 LeetCode 146 LRU缓存机制
146. LRU缓存机制 运用你所掌握的数据结构,设计和实现一个 LRU (最近最少使用) 缓存机制.它应该支持以下操作: 获取数据 get 和 写入数据 put . 获取数据 get(key) - ...
- 力扣 - 146. LRU缓存机制
目录 题目 思路 代码 复杂度分析 题目 146. LRU缓存机制 思路 利用双链表和HashMap来解题 看到链表题目,我们可以使用头尾结点可以更好进行链表操作和边界判断等 还需要使用size变量来 ...
- 146. LRU 缓存机制 + 哈希表 + 自定义双向链表
146. LRU 缓存机制 LeetCode-146 题目描述 题解分析 java代码 package com.walegarrett.interview; /** * @Author WaleGar ...
- 【golang必备算法】 Letecode 146. LRU 缓存机制
力扣链接:146. LRU 缓存机制 思路:哈希表 + 双向链表 为什么必须要用双向链表? 因为我们需要删除操作.删除一个节点不光要得到该节点本身的指针,也需要操作其前驱节点的指针,而双向链表才能支持 ...
- [Leetcode]146.LRU缓存机制
Leetcode难题,题目为: 运用你所掌握的数据结构,设计和实现一个 LRU (最近最少使用) 缓存机制.它应该支持以下操作: 获取数据 get 和 写入数据 put . 获取数据 get(key ...
- 【力扣】146. LRU缓存机制
运用你所掌握的数据结构,设计和实现一个 LRU (最近最少使用) 缓存机制.它应该支持以下操作: 获取数据 get 和 写入数据 put . 获取数据 get(key) - 如果关键字 (key) ...
- leetcode:146. LRU缓存机制
题目描述: 运用你所掌握的数据结构,设计和实现一个 LRU (最近最少使用) 缓存机制.它应该支持以下操作: 获取数据 get 和 写入数据 put . 获取数据 get(key) - 如果密钥 ( ...
- LeetCode 146. LRU缓存机制(LRU Cache)
题目描述 运用你所掌握的数据结构,设计和实现一个 LRU (最近最少使用) 缓存机制.它应该支持以下操作: 获取数据 get 和 写入数据 put . 获取数据 get(key) - 如果密钥 (k ...
- Leetcode 146. LRU 缓存机制
前言 缓存是一种提高数据读取性能的技术,在计算机中cpu和主内存之间读取数据存在差异,CPU和主内存之间有CPU缓存,而且在内存和硬盘有内存缓存.当主存容量远大于CPU缓存,或磁盘容量远大于主存时,哪 ...
随机推荐
- linux之用户密码破解的操作
一 无引导介质救援模式破解root用户密码 1 启动虚拟用户,在GRUB启动画面停留的那段时间,用上下键选择启动项. 2 用‘e’键进入你选择的启动项 ,然后用上下键将光标移动到“linux16... ...
- (21)The history of human emotions
https://www.ted.com/talks/tiffany_watt_smith_the_history_of_human_emotions/transcript00:12I would li ...
- save to project-level dictionary? save to application-level dictionary?
通过静态代码分析工具lint在Spelling typo得到save to project-level dictionary? save to application-level dictionary ...
- visual studio 2013怎样快速查看代码函数关系--代码图
可以发现没有调试运行代码时是无法查看代码图的,可以在某行加一个断点,如下图,并开始debug调试: 这时,就会在代码调试工具栏看到代码图按钮,点击它: 右边就会出现代码图了: 这下就方便多了. 不仅适 ...
- 后台获取url里面加密的参数中,特殊符号+获取到后端后是 一个空格的解决方法
进行加密,加密后的参数中有个+号: 前端的url:http://mtest.cmread.com:8145/nap/p/QRcode.jsp?activityId=11206&vcode=O/ ...
- C#延时函数
用Thread方法: 先using system.threading; 再在需要延时的进程处插入 thread.sleep(int);
- Day02 (黑客成长日记)
#用户登录次数为三代码 # i = 0 # while i < 3: # username = input('请输入账号:') # password = input('请输入密码:') # if ...
- [ 9.24 ]CF每日一题系列—— 468A构造递推
Description: 1 - n个数问你能否经过加减乘除这些运算n -1次的操作得到24 Solutrion: 一开始想暴力递推,发现n的范围太大直接否决,也否决了我的跑dfs,后来就像肯定有个递 ...
- 迁移桌面程序到MS Store(1)——通过Visual Studio创建Packaging工程
之前跑去做了一年多的iOS开发,被XCode恶心得不行.做人呢,最重要的是开心.所以我就炒了公司鱿鱼,挪了个窝回头去做Windows开发了. UWP什么的很久没有正儿八经写了,国内的需求 ...
- 杂七杂八的JavaScript
一.input 焦点定位 1.定位input:(this.$refs.searchInput as HTMLInputElement).focus(); 2.定位search,根据css选择器: ...