如何把数据快速批量添加到Elasticsearch中
问题来源
最近新做一个项目,有部分搜索比较频繁的数据,而且量级比较大,预计一两年时间很可能达到100G,项目要求不要存在数据库中,最终出来有两个方案,一个是使用Protocol Buffers存储在文件上,另外就是存在Elasticsearch中,也方便搜索,但这两个方案需要验证,到底哪个方案好,从存储速度,搜索响应,占用空间方面做对比,而我负责给出Elasticsearch的部分技术建议!
验证需求
1、数据量:初步只算52亿条
2、写数据速度:需要超过1W条每秒
遇到问题以及解决办法
而在验证过程中遇到了无论是使用Elasticsearch.Net或者PlainElastic.Net来写数据,并且是使用了Bulk的api,加上多线程,都是太慢了,粗略算了一下,大概一秒插入3千条左右,这样的话,52亿条数据,得插到何年何月啊,太慢了,根据查阅资料,网上也有人说插入数据还是挺快 的,一秒可以插入18w条,但具体也没说是用什么办法插入的,所以只能到官方看看了,发现用REST API的_bulk来批量插入,这样速度明显快了,可以达到5到10w条每秒,速度还可以,但问题是这方法是先定义一定格式的json文件,然后再用curl命令去执行Elasticsearch的_bulk来批量插入,所以得把数据写进json文件,然后再通过批处理,执行文件插入数据,另外在生成json文件,文件不能过大,过大会报错,所以建议生成10M一个文件,然后分别去执行这些小文件就可以了,说了这么多都是文字,真的有点晕乎乎的,看图吧!
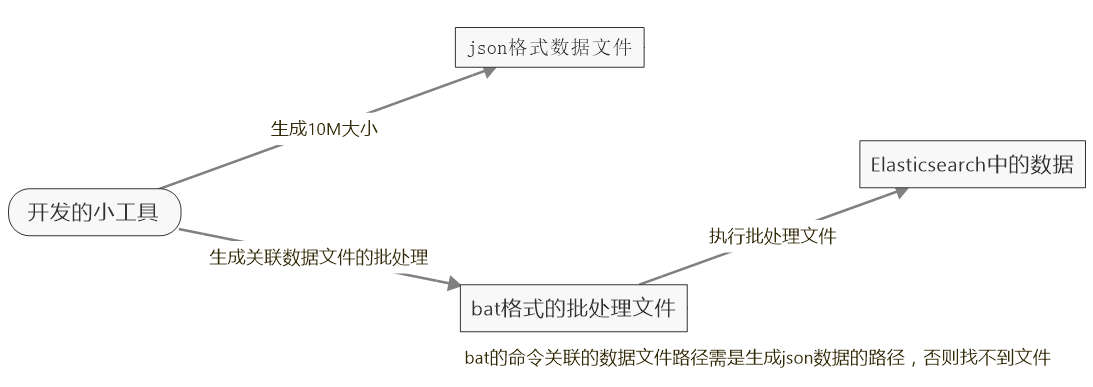
json数据文件内容的定义
{"index":{"_index":"meterdata","_type":"autoData"}}
{"Mfid ":1,"TData":172170,"TMoney":209,"HTime":"2016-05-17T08:03:00"}
{"index":{"_index":"meterdata","_type":"autoData"}}
{"Mfid ":1,"TData":172170,"TMoney":209,"HTime":"2016-05-17T08:04:00"}
{"index":{"_index":"meterdata","_type":"autoData"}}
{"Mfid ":1,"TData":172170,"TMoney":209,"HTime":"2016-05-17T08:05:00"}
{"index":{"_index":"meterdata","_type":"autoData"}}
{"Mfid ":1,"TData":172170,"TMoney":209,"HTime":"2016-05-17T08:06:00"}
{"index":{"_index":"meterdata","_type":"autoData"}}
{"Mfid ":1,"TData":172170,"TMoney":209,"HTime":"2016-05-17T08:07:00"}
批处理内容的定义
cd E:\curl-7.50.3-win64-mingw\bin
curl 172.17.1.15:9200/_bulk?pretty --data-binary @E:\Bin\Debug\testdata\437714060.json
curl 172.17.1.15:9200/_bulk?pretty --data-binary @E:\Bin\Debug\testdata\743719428.json
curl 172.17.1.15:9200/_bulk?pretty --data-binary @E:\Bin\Debug\testdata\281679894.json
curl 172.17.1.15:9200/_bulk?pretty --data-binary @E:\Bin\Debug\testdata\146257480.json
curl 172.17.1.15:9200/_bulk?pretty --data-binary @E:\Bin\Debug\testdata\892018760.json
pause
工具代码
private void button1_Click(object sender, EventArgs e)
{
//Application.StartupPath + "\\" + NextFile.Name
Task.Run(() => { CreateDataToFile(); });
}
public void CreateDataToFile()
{
StringBuilder sb = new StringBuilder();
StringBuilder sborder = new StringBuilder();
int flag = ;
sborder.Append(@"cd E:\curl-7.50.3-win64-mingw\bin" + Environment.NewLine);
DateTime endDate = DateTime.Parse("2016-10-22");
for (int i = ; i <= ; i++)//1w个点
{
DateTime startDate = DateTime.Parse("2016-10-22").AddYears(-);
this.Invoke(new Action(() => { label1.Text = "生成第" + i + "个"; })); while (startDate <= endDate)//每个点生成一年数据,每分钟一条
{
if (flag > )//大于10w分割一个文件
{
string filename = new Random(GetRandomSeed()).Next() + ".json"; FileStream fs3 = new FileStream(Application.StartupPath + "\\testdata\\" + filename, FileMode.OpenOrCreate);
StreamWriter sw = new StreamWriter(fs3, Encoding.GetEncoding("GBK"));
sw.WriteLine(sb.ToString());
sw.Close();
fs3.Close();
sb.Clear();
flag = ;
sborder.Append(@"curl 172.17.1.15:9200/_bulk?pretty --data-binary @E:\Bin\Debug\testdata\" + filename + Environment.NewLine); }
else
{
sb.Append("{\"index\":{\"_index\":\"meterdata\",\"_type\":\"autoData\"}}" + Environment.NewLine);
sb.Append("{\"Mfid \":" + i + ",\"TData\":" + new Random().Next() + ",\"TMoney\":" + new Random().Next() + ",\"HTime\":\"" + startDate.ToString("yyyy-MM-ddTHH:mm:ss") + "\"}" + Environment.NewLine);
flag++;
}
startDate = startDate.AddMinutes();//
} }
sborder.Append("pause");
FileStream fs1 = new FileStream(Application.StartupPath + "\\testdata\\order.bat", FileMode.OpenOrCreate);
StreamWriter sw1 = new StreamWriter(fs1, Encoding.GetEncoding("GBK"));
sw1.WriteLine(sborder.ToString());
sw1.Close();
fs1.Close();
MessageBox.Show("生成完毕"); }
static int GetRandomSeed()
{//随机生成不重复的编号
byte[] bytes = new byte[];
System.Security.Cryptography.RNGCryptoServiceProvider rng = new System.Security.Cryptography.RNGCryptoServiceProvider();
rng.GetBytes(bytes);
return BitConverter.ToInt32(bytes, );
}
总结
本次测试结果,发现Elasticsearch的搜索速度是挺快的,生成过程中,在17亿数据时查了一下,根据Mid和时间在几个月范围的数据,查十条数据两秒多完成查询,而且同一查询条件查询越多,查询就越快,应该是Elasticsearch缓存了,52亿条数据,大概占用500G空间左右,还是挺大的,相比Protocol Buffers存储的数据,要大三倍左右,但搜索速度还是比较满意的。

%6A`Q}D$`GS0M%4.png)
如何把数据快速批量添加到Elasticsearch中的更多相关文章
- 数据快速批量添加到Elasticsearch
如何把数据快速批量添加到Elasticsearch中 问题来源 最近新做一个项目,有部分搜索比较频繁的数据,而且量级比较大,预计一两年时间很可能达到100G,项目要求不要存在数据库中,最终出来有两个方 ...
- 将数据内容动态添加到HTML中
// 申明一个数组用来装遍历的元素 var li = []; //遍历元素并加载到标签中 for(var i = 0; i<navGroup.self_first_nav.length; i++ ...
- Redis批量执行(如list批量添加)命令工具 —— pipeline管道应用
前言 Redis使用的是客户端-服务器(CS)模型和请求/响应协议的TCP服务器.这意味着通常情况下一个请求会遵循以下步骤: 使用Redis管道提升性能 (1)客户端向服务端发送一个查询请求,并监听S ...
- java操作elasticsearch实现批量添加数据(bulk)
java操作elasticsearch实现批量添加主要使用了bulk 代码如下: //bulk批量操作(批量添加) @Test public void test7() throws IOExcepti ...
- net core天马行空系列-各大数据库快速批量插入数据方法汇总
1.前言 hi,大家好,我是三合.我是怎么想起写一篇关于数据库快速批量插入的博客的呢?事情起源于我们工作中的一个需求,简单来说,就是有一个定时任务,从数据库里获取大量数据,在应用层面经过处理后再把结果 ...
- EF批量添加数据性能慢的问题的解决方案
//EF批量添加数据性能慢的问题的解决方案 public ActionResult BatchAdd() { using (var db = new ToneRoad.CEA.DbContext.Db ...
- Java使用Mysql数据库实现批量添加数据
EmployeeDao.java //批处理添加数据 public int saveEmploeeBatch(){ int row = 0; try{ con = DBCon.getConn(); S ...
- .Net中批量添加数据的几种实现方法比较
在.Net中经常会遇到批量添加数据,如将Excel中的数据导入数据库,直接在DataGridView控件中添加数据再保存到数据库等等. 方法一:一条一条循环添加 通常我们的第一反应是采用for或for ...
- ThinkPHP批量添加数据和getField()示例
批量添加数据 // 批量添加数据 $User = M('users'); $dataList[] = array('name'=>'thinkphp','email'=>'thinkphp ...
随机推荐
- Win10上启动UICrawler自动遍历时报 "org.openqa.selenium.WebDriverException: An unknown server-side error occur red while processing the command. Original error: Could not sign with default certifi cate."
操作步骤: 1.直接启动 Appium (我用的是 version 1.10.0) 2.打开命令窗口,切换到 UICrawler 所在路径 3.执行命令 java -jar UICrawler-2.2 ...
- v-bind指令动态绑定class和内联样式style
动态绑定class—概述 数据绑定(v-bind指令)一个常见需求是操作元素的 class 列表.因为class是元素的一个属性,我们可以用 v-bind 处理它们 我们只需要计算出表达式最终的字符串 ...
- yii2 修改验证码小部件样式
<?= $form->field($model, 'verifyCode',['labelOptions' => ['class' => 'yanzhengma','style ...
- 转载 三、并行编程 - Task同步机制。TreadLocal类、Lock、Interlocked、Synchronization、ConcurrentQueue以及Barrier等
随笔 - 353, 文章 - 1, 评论 - 5, 引用 - 0 三.并行编程 - Task同步机制.TreadLocal类.Lock.Interlocked.Synchronization.Conc ...
- Jmeter之tomcat性能测试+性能改进措施
Jmeter用于tomcat性能测试,因为项目部署在tomcat,正常情况下,一个tomcat可以承受500个并发,通过修改配置,及其相关的tomcat优化,可以承受到1000个并发. 如何测试tom ...
- Android学习之基础知识十一 —运用手机多媒体
一.使用通知(Notification) 通知(Notification)是Android系统中比较有特色的一个功能,当某个应用程序希望向用户发出一些提示信息,而该应用程序又不在前台运行时,就可以借助 ...
- 循环神经网络RNN的基本介绍
本博客适合那些BP网络很熟悉的读者 一 基本结构和前向传播 符号解释: 1. $c_{t}^{l}$:t时刻第l层的神经元的集合,因为$c_{t}^{l}$表示的是一层隐藏层,所以图中一个圆圈表示多个 ...
- odoo系统之产品表
# 输入产品带出它默认的包装方式\单位\品名\规格 def get_product_unit(self, cr, uid,ids,product_id,pcust_order_no,pdate_pla ...
- BZOJ 2784 时间流逝
BZOJ 2784 时间流逝 古典概率论... 可以发现由于能量圈数量限制,所以所构成的必定为树状结构(即便是转成最小能量圈和能量圈权值和之后存在重复状态,但是每个状态的含义不同,而且不能自身转移自身 ...
- SPOJ GSS(Can you answer the Queries)系列 7/8
GSS1 线段树最大子段和裸题,不带修改,注意pushup. 然而并不会猫树之类的东西 #include<bits/stdc++.h> #define MAXN 50001 using n ...