论文笔记:Concept Mask: Large-Scale Segmentation from Semantic Concepts
Concept Mask: Large-Scale Segmentation from Semantic Concepts
2018-08-21 11:16:07
Paper:https://arxiv.org/pdf/1808.06032.pdf
本文做了这么一件事:给定一张图片以及概念名词,输出其对应的分割结果,如下图所示:
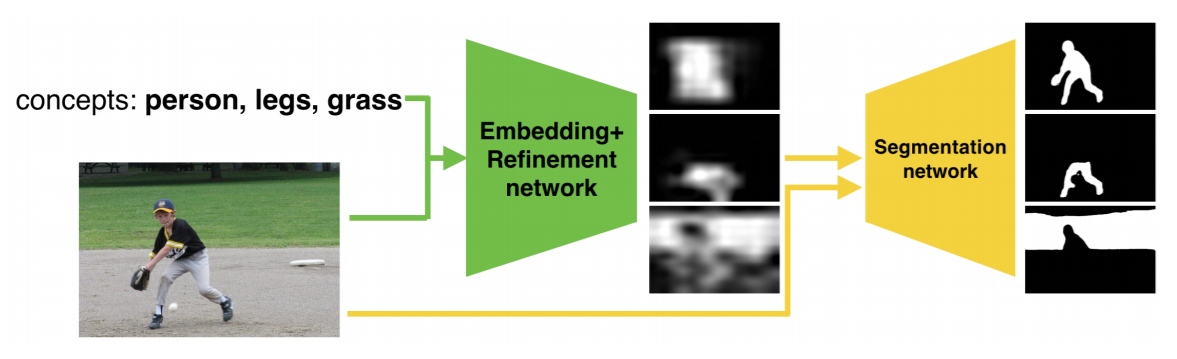
具体来说,这个流程大致可以分为如下几个部分:
1. Embedding Network 来学习视觉特征和语义概念之间的对应关系;此时,我们可以得到一个粗糙的 attention map;
2. 优化模块,在上一步骤的基础上,利用 BBox 的标注信息,得到高质量的 attention maps;
3. A label agnostic segmentation network,在 COCO-80 分割数据集上进行有监督的训练。这个网络将上述得到的 coarse attention maps,以及原图作为输入,得到最终概念级别的分割结果;
总体的流程图如下:
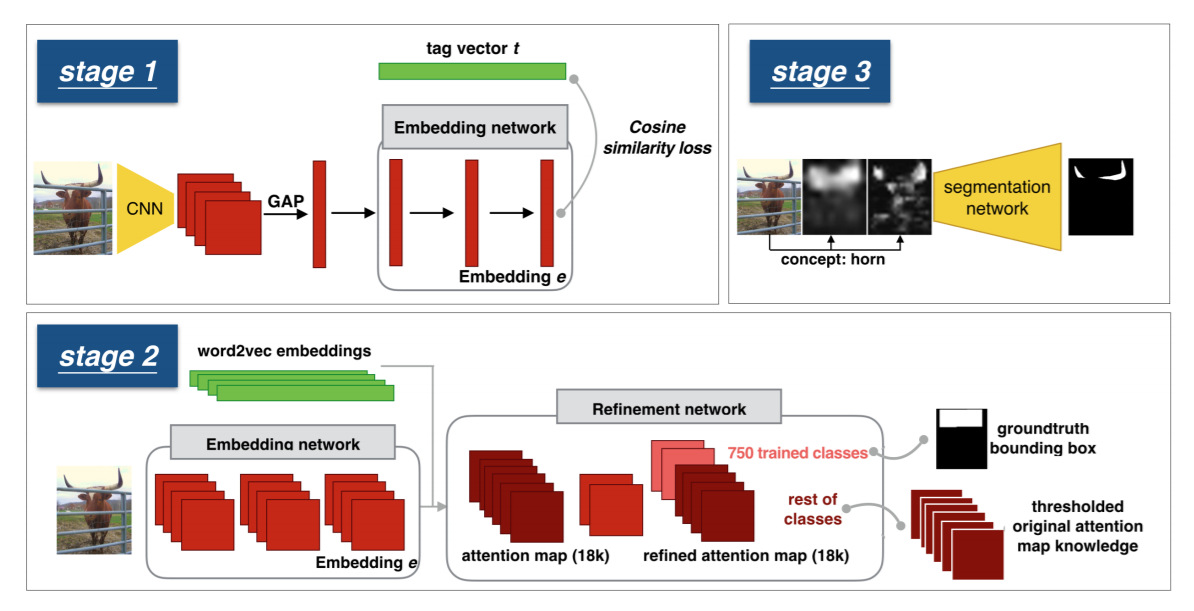
下面分别详细的介绍下对应的每一个模块:
1. Embedding Network:
作者在 Stock-18K dataset 上进行了训练,该数据集包含 6 million images,每一个图像都对应有标注的 tags,有 18K vocabulary。
Word Embedding
有了 tag 的信息,第一步就是将其映射为 vector,与通常直接用 pre-trained Word embedding 的方法不同,本文采用的是:point-wise mutual information (PMI) 来学习我们自己的 Word embedding。当一张图像有多个对应的 label 时,作者采用了常规的 加权平均的方法,得到一个统一的表达,称为:“soft topic embedding”。
Joint Word-Image Embedding
作者用余弦相似性 loss 函数来衡量,visual embedding 与 soft topic word vector 之间的距离:
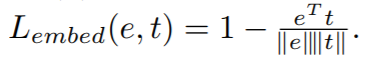
Attention Map
作者用一个全卷机的网络结构,将输入的图像,转换为对应的 attention map;然后计算每一个位置上,图像和单词描述之间的相似度:
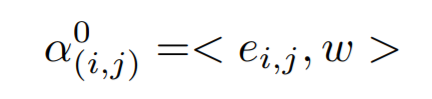
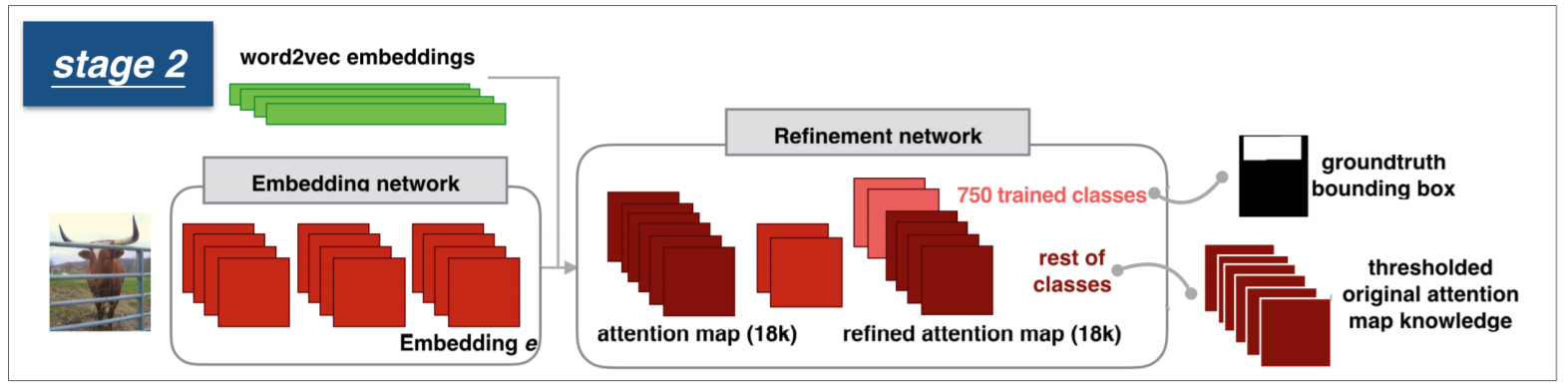
2. Attention Map Refinement
虽然上述过程得到了初始的 attention maps,但是由于缺乏 空间信息的标注,使得该 attention map 非常的粗糙;
Multi-task Training
作者采用了 二元交叉熵损失函数来度量所输出的 maps 和 GT maps 之间的差距:

Spatial Discrimination Loss
作者给出了不采用 softmax loss,而用 binary cross entropy loss 的原因:there are many concepts whose masks are overlapping with each other. 但是,仍然有一些概念,几乎从来不会重合。为了充分利用这种关系,作者提出了一种辅助的 loss 函数,来判断这些空间上不重合的概念,即:spatial discriminatives loss。
特别的,我们统计训练数据中,相互重叠的概念对:
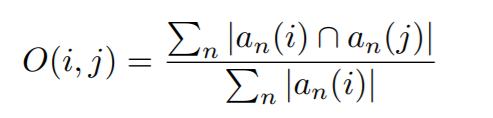
有了这个重叠比例矩阵 O(i, j),那么,我们可以用一个概念 i 的训练样本当做 非重合概念 j 的 negative training example,即:
for a particular location in the image, the output for concept j should be 0 if the ground-truth for concept i is 1.
为了软化这个约束,作者进一步根据重合度,进行了辅助 loss 的加权,权重的计算方法如下:
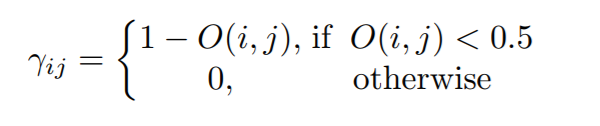
3. Label Agnostic Segmentation Network
为了得到更加精细化的分割结果,像素级的标注信息是必不可少的。所以,这里,作者将上述过程中得到的 coarse maps 以及 原始图像都作为分割网络的输入,然后得到最终精细化的分割结果。
Experiments:


论文笔记:Concept Mask: Large-Scale Segmentation from Semantic Concepts的更多相关文章
- 论文笔记之:Large Scale Distributed Semi-Supervised Learning Using Streaming Approximation
Large Scale Distributed Semi-Supervised Learning Using Streaming Approximation Google 2016.10.06 官方 ...
- 【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 17—Large Scale Machine Learning 大规模机器学习
Lecture17 Large Scale Machine Learning大规模机器学习 17.1 大型数据集的学习 Learning With Large Datasets 如果有一个低方差的模型 ...
- 论文笔记:Mask R-CNN
之前在一次组会上,师弟诉苦说他用 UNet 处理一个病灶分割的任务,但效果极差,我看了他的数据后发现,那些病灶区域比起整张图而言非常的小,而 UNet 采用的损失函数通常是逐像素的分类损失,如此一来, ...
- 论文笔记:Dynamic Multimodal Instance Segmentation Guided by Natural Language Queries
Dynamic Multimodal Instance Segmentation Guided by Natural Language Queries 2018-09-18 09:58:50 Pape ...
- 论文笔记:Capsules for Object Segmentation
Capsules for Object Segmentation 2018-04-16 21:49:14 Introduction: ----
- [论文笔记][半监督语义分割]Universal Semi-Supervised Semantic Segmentation
论文原文原文地址 Motivations 传统的训练方式需要针对不同 domain 的数据分别设计模型,十分繁琐(deploy costs) 语义分割数据集标注十分昂贵,费时费力 Contributi ...
- 论文笔记系列-Auto-DeepLab:Hierarchical Neural Architecture Search for Semantic Image Segmentation
Pytorch实现代码:https://github.com/MenghaoGuo/AutoDeeplab 创新点 cell-level and network-level search 以往的NAS ...
- 大规模视觉识别挑战赛ILSVRC2015各团队结果和方法 Large Scale Visual Recognition Challenge 2015
Large Scale Visual Recognition Challenge 2015 (ILSVRC2015) Legend: Yellow background = winner in thi ...
- 论文笔记之:Natural Language Object Retrieval
论文笔记之:Natural Language Object Retrieval 2017-07-10 16:50:43 本文旨在通过给定的文本描述,在图像中去实现物体的定位和识别.大致流程图如下 ...
随机推荐
- Nest.js 拦截器
Docs: https://docs.nestjs.com/interceptors 该对象包含从路由处理程序返回的值 在方法执行之前/之后绑定额外的逻辑 转换函数返回的结果 转换从函数抛出的异常 / ...
- 【2】static 、construct
[面向对象] 两个概念: 什么是类 具有一批相同属性的集合 什么是对象 特指的某一个具体的事物 [面向对象的三大特征] 1.封装 public 公共的 protected 受保护的 private 私 ...
- js获取谷歌浏览器版本 和 js分辨不同浏览器
// 获取谷歌版本 function getChromeVersion() { var arr = navigator.userAgent.split(' '); var chromeVersion ...
- eclipse测试链接sql server2008 数据库
注:在测试连接数据库之前必须保证SQL Server 2008是采用SQL Server身份验证方式而不是windows身份验证方式.如果在安装时选用了后者,则需要重新进行配置. 首先 使用命令行测试 ...
- python中文分词库——pyltp
pyltp在win10下安装比较麻烦,因此参考以下安装方式, 1.下载 win10下python3.6 2.安装 下载好了以后, 在命令行下, cd到wheel文件所在的目录, 然后使用命令pip i ...
- Oracle课程档案,第十六天
restore:恢复文件 recover: 恢复日志 丢失current日志组(正常关闭数据库):故障:SQL> select group#, status from v$log; 确认curr ...
- soapui调用redis,获取短信验证码
1.首先,调用redis需要引入redis的jar包,放入到soapui指定目录中,例如我的目录D:\Program Files\SmartBear\SoapUI-Pro-5.1.2\bin\ext ...
- ffmpeg的编译和安装
1. 先到ffmpeg官网上下载ffmpeg源码,然后配置.编译 http://ffmpeg.org/download.html 可以如下进行配置: ./configure --prefix=/usr ...
- 【托业】【新东方托业全真模拟】TEST07~08-----P5~6
unless ---conj:barring(除非,不包括)perp+名词短语 be capable of doing 有能力做某事 qualified commensurate with 与……相应 ...
- char 类型的操作函数
1.内存充填 void *memset(void *s,int ch,size_t n); 是由C Run-time Library提供的提供的函数,作用是在一段内存块中填充某个给定的值,它是对较大的 ...