python 之字符编码
一 了解字符编码的储备知识
python解释器和文件本编辑的异同
相同点:python解释器是解释执行文件内容的,因而python解释器具备读py文件的功能,这一点与文本编辑器一样
不同点:文本编辑器将文件内容读入内存后,是为了显示/编辑,而python解释器将文件内容读入内存后,是为了执行(识别python语法)
二 什么是字符编码
字符编码的定义:
所谓的字符编码就是让计算机读懂人类语言的字符
字符编码产生的过程
字符--------(翻译过程)------->数字 这个过程实际就是一个字符如何对应一个特定数字的标准,这个标准称之为字符编码
字符编码的涉及场景
. 一个python文件中的内容是由一堆字符组成的(python文件未执行时) . python中的数据类型字符串是由一串字符组成的(python文件执行时)
三 字符编码发展史
阶段一:现代计算机起源于美国,最早诞生也是基于英文考虑的ASCII
阶段二:为了满足中文,中国人定制了GBK(其他各国为了满足各国的发展需求纷纷制定了自己的字符编码)
阶段三:各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。
于是产生了unicode, 统一用2Bytes代表一个字符, **-=,可代表6万多个字符,因而兼容万国语言 但对于通篇都是英文的文本来说,这种编码方式无疑是多了一倍的存储空间(二进制最终都是以电或者磁的方式存储到存储介质中的) 于是产生了UTF-,对英文字符只用1Bytes表示,对中文字符用3Bytes。unicode 和UTF-8各有优劣 unicode:简单粗暴,所有字符都是2Bytes,优点是字符->数字的转换速度快,缺点是占用空间大 utf-:精准,对不同的字符用不同的长度表示,优点是节省空间,缺点是:字符->数字的转换速度慢,因为每次都需要计算出字符需要多长的Bytes才能够准确表示 **** 所有程序,最终都要加载到内存,程序保存到硬盘不同的国家用不同的编码格式,但是到内存中我们为了兼容万国(计算机可以运行任何国家的程序原因在于此),统一且固定使用unicode,这就是为何内存固定用unicode的原因,你可能会说兼容万国我可以用utf-8啊,可以,完全可以正常工作,之所以不用肯定是unicode比utf-8更高效啊(uicode固定用2个字节编码,utf-8则需要计算),但是unicode更浪费空间,没错,这就是用空间换时间的一种做法,而存放到硬盘,或者网络传输,都需要把unicode转成utf-,因为数据的传输,追求的是稳定,高效,数据量越小数据传输就越靠谱,于是都转成utf-8格式的,而不是unicode。
解决乱码的方法
四 字符编码的类型
ASCII码:
ASCII码是字符编码的鼻祖最早诞生于西方世界,只限于西方世界使用
Unicode码:
又称为万国编码,解决了ASCII码的缺陷,但是占用的内存相对较大
UTF-8:
延续了万国编码的传统,但是解决了万国编码占用内存大的问题
GBK:
只限于中国内部使用的字符编码
各类型字符编码之间的关系
ASCII码是字符编码的鼻祖最早诞生与西方世界,因为只局限与西方世界使用所以诞生了unicode在世界范围内都可以使用但因为占用内存较大所以又诞生了utf-8解决了占用内存较大的问题
Bit,bytes,kb,Mb,GB,TB之间的转换:
8Bit= Bytes 1024bytes=1Kb 1024Kb= mb 1024mb= GB 1024GB=1TB
位和字节的关系
位是最小的二进制内存单位 字节是最小的字符单位 一个字节bytes等于8个位bit
unicode utf-8 gbk编码之间的转换:
编码格式 英文 中文 Unicode 4 utf- gbk
字节和字符串的转换
字符串转换为字节
s = 'hello workd'
res = bytes(s,encoding='utf-8')
print(res)
字节转换为字符串
s = bytes'hello workd'
res = str(s,encoding='utf-8')
print(res)
五 字符编码的使用
文本编译器(以notepadd++为例)
当我们用编译器编译一段对我们有用的信息并且关闭之后 当我们需要的时候打开之后却发现所编译的内容和之前的完全不一样了 会出现大量的乱码。那么为什么会有乱码呢?
一 存文件时就已经乱码
存文件时,由于文件内有各个国家的文字,我们单以shiftjis去存,
本质上其他国家的文字由于在shiftjis中没有找到对应关系而导致存储失败,用open函数的write可以测试,f=open('a.txt','w',encodig='shift_jis')
f.write('你瞅啥\n何を見て\n') #'你瞅啥'因为在shiftjis中没有找到对应关系而无法保存成功,只存'何を見て\n'可以成功
但当我们用文件编辑器去存的时候,编辑器会帮我们做转换,保证中文也能用shiftjis存储(硬存,必然乱码),这就导致了,存文件阶段就已经发生乱码
此时当我们用shiftjis打开文件时,日文可以正常显示,而中文则乱码了
二 存文件时不乱码而读文件时乱码
存文件时用utf-8编码,保证兼容万国,不会乱码,而读文件时选择了错误的解码方式,比如gbk,则在读阶段发生乱码,读阶段发生乱码是可以解决的,选对正确的解码方式就ok了,而存文件时乱码,则是一种数据的损坏。
怎么防止乱码出现?
无论是何种编辑器,要防止文件出现乱码(请一定注意,存放一段代码的文件也仅仅只是一个普通文件而已,此处指的是文件没有执行前,我们打开文件时出现的乱码)
核心法则就是,文件以什么编码保存的,就以什么编码方式打开
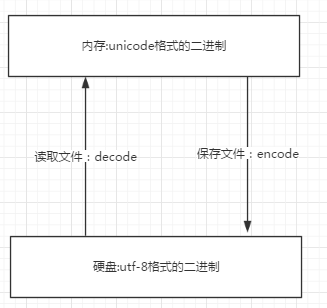
decodeh和encode
首先要搞清楚,字符串在Python内部的表示是unicode编码,因此,在做编码转换时,通常需要以unicode作为中间编码, 即先将其他编码的字符串解码(decode)成unicode,再从unicode编码(encode)成另一种编码
import sys
'''
*首先要搞清楚,字符串在Python内部的表示是unicode编码,因此,在做编码转换时,通常需要以unicode作为中间编码,
即先将其他编码的字符串解码(decode)成unicode,再从unicode编码(encode)成另一种编码。
decode的作用是将其他编码的字符串转换成unicode编码,如str1.decode('gb2312'),表示将gb2312编码的字符串str1转换成unicode编码。
encode的作用是将unicode编码转换成其他编码的字符串,如str2.encode('gb2312'),表示将unicode编码的字符串str2转换成gb2312编码。
总得意思:想要将其他的编码转换成utf-8必须先将其解码成unicode然后重新编码成utf-,它是以unicode为转换媒介的
如:s='中文'
如果是在utf8的文件中,该字符串就是utf8编码,如果是在gb2312的文件中,则其编码为gb2312。这种情况下,要进行编码转换,都需要先用
decode方法将其转换成unicode编码,再使用encode方法将其转换成其他编码。通常,在没有指定特定的编码方式时,都是使用的系统默认编码创建的代码文件。
如下:
s.decode('utf-8').encode('utf-8')
decode():是解码
encode()是编码
isinstance(s,unicode):判断s是否是unicode编码,如果是就返回true,否则返回false* '''
'''
s='中文'
s=s.decode('utf-8') #将utf-8编码的解码成unicode
print isinstance(s,unicode) #此时输出的就是True
s=s.encode('utf-8') #又将unicode码编码成utf-
print isinstance(s,unicode) #此时输出的就是False
'''
print sys.getdefaultencoding() s='中文'
if isinstance(s,unicode): #如果是unicode就直接编码不需要解码
print s.encode('utf-8')
else:
print s.decode('utf-8').encode('gb2312') print sys.getdefaultencoding() #获取系统默认的编码
reload(sys)
sys.setdefaultencoding('utf8') #修改系统的默认编码
print sys.getdefaultencoding()
python2和python3中的字符编码
python2
str类型 ----------->字节编码后的二进制数据
字符串类型 unicode类型-------->unicode编码后的二进制数据 s1='苑' print type(s1) # <type 'str'>
print repr(s1) #'\xe8\x8b\x91 s2=u'苑'
print type(s2) # <type 'unicode'>
print repr(s2) # u'\u82d1' s1=u'苑'
print repr(s1) #u'\u82d1' b=s1.encode('utf8')
print b
print type(b) #<type 'str'>
print repr(b) #'\xe8\x8b\x91' s2='苑昊'
u=s2.decode('utf8')
print u # 苑昊
print type(u) # <type 'unicode'>
print repr(u) # u'\u82d1\u660a' #注意
u2=s2.decode('gbk')
print u2 #鑻戞槉 print len('苑昊') #
python3
str类型 ---------->unicode编码后的二进制数据
字符串类型 bytes类型-------->bytes编码后的二进制数据 import json s='苑昊'
print(type(s)) #<class 'str'>
print(json.dumps(s)) # "\u82d1\u660a" b=s.encode('utf8')
print(type(b)) # <class 'bytes'>
print(b) # b'\xe8\x8b\x91\xe6\x98\x8a' u=b.decode('utf8')
print(type(u)) #<class 'str'>
print(u) #苑昊
print(json.dumps(u)) #"\u82d1\u660a" print(len('苑昊')) #
相关练习
字符编码: ---utf8存入硬盘------- #coding:utf8
print("坏小子")
--------------------- 方式一:在pycharm执行 setting都是utf8 python 不乱码
python 不乱码 方式二:在cmd执行 python 不乱码 解释器按utf8解码,翻译为uniode在执行,cmd执行print("坏小子")时,字符串为unicode数据 python 乱码 解释器按utf8解码,翻译为bytes在执行,cmd应该把"坏小子"打印为bytes数据,而不是明文
但python2解释器会进行一个暗转换,把"坏小子" bytes数据解码转换为unicode数据,
cmd按gbk将bytes数据解码为unicode时,会出错。
python 之字符编码的更多相关文章
- Python基础-字符编码与转码
***了解计算机的底层原理*** Python全栈开发之Python基础-字符编码与转码 需知: 1.在python2默认编码是ASCII, python3里默认是utf-8 2.unicode 分为 ...
- Python的字符编码
Python的字符编码 1. Python字符编码简介 1. 1 ASCII Python解释器在加载.py文件的代码时,会对内容进行编码,一般默认为ASCII码.ASCII(American St ...
- Python常用字符编码(转)
Python常用字符编码 字符编码的常用种类介绍 第一种:ASCII码 ASCII(American Standard Code for Information Interchange,美国信息交 ...
- Python常见字符编码间的转换
主要内容: 1.Unicode 和 UTF-8的爱恨纠葛 2.字符在硬盘上的存储 3.编码的转换 4.验证编码是否转换正确 5.Python bytes类型 前 ...
- python 3字符编码
python 3字符编码 官方链接:http://legacy.python.org/dev/peps/pep-0263/ 在Python2中默认是ascii编码,Python3是utf-8编码 在p ...
- Python 的字符编码
配置: Python 2.7 + Sublime Text 2 + OS X 10.10 本文意在理清各种编码的关系并以此解决 Python 中的编码问题. 1 编码基本概念 只有先了解字符表.编码字 ...
- 转:Python常见字符编码及其之间的转换
参考:Python常见字符编码 + Python常见字符编码间的转换 一.Python常见字符编码 字符编码的常用种类介绍 第一种:ASCII码 ASCII(American Standard Cod ...
- Python遇到字符编码出问题的一个相对万能的办法
在使用Python做爬虫的过程中,经常遇到字符编码出问题的情况. UnicodeEncodeError: 'ascii' codec can't encode character u'\u6211' ...
- Python:字符编码详解
相关文章 Python中文编码问题:为何在控制台下输出中文会乱码及其原理 1. 字符编码简介 1.1. ASCII ASCII(American Standard Code for Informati ...
- Python入门笔记(14):Python的字符编码
一.字符编码中ASCII.Unicode和UTF-8的区别 点击阅读:http://www.cnblogs.com/kingstarspe/p/ASCII.html 再推荐一篇相关博文:http:// ...
随机推荐
- The query below helps you to locate tables without a primary key:
SELECT tables.table_schema, tables.table_name, tables.table_rows FROM information_schema.tables LEFT ...
- Delphi操作Ini文件
Delphi提供了一个TInifile类,使我们可以非常灵活的处理INI文件 一.INI文件的结构[小节名]ini文件 关键字1=值1 关键子2=值2INI文件允许有多个小节, ...
- Linux下安装jdk8步骤详述
作为Java开发人员,在Linux下安装一些开发工具是必备技能,本文以安装jdk为例,详细记录了每一步的操作命令,以供参考. 0.下载jdk8 登录网址:http://www.oracle.com/t ...
- sql使用实例
将另一表中的合计值保存到指定字段,并将空值赋0 update ShopInfo set JLRunningWater =(select COALESCE(sum(v.TotalMoney),0) as ...
- java多线程中最佳的实践方案是什么?
java多线程中最佳的实践方案是什么? 给你的线程起个有意义的名字.这样可以方便找bug或追踪.OrderProcessor, QuoteProcessor or TradeProcessor 这种名 ...
- RobotFramework - AppiumLibrary 之元素定位
一.介绍 AppiumLibrary 是 Robot Framework 的App测试库. 它使用Appium 与Android 和 iOS应用程序进行通信,类似于Selenium WebDriver ...
- android 开发 我的高德地图代码例子
下载高德地图依赖库和相关注册方式,请查看高德开发者网站:http://lbs.amap.com/api/android-sdk/summary 点击打开链接 高德地图坐标拾取器:http://lbs ...
- VS2015密匙--VS2015打开丢失msvcp140.dll--cannot find one or more components ,please reinstall the application
win7旗舰版 64位 + vs2015 专业版 1.安装VS2015过程中可能需要用到的VS2015专业版钥匙:(测试,可用) HMGNV-WCYXV-X7G9W-YCX63-B98R2 2.VS2 ...
- 转载:指针delete后要设置为NULL
本文来自:http://rpy000.blog.163.com/blog/static/196109536201292615547939/ 众所周知,最开始我们用new来创建一个指针,那么等我们用完它 ...
- leetcode11
public class Solution { //public int MaxArea(int[] height) //{ // var max = 0; // for (int i = 0; i ...