bs4爬虫入门
# -*- coding: utf-8 -*-
"""
Created on Fri Nov 16 13:35:33 2018 @author: zhen
"""
import urllib
import urllib.request
from bs4 import BeautifulSoup # 设置目标rootUrl,使用urllib.request.Request创建请求
rootUrl = "https://www.cnblogs.com/"
request = urllib.request.Request(rootUrl) header = "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36"
# 使用add_header设置请求头,将代码伪装成浏览器
request.add_header("User-Agent", header) # 使用urllib.request.urlopen打开页面,使用read方法保存html代码
htmlUrl = urllib.request.urlopen(request).read() # 使用BeautifulSoup创建html代码的BeautifulSoup实例,存为beautifulSoup
beautifulSoup = BeautifulSoup(htmlUrl) # 获取尾页(对照前一小节获取尾页的内容看你就明白了)
total_page = int(beautifulSoup.find("div",class_= "pager").findAll("a")[-2].get_text()) list_item = beautifulSoup.findAll("a",class_="titlelnk")
for i in list_item: # 遍历所有的内容
href = i["href"] # 获取对应的href
req = urllib.request.Request(href)
req.add_header("User-Agent", header)
html = urllib.request.urlopen(req).read()
soup = BeautifulSoup(html)
# 获取标题
titleContent = soup.find("a", id="cb_post_title_url")
if titleContent is not None: # 判读是否为空
title = titleContent.get_text()
# 获取内容
content = soup.find("div").get_text().strip()
print(title, "\n=====================================\n", content[1:100])
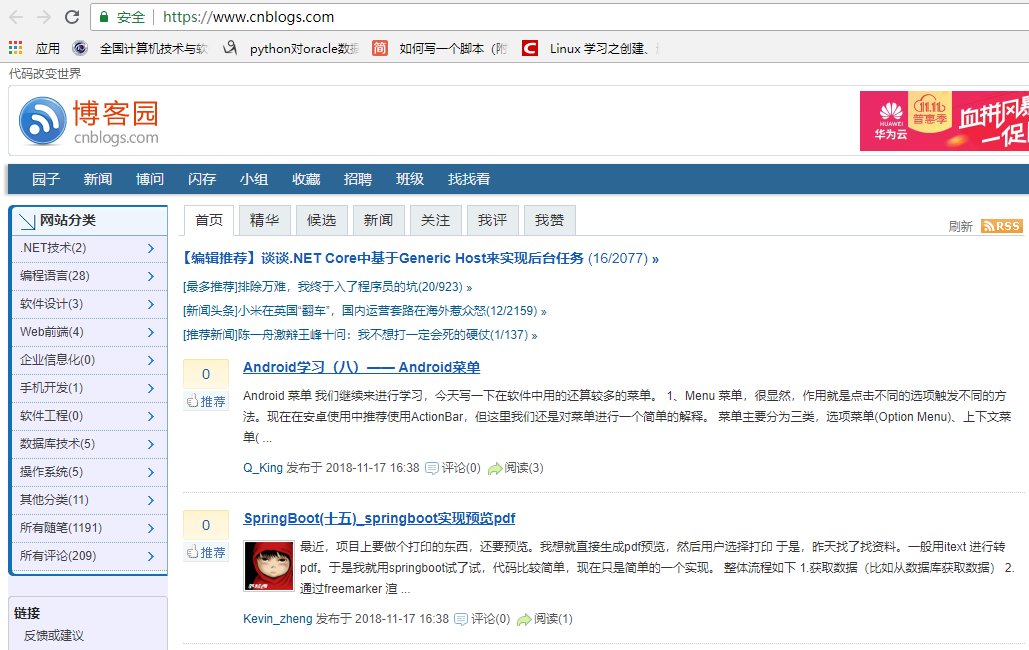
爬虫结果:


bs4爬虫入门的更多相关文章
- 爬虫入门之爬取策略 XPath与bs4实现(五)
爬虫入门之爬取策略 XPath与bs4实现(五) 在爬虫系统中,待抓取URL队列是很重要的一部分.待抓取URL队列中的URL以什么样的顺序排列也是一个很重要的问题,因为这涉及到先抓取那个页面,后抓取哪 ...
- Python简单爬虫入门三
我们继续研究BeautifulSoup分类打印输出 Python简单爬虫入门一 Python简单爬虫入门二 前两部主要讲述我们如何用BeautifulSoup怎去抓取网页信息以及获取相应的图片标题等信 ...
- Python简单爬虫入门二
接着上一次爬虫我们继续研究BeautifulSoup Python简单爬虫入门一 上一次我们爬虫我们已经成功的爬下了网页的源代码,那么这一次我们将继续来写怎么抓去具体想要的元素 首先回顾以下我们Bea ...
- GJM : Python简单爬虫入门(二) [转载]
感谢您的阅读.喜欢的.有用的就请大哥大嫂们高抬贵手"推荐一下"吧!你的精神支持是博主强大的写作动力以及转载收藏动力.欢迎转载! 版权声明:本文原创发表于 [请点击连接前往] ,未经 ...
- 【网络爬虫入门05】分布式文件存储数据库MongoDB的基本操作与爬虫应用
[网络爬虫入门05]分布式文件存储数据库MongoDB的基本操作与爬虫应用 广东职业技术学院 欧浩源 1.引言 网络爬虫往往需要将大量的数据存储到数据库中,常用的有MySQL.MongoDB和Red ...
- Python 爬虫入门(二)——爬取妹子图
Python 爬虫入门 听说你写代码没动力?本文就给你动力,爬取妹子图.如果这也没动力那就没救了. GitHub 地址: https://github.com/injetlee/Python/blob ...
- Python 爬虫入门之爬取妹子图
Python 爬虫入门之爬取妹子图 来源:李英杰 链接: https://segmentfault.com/a/1190000015798452 听说你写代码没动力?本文就给你动力,爬取妹子图.如果 ...
- 【网络爬虫入门01】应用Requests和BeautifulSoup联手打造的第一条网络爬虫
[网络爬虫入门01]应用Requests和BeautifulSoup联手打造的第一条网络爬虫 广东职业技术学院 欧浩源 2017-10-14 1.引言 在数据量爆发式增长的大数据时代,网络与用户的沟 ...
- python网络爬虫入门(二)
刚去看了一下,18年2月份写了第一篇关于爬虫的文章(仅仅介绍了使用requests库去获取HTML代码),一年多之后看来很稚嫩也没有多少参考的意义,但没想着要去修改它,留着也是一个回忆吧.至少证明着我 ...
随机推荐
- LeetCode:94_Binary Tree Inorder Traversal | 二叉树中序遍历 | Medium
题目:Binary Tree Inorder Traversal 二叉树的中序遍历,和前序.中序一样的处理方式,代码见下: struct TreeNode { int val; TreeNode* l ...
- Liferay7 BPM门户开发之11: Activiti工作流程开发的一些统一规则和实现原理(完整版)
注意:以下规则是我为了规范流程的处理过程,不是Activiti公司的官方规定. 1.流程启动需要设置启动者,在Demo程序中,“启动者变量”名统一设置为initUserId 启动时要做的: ident ...
- python(33)——【re模块】
re模块(正则表达式) 就其本质而言,正则表达式是一种小型的.高度专业化的编程语言 在Python中(它内嵌在python中),并通过re模块来实现,正则表达式被编译成一系列的字节码,然后由C编写的匹 ...
- linux中crontab的使用方法
crontab参数说明: -e : 执行文字编辑器来设定时程表,内定的文字编辑器是 VI,如果你想用别的文字编辑器,则请先设定 VISUAL 环境变数来指定使用那个文字编辑器(比如说 setenv V ...
- 全网最详细的MyEclipse里如何正确新建普通的Java web项目并发布到Tomcat上运行成功【博主强烈推荐】(图文详解)
不多说,直接上干货! 首先,大家要明确,IDEA.Eclipse和MyEclipse等编辑器之间的新建和运行手法是不一样的. 如果是在eclipse里,则是File -> new -> ...
- Maven_1 安装配置
所需工具 : JDK 1.8 Maven 3.3.9 Windows 7 下载Maven 3.3.9 http://maven.apache.org/download.cgi 首先要先安装JDK. ...
- 深度学习论文翻译解析(一):YOLOv3: An Incremental Improvement
论文标题: YOLOv3: An Incremental Improvement 论文作者: Joseph Redmon Ali Farhadi YOLO官网:YOLO: Real-Time Obje ...
- MyBatis从入门到放弃五:调用存储过程(SQLServer2012)
前言 如果是相对于复杂的SQL逻辑我们肯定是基于存储过程开发,这篇学习下执行存储过程,调用存储过程如果参数较多我们可以创建parameterMap. 搭建开发环境 开发环境和上篇文章保持相同 创建存储 ...
- Java 使用 happen-before 规则实现共享变量的同步操作
前言 熟悉 Java 并发编程的都知道,JMM(Java 内存模型) 中的 happen-before(简称 hb)规则,该规则定义了 Java 多线程操作的有序性和可见性,防止了编译器重排序对程序结 ...
- openWin和openFrame 设置透明背景
openWin简单点说就是:像是一个浏览器 openFrame就是对应openWin浏览器里面打开的每一个网页 有些操作只能在openWin里面执行,比如监听安卓返回事件,只能在openWin里面才有 ...