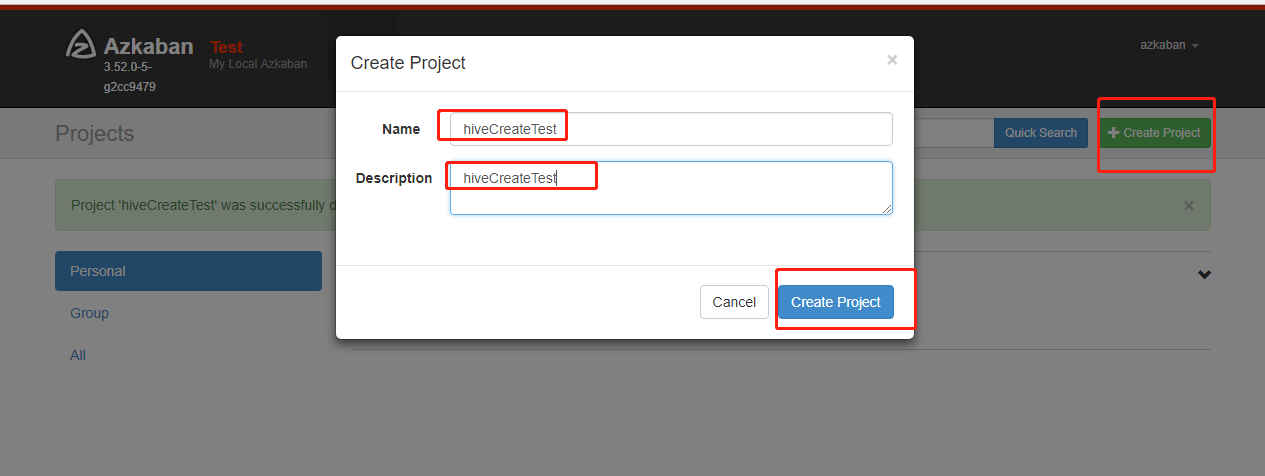
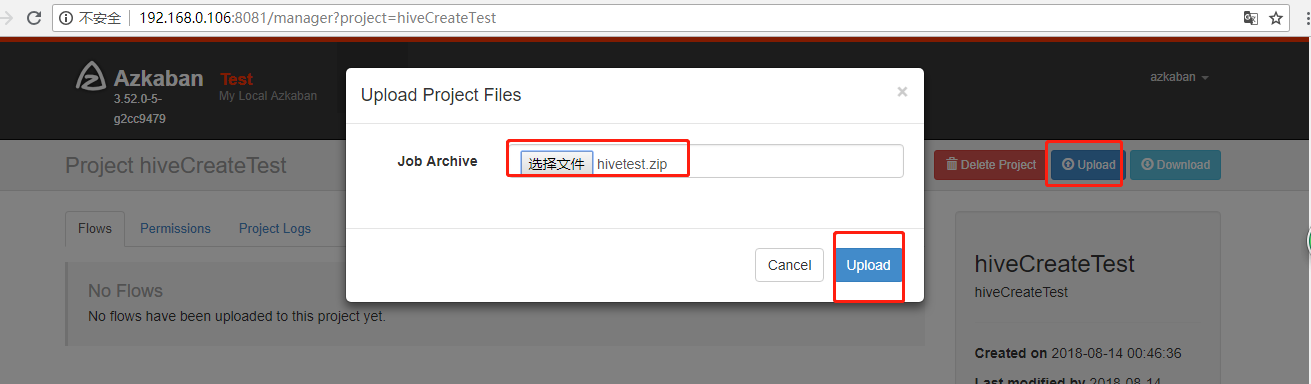
azkaban 执行hive语句
#hivef.job
type=command
command=hive -f test.sql
#test.sql
use default;
drop table aztest;
create table aztest(id int,name string) row format delimited fields terminated by ",";
load data inpath '/home/lxl/b.txt' into table aztest;
create table azres as select * from aztest;

.png)


.png)

.png)
.png)

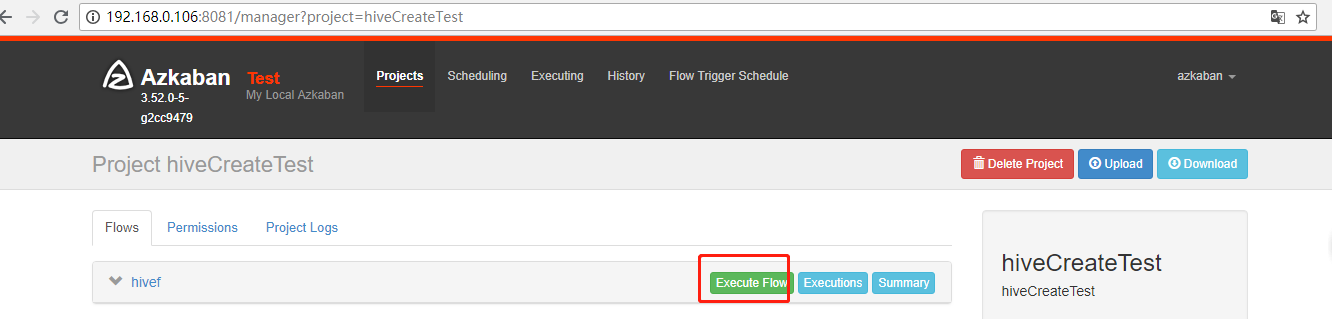

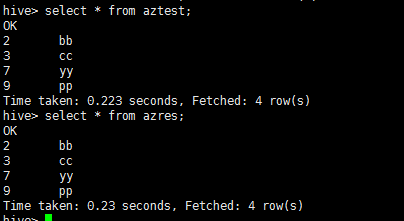
11.执行后显示如下:



.png)
.png)
#hivef.job
type=command
command=sudo -u hdfs hive -f test.sql
#test.sql
use default;
drop table aztest;
create table aztest(id int,name string) row format delimited fields terminated by ",";
load data inpath '/home/lxl/b.txt' into table aztest;
create table azres as select * from aztest;
azkaban 执行hive语句的更多相关文章
- 使用java连接hive,并执行hive语句详解
安装hadoop 和 hive我就不多说了,网上太多文章 自己看去 首先,在机器上打开hiveservice hive --service hiveserver -p 50000 & 打开50 ...
- 使用Hive或Impala执行SQL语句,对存储在HBase中的数据操作
CSSDesk body { background-color: #2574b0; } /*! zybuluo */ article,aside,details,figcaption,figure,f ...
- 使用Hive或Impala执行SQL语句,对存储在Elasticsearch中的数据操作(二)
CSSDesk body { background-color: #2574b0; } /*! zybuluo */ article,aside,details,figcaption,figure,f ...
- 使用Hive或Impala执行SQL语句,对存储在Elasticsearch中的数据操作
http://www.cnblogs.com/wgp13x/p/4934521.html 内容一样,样式好的版本. 使用Hive或Impala执行SQL语句,对存储在Elasticsearch中的数据 ...
- hive高阶1--sql和hive语句执行顺序、explain查看执行计划、group by生成MR
hive语句执行顺序 msyql语句执行顺序 代码写的顺序: select ... from... where.... group by... having... order by.. 或者 from ...
- Hadoop生态圈-Azkaban实现hive脚本执行
Hadoop生态圈-Azkaban实现hive脚本执行 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客中在HDFS分布式系统取的数据,而这个数据的是有之前我通过MapRed ...
- shell中执行hive命令错误:delimited by end-of-file (wanted `EOF')
错误信息: warning: here-document at line 58 delimited by end-of-file (wanted `EOF') 业务场景,使用hive对数据进行批量清洗 ...
- 通过学生-课程关系表,熟悉hive语句
通过学生-课程关系表,熟悉hive语句 1.在hive中创建以下三个表. create table student(Sno int,Sname string,Sex string,Sage int, ...
- 工作中常见的hive语句总结
hive的启动: 1.启动hadoop2.开启 metastore 在开启 hiveserver2服务nohup hive --service metastore >> log.out 2 ...
随机推荐
- 开源中国/码云 README.md上传图片的爬坑记录
整理代码,将电脑中长期没有用过的代码放到码云上托管,给项目录制gif动画,在写项目README.md时使用,结果在上传图片时一直出问题,现记录下最后解决方法: 1. 最初直接将录制好的图片放入到img ...
- mac出现zsh: command not found: ping解决方法
Step1:终端输入以下命令: /sbin/ping 若出现如下信息,说明包含ping命令,是zsh的 PATH有问题,表示没有加载sbin下的命令,需要编辑.zshrc文件. Step2:终端打开. ...
- Codeforces1062C. Banh-mi(贪心+快速幂)
题目链接:传送门 题目: C. Banh-mi time limit per test second memory limit per test megabytes input standard in ...
- JUnit4测试报错:class not found XXX
初学java框架,最近用eclipse跟着视频坐淘淘商城这个项目,其中使用了JUnit4做单元测试.当运行测试代码时,项目报错:class not found xxx. 借助了其他大神的博客,论坛等 ...
- kali 2018.2版本运行破解版burpsuite时候的问题。
最近重装了kali虚拟机,装完之后把burp拷到里面发现运行不了了,折腾了下才解决,问题主要是由于java环境造成的. 系统默认是以java10运行burp的,但是java10好像是不支持 -X ...
- 通过用户名&密码验证访问远程共享文件夹 C#
通过代码先在cmd中运行net use进行验证,然后就可访问共享文件了. 验证方法如下: public string connectState(string path/*要访问的文件路径*/, str ...
- Linux touch命令详解
Linux touch命令 Linux touch命令用于修改文件或者目录的时间属性,包括存取时间和更改时间.若文件不存在,系统会建立一个新的文件. 用法: touch [-acfm][-d<日 ...
- 【转】利用Boost.Python将C++代码封装为Python模块
用Boost.Python将C++代码封装为Python模块 一. 基础篇 借助Boost.Python库可以将C/C++代码方便.快捷地移植到python模块当中,实现对python模块的扩 ...
- STM32定时器时间的计算方法
本文出自:https://wenku.baidu.com/view/e3bdfb7601f69e31433294c4.htmlSTM32定时器时间的计算方法STM32中的定时器有很多用法:(一)系统时 ...
- python成功之道
https://blog.ansheng.me/article/python-full-stack-way