mysql百万的数据快速创建索引
测试数据本机一张表users有100百万条记录。在创建此表前没有未相应字段添加索引,所以此时需要为表添加索引。但是因为数据量大的原因,索引添加可能不成功,想了很多办法,终于挖坑成功。
开始准备工作,
user表结构:
CREATE TABLE `users` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(255) CHARACTER SET utf8mb4 DEFAULT NULL,
`add_time` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=MyISAM AUTO_INCREMENT=1000001 DEFAULT CHARSET=latin1;
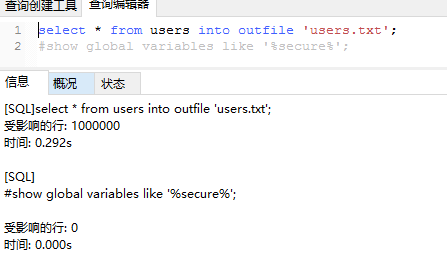
尝试在navicat中使用 into outfile导出数据的时候出现错误:
select * from users into outfile 'users.txt'; //users.txt文件在mysql的dat
如下图:

上网查了一下是mysql设置的权限,可以使用
show variables like '%secure%';查看 secure-file-priv 当前的值是什么?
可以看到secure-file-priv参数是用来限制LOAD DATA, SELECT ... OUTFILE, and LOAD_FILE()传到哪个指定目录的。 当secure_file_priv的值为null ,表示限制mysqld 不允许导入|导出 当secure_file_priv的值为/tmp/ ,表示限制mysqld 的导入|导出只能发生在/tmp/目录下 当secure_file_priv的值没有具体值时,表示不对mysqld 的导入|导出做限制.
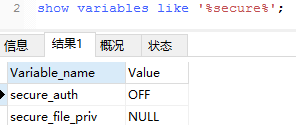
导出的数据必须是这个值的指定路径才可以导出,默认有可能是NULL(我这里查看的是null)就代表禁止导出,所以需要设置一下
由于我使用的是phpstudy,mysql安装路径下的my.ini文件,设置一下路径:
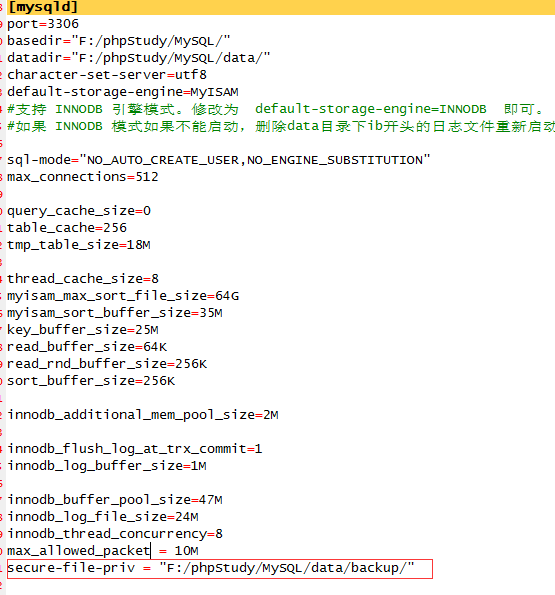
注意:路径名加双引号" "
重启后再次执行错误依旧.....
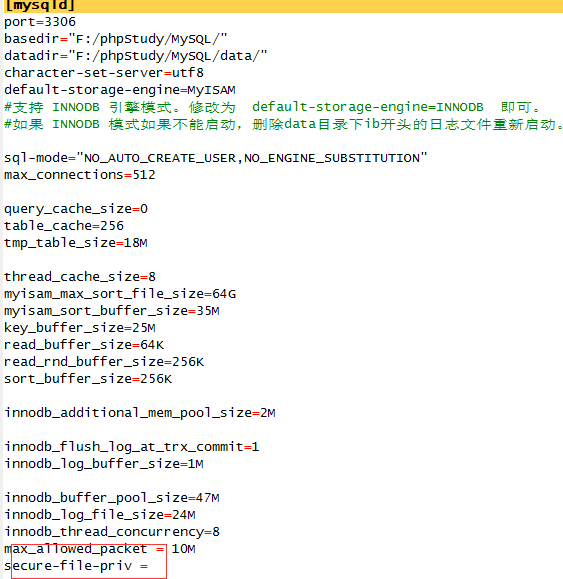
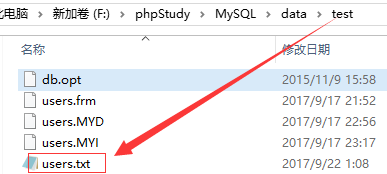
可以看到users.txt生成在同级test数据库目录。。。
接着执行:
truncate users;
创建索引:
create index name using BTREE on users(name);
索引的方式有:BTREE、RTREE、HASH、FULLTEXT、SPATIAL,这里不再赘述他们的区别,网上有很多关于这块的介绍啦
导入文件到相应表users。
load data infile 'users.txt' into table users;
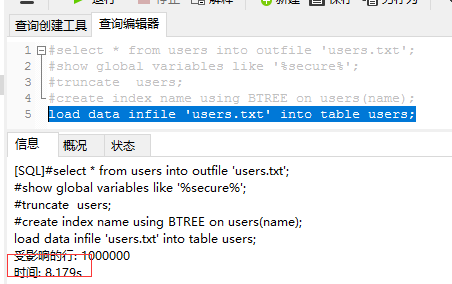
此方式在write 锁住情况下,或对外服务暂停时使用,线上不可能直接这样玩了。。
mysql百万的数据快速创建索引的更多相关文章
- 提高MYSQL百万条数据的查询速度
提高MYSQL百万条数据的查询速度 1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引. 2.应尽量避免在 where 子句中对字段进行 nul ...
- MYSQL百万级数据,如何优化
MYSQL百万级数据,如何优化 首先,数据量大的时候,应尽量避免全表扫描,应考虑在 where 及 order by 涉及的列上建立索引,建索引可以大大加快数据的检索速度.但是,有些情况索引是 ...
- Elasticsearch-索引新数据(创建索引、添加数据)
ES-索引新数据 0.通过mapping映射新建索引 CURL -XPOST 'localhost:9200/test/index?pretty' -d '{ "mappings" ...
- Mysql建表的时候创建索引
创建表时可以直接创建索引,这种方式最简单.方便.其基本形式如下: CREATE TABLE 表名( 属性名 数据类型[完整性约束条件], 属性名 数据类型[完整性约束条件], ...... 属性名 数 ...
- Solr5.5.3的研究之路 ---1、从Mysql导入数据并创建索引
公司需要用到全文检索,故使用Solr,也是新人一枚,本人查看的前提是Solr已经安装部署成功,我用的服务器是自带的Jetty 1.创建Collection [root@whoami bin]# ./s ...
- MySQL 快速创建索引
用SELECT INTO OUTFILE导出记录,TRUNCATE 此TABLE,建立索引,用LOAD DATA INIFILE再导入 缺点:不支持热操作
- mysql和mssql数据库快速创建表格 五
* into testAAA FROM tbl_User --sqlserver方法一复制表结构 select * into testAAA FROM tbl_User --sqlserver复制表结 ...
- Mysql高级操作学习笔记:索引结构、树的区别、索引优缺点、创建索引原则(我们对哪种数据创建索引)、索引分类、Sql性能分析、索引使用、索引失效、索引设计原则
Mysql高级操作 索引概述: 索引是高效获取数据的数据结构 索引结构: B+Tree() Hash(不支持范围查询,精准匹配效率极高) 树的区别: 二叉树:可能产生不平衡,顺序数据可能会出现链表结构 ...
- MySQL如何创建一个好索引?创建索引的5条建议【宇哥带你玩转MySQL 索引篇(三)】
MySQL如何创建一个好索引?创建索引的5条建议 过滤效率高的放前面 对于一个多列索引,它的存储顺序是先按第一列进行比较,然后是第二列,第三列...这样.查询时,如果第一列能够排除的越多,那么后面列需 ...
随机推荐
- hdmi中深度色彩像素打包
4个色彩像素包模式:24- 30- 36- 48- 不同模式下tmds时钟与与像素的比是位宽与24的比值 . 24 bit mode: TMDS clock = 1.0 x pixel clock ( ...
- [预打印]使用vbs给PPT(包括公式)去背景
原先博客放弃使用,几篇文章搬运过来 在 视图—>宏 内新建宏 '终极版 Sub ReColor() Dim sld As Slide Dim sh As Shape For Each sld I ...
- HDU 2639 01背包(分解)
http://acm.hdu.edu.cn/showproblem.php?pid=2639 01背包第k优解,把每次的max分步列出来即可 #include<stdio.h> #incl ...
- array_filter()函数
用回调函数过滤数组中的值 array_filter(array,callbackfunction); 返回过滤后的数组
- pb数据导出
pb数据导出(一) 1.在窗口新建用户事件 ue_export 2.事件调用函数 gf_dw_to_excel(THIS.dw_dict) 3.写函数 :boolean lb_setborde ...
- [UWP]使用Picker实现一个简单的ColorPicker弹窗
在上一篇博文<[UWP]使用Popup构建UWP Picker>中我们简单讲述了一下使用Popup构建适用于MVVM框架下的弹窗层组件Picker的过程.但是没有应用实例的话可能体现不出P ...
- Springboot/SpringMvc 读取上传 xls 文件内容
/** * 读取上传 xls 内容返回 * @param file * @return */@RequestMapping(value = "/read.xls")@Respons ...
- [git] 常用配置
基本配置 对git进行配置时使用 git config 命令进行操作 1. git config 的作用域,缺省等于 local git config --local #只针对某个仓库有效 git ...
- 命令行下查看python和numpy的版本和安装位置
命令行下查看python和numpy的版本和安装位置 1.查看python版本 方法一: python -V 注意:‘-V‘中‘V’为大写字母,只有一个‘-’ 方法二: python --versio ...
- python中基于queue的打印机仿真算法
使用打印机的模型是queue中最经典的应用之一,这里就回顾一下queue在这里的使用方法和 起的重要作用. 为了仿真打印状态,这里需要把真实环境中的三个物理模型要建模出来,分别是:打印者,打印 任务, ...