DPDK内存管理-----(二)rte_mempool内存管理
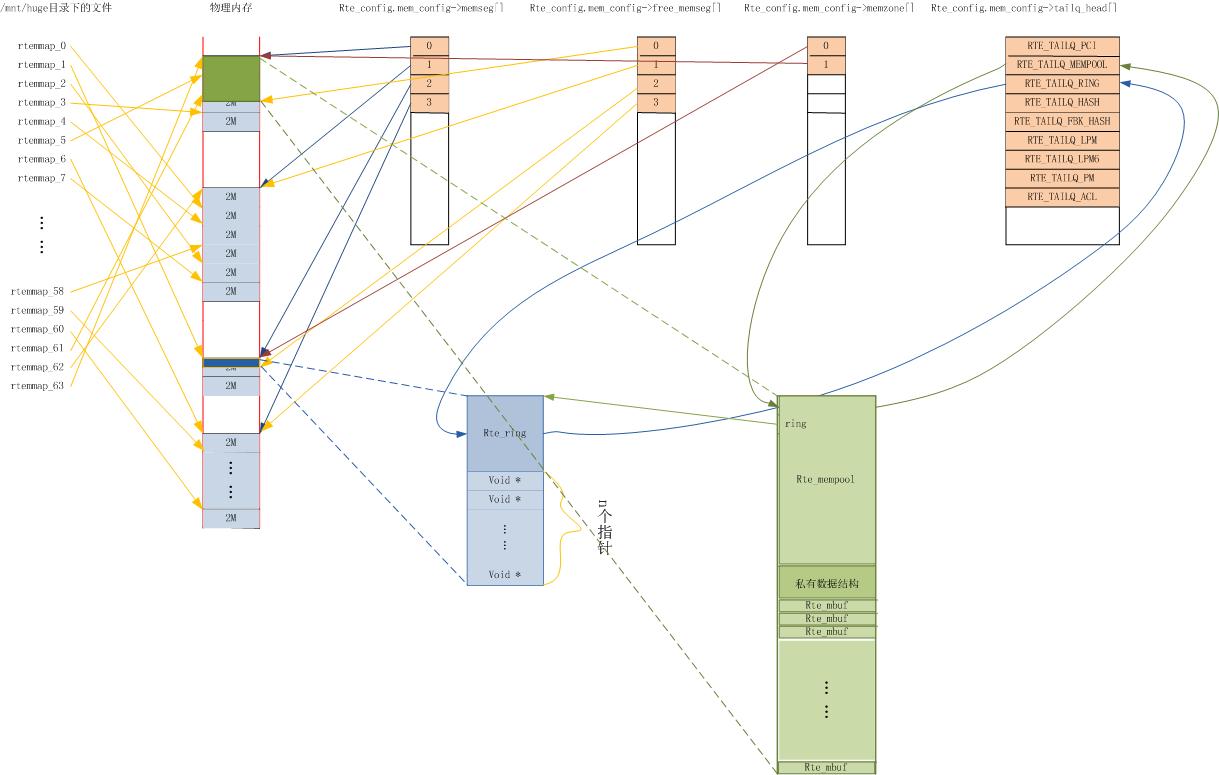
DPDK以两种方式对外提供内存管理方法,一个是rte_mempool,主要用于网卡数据包的收发;一个是rte_malloc,主要为应用程序提供内存使用接口。本文讨论rte_mempool。rte_mempool由函数rte_mempool_create()负责创建,从rte_config.mem_config->free_memseg[]中取出合适大小的内存,放到rte_config.mem_config->memzone[]中。
本文中,以l2fwd为例,说明rte_mempool的创建及使用。
一、rte_mempool的创建
l2fwd_pktmbuf_pool =
rte_mempool_create("mbuf_pool", NB_MBUF,
MBUF_SIZE, ,
sizeof(struct rte_pktmbuf_pool_private),
rte_pktmbuf_pool_init, NULL,
rte_pktmbuf_init, NULL,
rte_socket_id(), );
“mbuf_pool”:创建的rte_mempool的名称。
NB_MBUF:rte_mempool包含的rte_mbuf元素的个数。
MBUF_SIZE:每个rte_mbuf元素的大小。
#define RTE_PKTMBUF_HEADROOM 128
#define MBUF_SIZE (2048 + sizeof(struct rte_mbuf) + RTE_PKTMBUF_HEADROOM)
#define NB_MBUF 8192
struct rte_pktmbuf_pool_private {
uint16_t mbuf_data_room_size; /**< Size of data space in each mbuf.*/
};
rte_mempool由函数rte_mempool_create()负责创建。首先创建rte_ring,再创建rte_mempool,并建立两者之间的关联。

1、rte_ring_create()创建rte_ring无锁队列
r = rte_ring_create(rg_name, rte_align32pow2(n+), socket_id, rg_flags);
具体步骤如下:
a、需要保证创建的队列数可以被2整除,即,count = rte_align32pow2(n + 1);
b、计算需要为count个队列分配的内存空间,即,ring_size = count * sizeof(void *) + sizeof(struct rte_ring);
struct rte_ring的数据结构如下,
struct rte_ring {
TAILQ_ENTRY(rte_ring) next; /**< Next in list. */
char name[RTE_RING_NAMESIZE]; /**< Name of the ring. */
int flags; /**< Flags supplied at creation. */
/** Ring producer status. */
struct prod {
uint32_t watermark; /**< Maximum items before EDQUOT. */
uint32_t sp_enqueue; /**< True, if single producer. */
uint32_t size; /**< Size of ring. */
uint32_t mask; /**< Mask (size-1) of ring. */
volatile uint32_t head; /**< Producer head. */
volatile uint32_t tail; /**< Producer tail. */
} prod __rte_cache_aligned;
/** Ring consumer status. */
struct cons {
uint32_t sc_dequeue; /**< True, if single consumer. */
uint32_t size; /**< Size of the ring. */
uint32_t mask; /**< Mask (size-1) of ring. */
volatile uint32_t head; /**< Consumer head. */
volatile uint32_t tail; /**< Consumer tail. */
#ifdef RTE_RING_SPLIT_PROD_CONS
} cons __rte_cache_aligned;
#else
} cons;
#endif
#ifdef RTE_LIBRTE_RING_DEBUG
struct rte_ring_debug_stats stats[RTE_MAX_LCORE];
#endif
void * ring[] __rte_cache_aligned; /**< Memory space of ring starts here.
* not volatile so need to be careful
* about compiler re-ordering */
};
c、调用rte_memzone_reserve(),在rte_config.mem_config->free_memseg[]中查找一个合适的free_memseg(查找规则是free_memseg中剩余内存大于等于需要分配的内存,但是多余的部分是最小的),从该free_memseg中分配指定大小的内存,然后将分配的内存记录在rte_config.mem_config->memzone[]中。
d、初始化新分配的rte_ring。
r->flags = flags;
r->prod.watermark = count;
r->prod.sp_enqueue = !!(flags & RING_F_SP_ENQ);
r->cons.sc_dequeue = !!(flags & RING_F_SC_DEQ);
r->prod.size = r->cons.size = count;
r->prod.mask = r->cons.mask = count-;
r->prod.head = r->cons.head = ;
r->prod.tail = r->cons.tail = ; TAILQ_INSERT_TAIL(ring_list, r, next); // 挂到rte_config.mem_config->tailq_head[RTE_TAILQ_RING]队列中
2、创建并初始化rte_mempool
a、计算需要为rte_mempool申请的内存空间。包含:sizeof(struct rte_mempool)、private_data_size,以及n * objsz.total_size。
mempool_size = MEMPOOL_HEADER_SIZE(mp, pg_num) + private_data_size;
if (vaddr == NULL)
mempool_size += (size_t)objsz.total_size * n;
objsz.total_size = objsz.header_size + objsz.elt_size + objsz.trailer_size; 其中,
objsz.header_size = sizeof(struct rte_mempool *);
objsz.elt_size = MBUF_SIZE;
objsz.trailer_size = ????
b、调用rte_memzone_reserve(),在rte_config.mem_config->free_memseg[]中查找一个合适的free_memseg,在该free_memseg中分配mempool_size大小的内存,然后将新分配的内存记录到rte_config.mem_config->memzone[]中。
c、初始化新创建的rte_mempool,并调用rte_pktmbuf_pool_init()初始化rte_mempool的私有数据结构。
/* init the mempool structure */
mp = mz->addr;
memset(mp, , sizeof(*mp));
snprintf(mp->name, sizeof(mp->name), "%s", name);
mp->phys_addr = mz->phys_addr;
mp->ring = r;
mp->size = n;
mp->flags = flags;
mp->elt_size = objsz.elt_size;
mp->header_size = objsz.header_size;
mp->trailer_size = objsz.trailer_size;
mp->cache_size = cache_size;
mp->cache_flushthresh = (uint32_t)
(cache_size * CACHE_FLUSHTHRESH_MULTIPLIER);
mp->private_data_size = private_data_size; /* calculate address of the first element for continuous mempool. */
obj = (char *)mp + MEMPOOL_HEADER_SIZE(mp, pg_num) +
private_data_size; /* populate address translation fields. */
mp->pg_num = pg_num;
mp->pg_shift = pg_shift;
mp->pg_mask = RTE_LEN2MASK(mp->pg_shift, typeof(mp->pg_mask)); /* mempool elements allocated together with mempool */
mp->elt_va_start = (uintptr_t)obj;
mp->elt_pa[] = mp->phys_addr +
(mp->elt_va_start - (uintptr_t)mp); mp->elt_va_end = mp->elt_va_start; RTE_EAL_TAILQ_INSERT_TAIL(RTE_TAILQ_MEMPOOL, rte_mempool_list, mp); //挂到rte_config.mem_config->tailq_head[RTE_TAILQ_MEMPOOL]队列中
d、调用mempool_populate(),以及rte_pktmbuf_init()初始化rte_mempool的每个rte_mbuf元素。
3、总结
相关数据结构的关联关系如下图:
二、rte_mempool的调用
未完,待续。。。。
错误之处,欢迎指出。
DPDK内存管理-----(二)rte_mempool内存管理的更多相关文章
- MySQL 调优基础(二) Linux内存管理
进程的运行,必须使用内存.下图是Linux中进程中的内存的分布图: 其中最重要的 heap segment 和 stack segment.其它内存段基本是大小固定的.注意stack是向低地址增长的, ...
- 你必须了解的java内存管理机制(二)-内存分配
前言 在上一篇文章中,我们花了较大的篇幅去介绍了JVM的运行时数据区,并且重点介绍了栈区的结构及作用,相关内容请猛戳!在本文中,我们将主要介绍对象的创建过程及在堆中的分配方式. 相关链接(注:文章讲解 ...
- 《Linux内核设计与实现》读书笔记(十二)- 内存管理【转】
转自:http://www.cnblogs.com/wang_yb/archive/2013/05/23/3095907.html 内核的内存使用不像用户空间那样随意,内核的内存出现错误时也只有靠自己 ...
- OC的内存管理(二)ARC
指针: 指向内存的地址指针变量 存放地址的变量指针变量值 变量中存放的值(地址值)指针变量指向的内存单元值 内存地址指向的值1):强指针:默认的情况下,所有的指针都是强指针,关键字strong ):弱 ...
- 高端内存映射之kmap_atomic固定映射--Linux内存管理(二十一)
1 固定映射 1.1 数据结构 linux高端内存中的临时内存区为固定内存区的一部分, 对于固定内存在linux内核中有下面描述 x86 arm arm64 arch/x86/include/asm/ ...
- Linux内存描述之内存节点node--Linux内存管理(二)
1 内存节点node 1.1 为什么要用node来描述内存 这点前面是说的很明白了, NUMA结构下, 每个处理器CPU与一个本地内存直接相连, 而不同处理器之前则通过总线进行进一步的连接, 因此相对 ...
- Linux内存描述之内存节点node–Linux内存管理(二)
日期 内核版本 架构 作者 GitHub CSDN 2016-06-14 Linux-4.7 X86 & arm gatieme LinuxDeviceDrivers Linux内存管理 #1 ...
- Block(二)内存管理与其他特性
一.block放在哪里 我们针对不同情况来讨论block的存放位置: 1.栈和堆 以下情况中的block位于堆中: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 ...
- Block(二)内存管理与其他特性-b
一.block放在哪里 我们针对不同情况来讨论block的存放位置: 1.栈和堆 以下情况中的block位于堆中: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 ...
- 高端内存映射之kmap持久内核映射--Linux内存管理(二十)
1 高端内存与内核映射 尽管vmalloc函数族可用于从高端内存域向内核映射页帧(这些在内核空间中通常是无法直接看到的), 但这并不是这些函数的实际用途. 重要的是强调以下事实 : 内核提供了其他函数 ...
随机推荐
- winform窗体的关闭与资源的释放
单纯的this.Dispose(); this.Close();有时候并不能释放出所用资源.因为Dispose()方法,虽然能释放当前窗体的资源,却不能强制结束循环, 要想强制突出当前程序要用:Sy ...
- 怎么在logcat中显示system.com.print中的打印信息
在logcat中显示信息可以用Log.v() Log.d() Log.i() Log.w() 以及 Log.e() 1.Log.v 的调试颜色为黑色的,任何消息都会输出: 2.Log.d的输出颜色是蓝 ...
- 卸载oracle
1. 开始->设置->控制面板->管理工具->服务 停止所有Oracle服务. 2. 开始->程序->Oracle - OraHome81 ...
- Eclipse设置模板代码
1. 打开preferences,找到Java > Editor > Templates.2. 点击"New",新建一个模版: 3. 打开Java文件,输入模版名称的前 ...
- C Primer Plus(第五版)2
在本章中你将学习下列内容------------------------------------------------------------------1.运算符:= 2.函数:main(),pr ...
- C Primer Plus(第五版)1
这是C Primer Plus(第五版)的第一章,上传上来主要是方便我进行做笔记,写注释,还有我会删掉一些“废话”等. 1.1 C语言的起源 贝尔实验室的 Dennis Ritchie 在1972年开 ...
- Linux Hugepage ,AMM及 USE_LARGE_PAGES for oracle 11G(转载)
1. Hugepage基本概念 系统进程是通过虚拟地址访问内存,但是CPU必须把它转换成物理内存地址才能真正访问内存.为了提高这个转换效率,CPU会缓存最近的“虚拟内存地址和物理内存地址”的 ...
- Android——Dialog
public class DialogActivity extends Activity { //进度对话框 ProgressDialog progressDialog; @Override ...
- Cocos2dx3.0过渡篇 各种遍历与范围for语句的使用【转】
1.CCArray的遍历看到这里,有些人又按耐不住的要举起西瓜刀了:你不是说3.0beta后已经没有CCArray这货了吗?现在又拿出来作甚?其实我也很无辜,CCArray确实是没了,但在某个不为人知 ...
- Asp.net下载文件
网站上的文件是临时文件, 浏览器下载完成, 网站需要将其删除. 下面的写法, 文件读写后没关闭, 经常删除失败. /// <summary> /// 下载服务器文件,参数一物理文件路径(含 ...