Scala实现网站流量实时分析
之前已经完成zookeeper集群、Hadoop集群、HBase集群、Flume、Kafka集群、Spark集群的搭建:使用Docker搭建Spark集群(用于实现网站流量实时分析模块),且离线分析模块已经在之前的模块中实现(网站日志流量分析系统之数据清洗处理(离线分析)),这次基于Docker搭建的spark集群,本地编写Scala代码实现网站日志流量实时分析模块,最终提交于spark集群。
一、本机环境
系统:win10 64位
Scala版本:2.13
JDK版本:1.8
IDE工具:IDEA2018
Maven版本:3.6.1
二、实时分析模块实现
之前已经完成zookeeper集群、Hadoop集群、HBase集群、Flume、Kafka集群、Spark集群的搭建:使用Docker搭建Spark集群(用于实现网站流量实时分析模块),且离线分析模块已经在之前的模块中实现(网站日志流量分析系统之数据清洗处理(离线分析)),这次基于Docker搭建的spark集群,本地编写Scala代码实现网站日志流量实时分析模块,最终提交于spark集群。
一、本机环境
系统:win10 64位
Scala版本:2.13
JDK版本:1.8
IDE工具:IDEA2018
Maven版本:3.6.1
二、目前状况
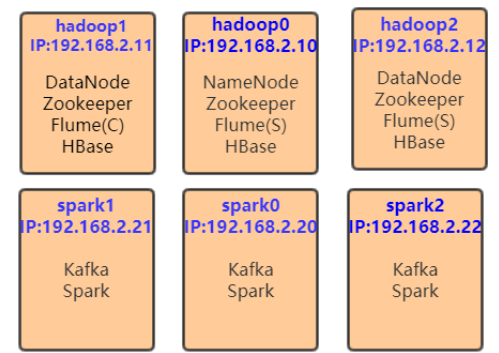
基于之前搭建的Spark集群:使用Docker搭建Spark集群(用于实现网站流量实时分析模块),目前集群运行环境如下:
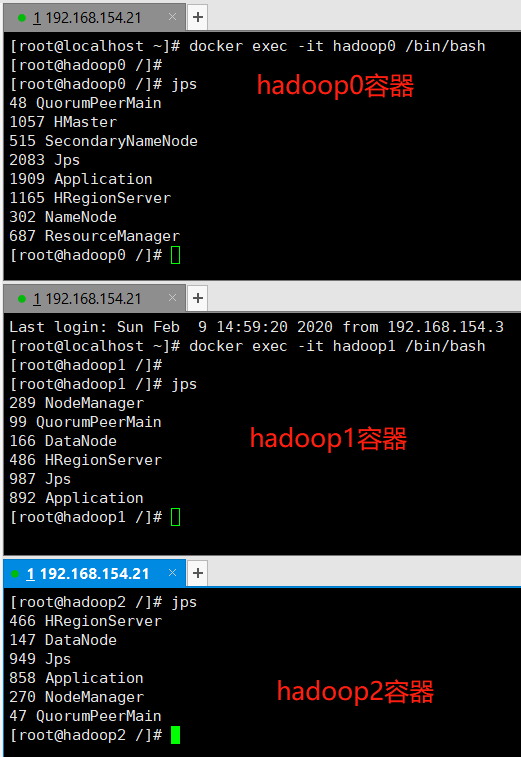
1、hadoop0、hadoop1、hadoop2容器角色
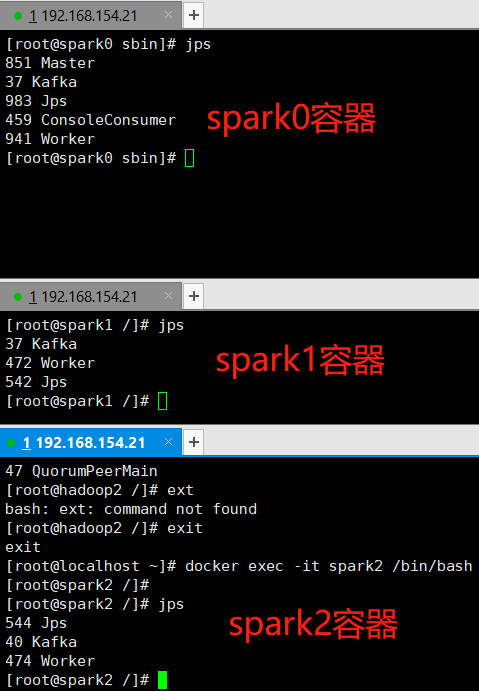
2、spark0、spark1、spark2容器
3、测试
app应用服务器通过js采集用户信息,发送至日志服务器,日志服务器分发至flume,flume分别落地至HDFS与Kafka,Kafka目前是以console模式消费消息,并未与spark对接
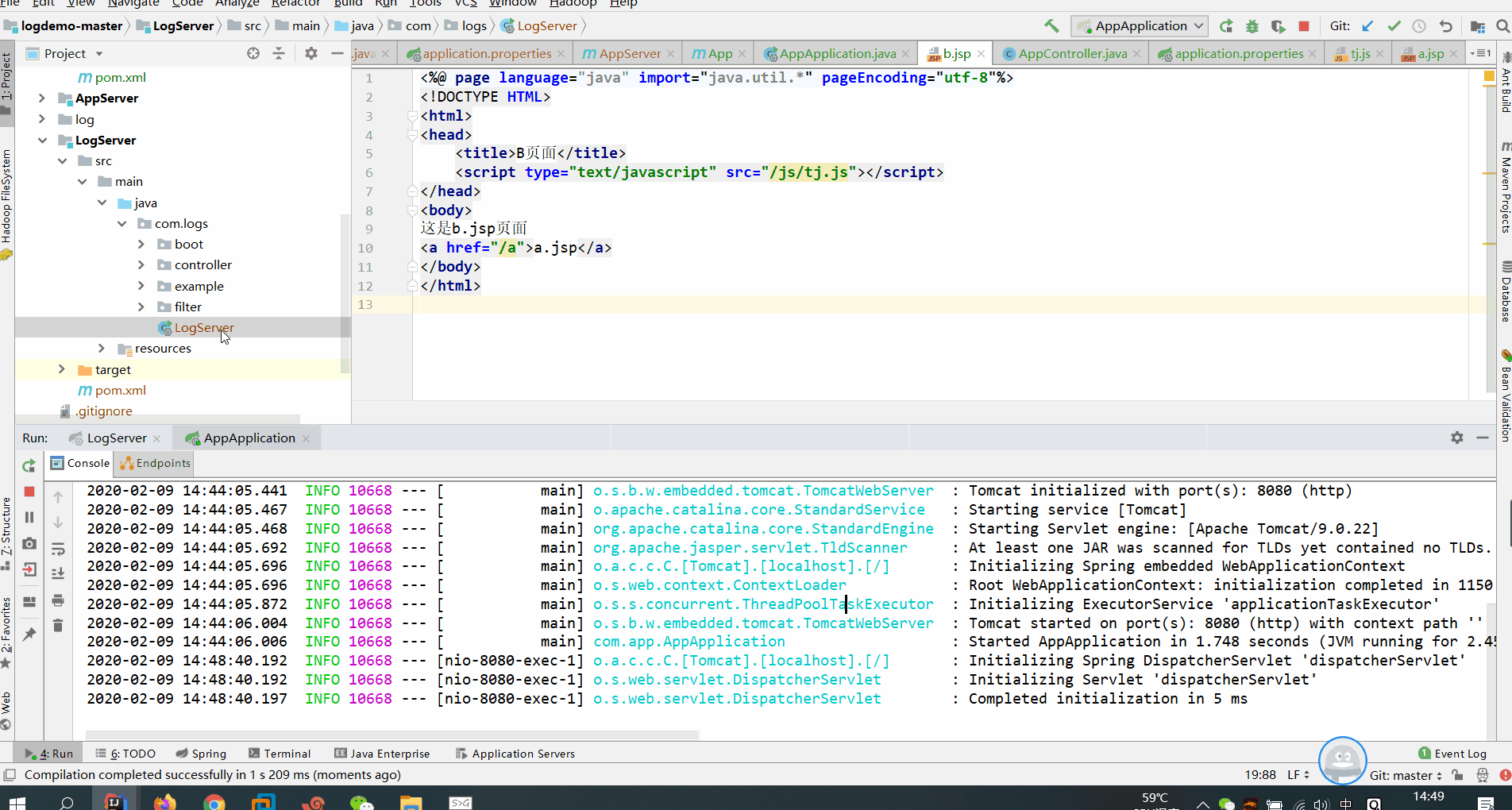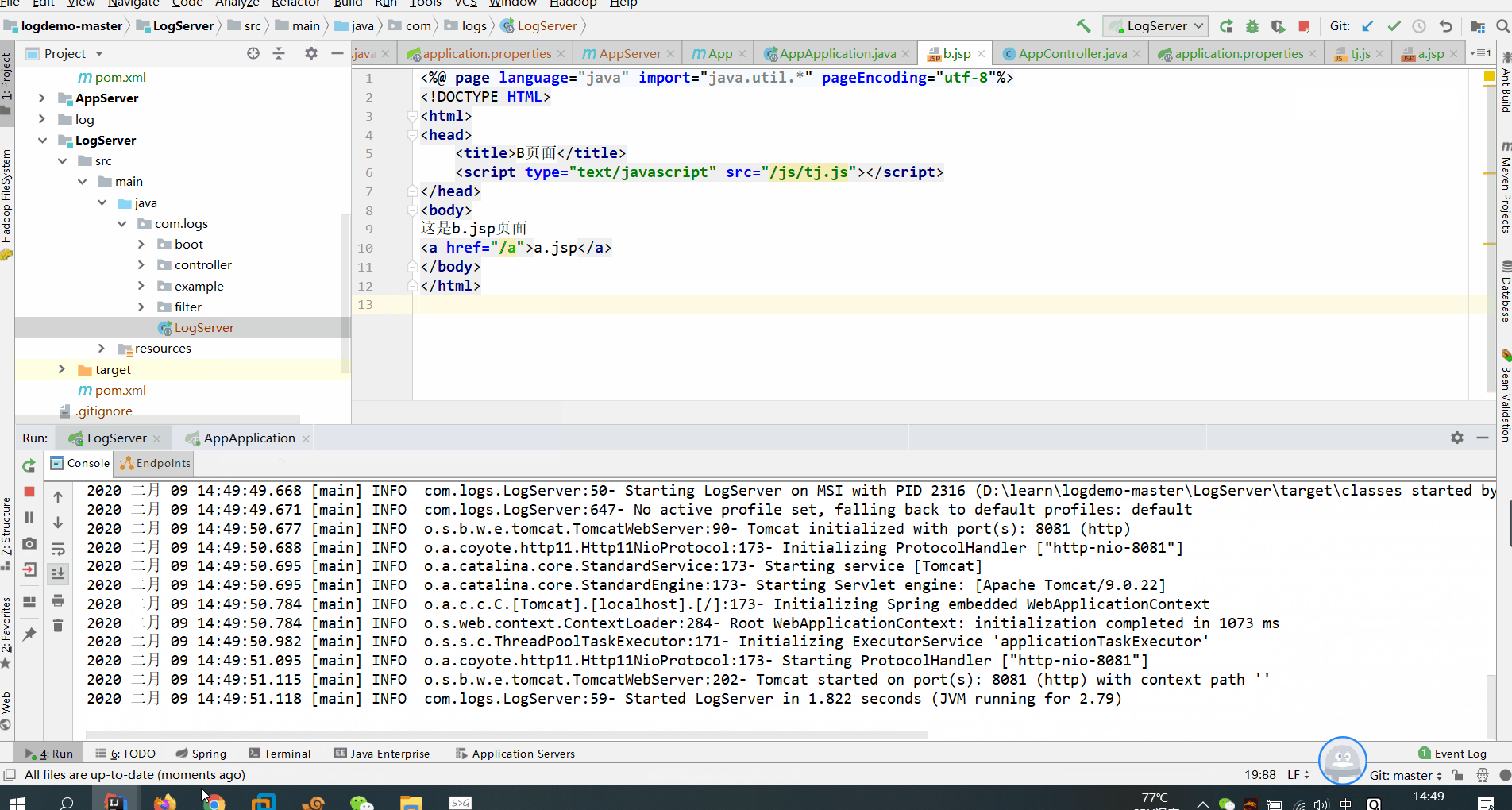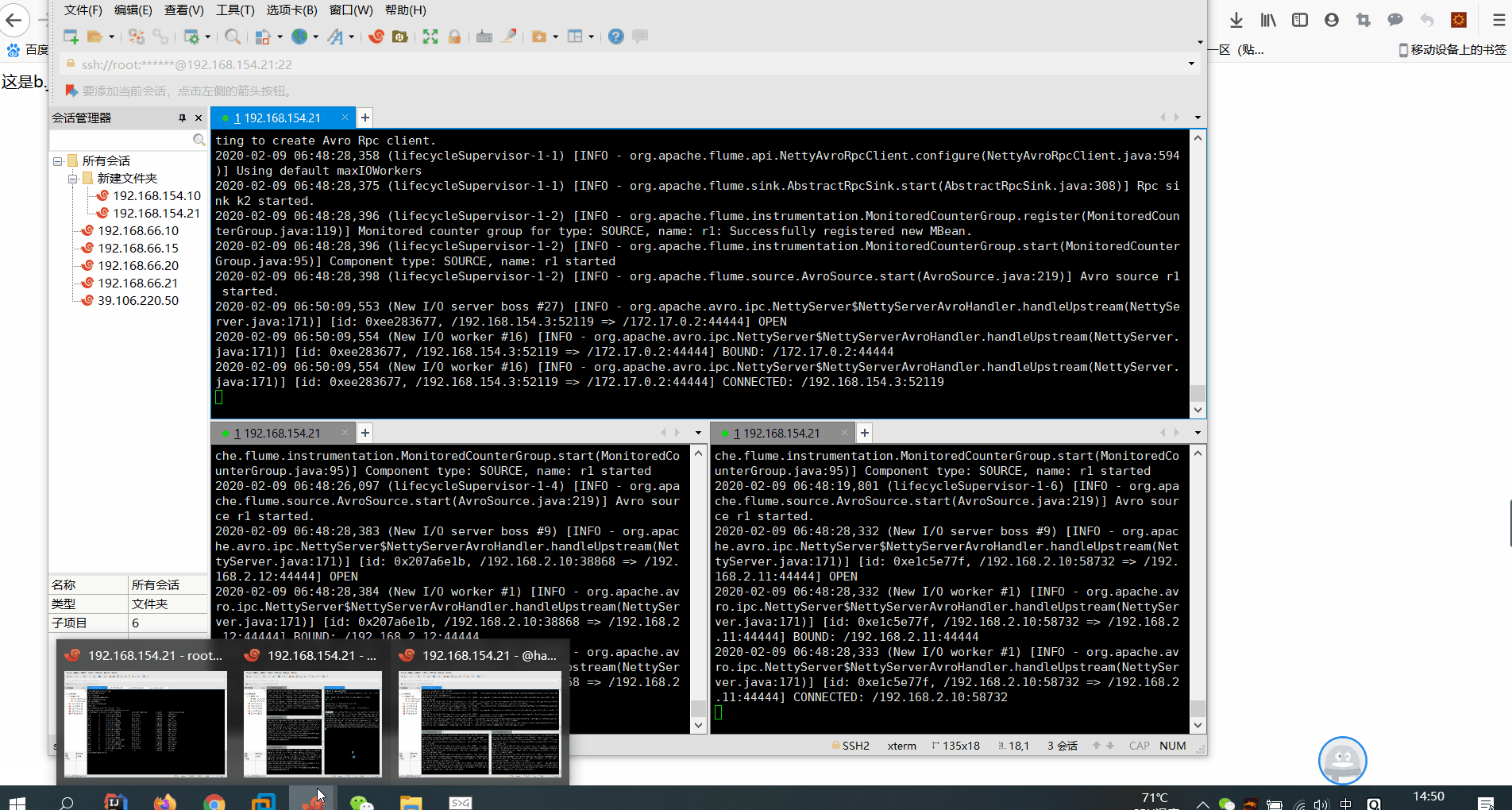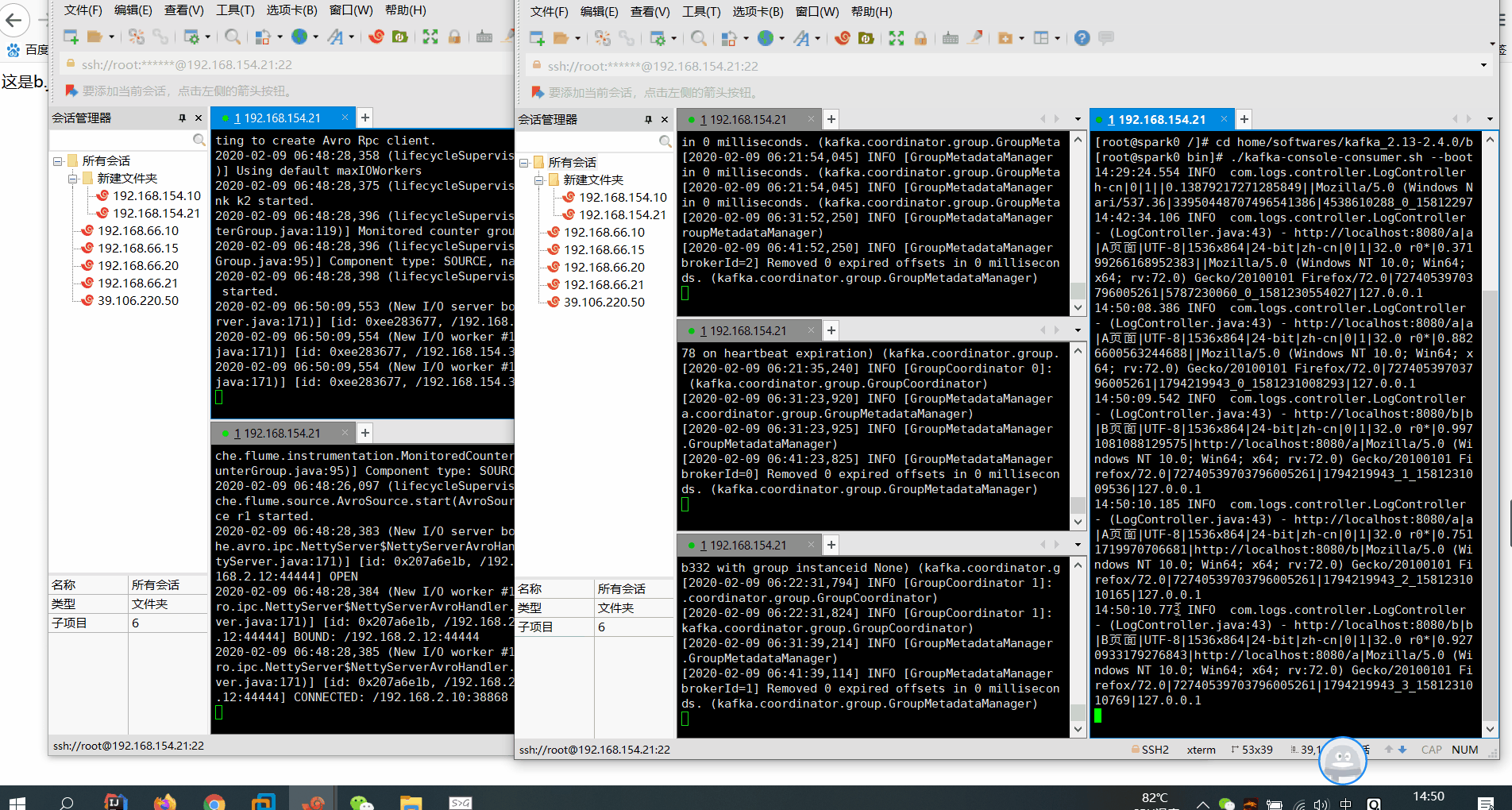
flume写入kafka的同时也落地至HDFS,供以离线分析
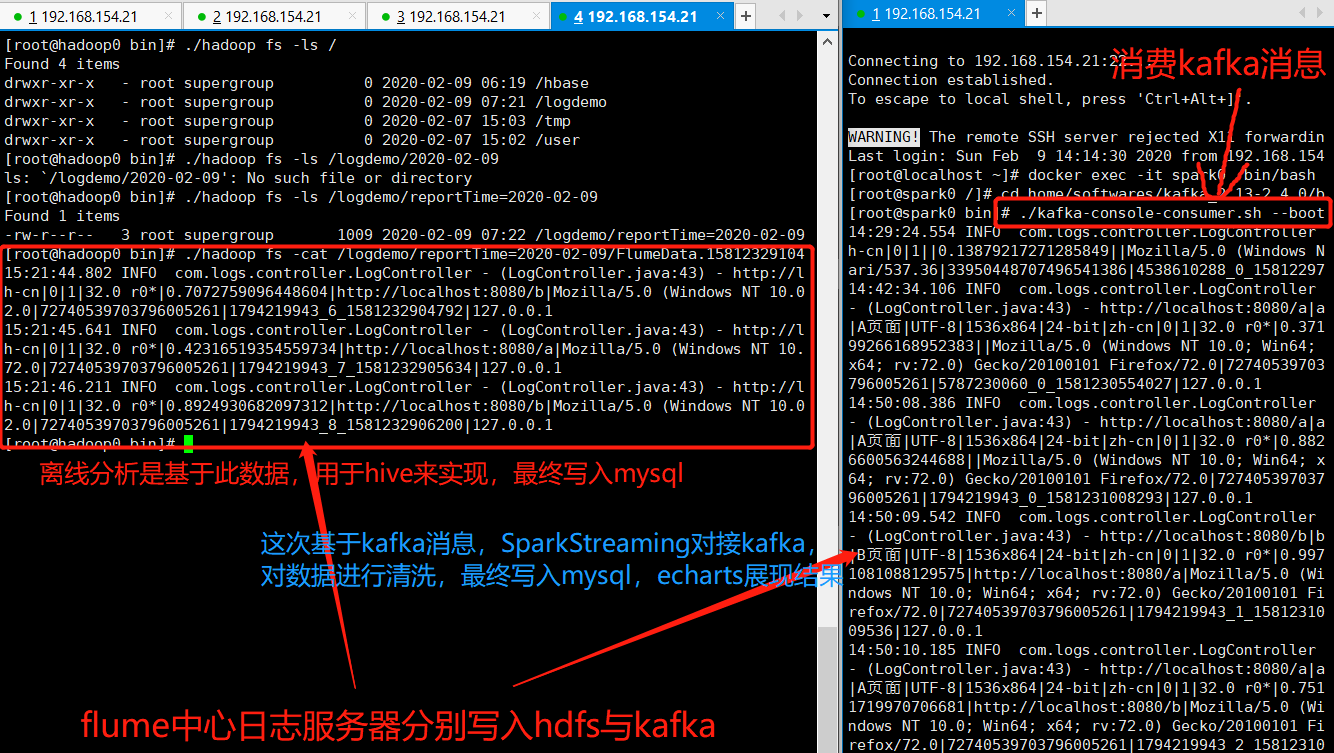
二、实时分析模块实现
以上部分,数据已经写入kafka,只需spark消费其中数据,进行清洗,落地至Mysql即可,最终以echarts展现
代码地址:https://github.com/Simple-Coder/log-demo
1、Maven代码

2、实现效果
用户通过点击页面,JS代码采集信息,发送至日志服务器,日志服务器转而发送至Flume,Flume分别落地HDFS(离线分析)与Kafka(实时分析),SparkStreaming消费Kafka消息,对数据进行清洗,HBase用于存放中间数据,最终落地至Mysql(基于Docker容器启动)

至此、架构图内容已经全部实现,最后一步:数据可视化--------网站日志流量分析系统之数据可视化展示
三、数据可视化
Scala实现网站流量实时分析的更多相关文章
- 使用Docker搭建Spark集群(用于实现网站流量实时分析模块)
上一篇使用Docker搭建了Hadoop的完全分布式:使用Docker搭建Hadoop集群(伪分布式与完全分布式),本次记录搭建spark集群,使用两者同时来实现之前一直未完成的项目:网站日志流量分析 ...
- 网站日志实时分析工具GoAccess使用
网站日志实时分析工具GoAccess使用 系统环境CentOS release 5.5 (Final) GoAccess是一款开源的网站日志实时分析工具. GoAccess 的工作方式就是读取和解析 ...
- Linux-某电商网站流量劫持案例分析与思考
[前言] 自腾讯与京东建立了战略合作关系之后,笔者网上购物就首选京东了.某天在家里访问京东首页的时候突然吃惊地发现浏览器突然跳到了第三方网站再回到京东,心里第一个反应就是中木马了. 竟然有这样的事,一 ...
- 网站流量统计系统 phpMyVisites
phpMyVisites是一个网站流量统计系统,它能够提供非常详细的统计报告和高级图形报表.phpMyVisites不是一个Apache log分析工具,它建有自己的log.它的特点包括: 安装部署: ...
- cnzz友盟怎么安装网站统计代码监控网站流量
做网站的都知道cnzz统计,它是用来统计网站流量的,可以分析网站数据,进行更好的对网站优化,下面我教大家怎么添加统计代码 工具/原料 cnzz 方法/步骤 打开百度搜索"cnzz友盟&quo ...
- Kaggle网站流量预测任务第一名解决方案:从模型到代码详解时序预测
Kaggle网站流量预测任务第一名解决方案:从模型到代码详解时序预测 2017年12月13日 17:39:11 机器之心V 阅读数:5931 近日,Artur Suilin 等人发布了 Kaggl ...
- 教程 | Kaggle网站流量预测任务第一名解决方案:从模型到代码详解时序预测
https://mp.weixin.qq.com/s/JwRXBNmXBaQM2GK6BDRqMw 选自GitHub 作者:Artur Suilin 机器之心编译 参与:蒋思源.路雪.黄小天 近日,A ...
- 网站流量分析指标-PV/UV/PR/ip分析及区别
1.什么是pv? PV(page view),即页面浏览量,或点击量;通常是衡量一个网络新闻频道或网站甚至一条网络新闻的主要指标. 高手对pv的解释是,一个访问者在24小时(0点到24点)内到底看了你 ...
- 网站流量统计之PV和UV
转自:http://blog.csdn.NET/webdesman/article/details/4062069 如果您是一个站长,或是一个SEO,您一定对于网站统计系统不会陌生,对于SEO新手来说 ...
随机推荐
- Linux常用命令: zip、unzip 压缩和解压缩命令
zip基本用法是: zip [参数] [打包后的文件名] [打包的目录路径] 常用参数: -a 将文件转成ASCII模式 -F 尝试修复损坏的压缩文件 -h 显示帮助界面 -m 将文件压缩之后,删除源 ...
- (转)进程同步之临界区域问题及Peterson算法
转自:http://blog.csdn.net/speedme/article/details/17595821 1. 背景 首先,看个例子,进程P1,P2共用一个变量COUNT,初始值为0 ...
- Vue 实例挂载的实现(六)
Vue 中我们是通过 $mount 实例方法去挂载 vm 的,$mount 方法在多个文件中都有定义,如 src/platform/web/entry-runtime-with-compiler.js ...
- JDBC添加为null的数据报错
定义实体类的时候定义为了基本数据类型,不能接收null需要改为引用数据类型
- 《深入理解Java虚拟机》读书笔记六
第七章 虚拟机类加载机制 1.类加载的时机 虚拟机的类加载机制: 虚拟机把描述类的数据从class文件中加载到内存,并对数据进行校验.转换解析和初始化,最终形成了可以被虚拟机直接使用的Java类型,这 ...
- Linux system basic 2 + add kernel for Jupyter
Linux install LibreOffice: install LibreOffice: install command: sudo apt install ./XXX.deb PS: don' ...
- python3练习100题——011
原题链接:http://www.runoob.com/python/python-exercise-example11.html 题目:古典问题:有一对兔子,从出生后第3个月起每个月都生一对兔子,小兔 ...
- .Net中C# Dictionary 用法
Dictionary提供快速的基于键值的元素查找. 结构是:Dictionary <[key] , [value] >,当你有很多元素的时候可以用它. 它包含在System.Collect ...
- MANIFEST.MF详解及配置的注意事项
一.详解 打开Java的JAR文件我们经常可以看到文件中包含着一个META-INF目录, 这个目录下会有一些文件,其中必有一个MANIFEST.MF,这个文件描述了该Jar文件的很多信息,下面将详细介 ...
- thows,thow和try catch的区别
1.throw是当前方法不处理这个异常,由它的上一级进行处理.并且抛出异常后将停止执行代码. package myProject; public class ExceptionTest { //测试t ...