centos7搭建hadoop2.10伪分布模式
1.准备一台Vmware虚拟机,添加hdfs用户及用户组,配置网络见 https://www.cnblogs.com/qixing/p/11396835.html
在root用户下
添加hdfs用户,并设置密码:
adduser hdfs
passwd hdfs
将hdfs用户添加到hdfs用户组中
usermod -a -G hdfs hdfs
前面一个hdfs是组名,后面一个hdfs是用户名
验证用户和用户组:
cat /etc/group
会看到 hdfs:x:1001:hdfs
将hdfs用户赋予root权限,在sudoers文件中添加hdfs用户并赋予权限
vim /etc/sudoers
在
root ALL=(ALL) ALL
下面添加:
hdfs ALL=(ALL) ALL
保存编辑后,hdfs就拥有root权限
本人习惯将软件安装到/opt/soft文件夹下
在/opt/下创建soft文件夹,并改为hdfs用户拥有
cd /opt
mkdir soft
chown -R hdfs:hdfs soft
2.安装jdk,配置环境变量
将jdk安装包解压到 /opt/soft/ 下
tar -zxvf jdk-8u231-linux-x64.tar.gz -C /opt/soft/
在/opt/soft/下就会出现jdk加压文件夹 jdk1.8.0_231 文件夹 带有jdk版本号,但是一般我们使用jdk时带着版本号不太方便,也为以后升级能够改动更小,一般我们会给jdk创建一个软连接,这样我们只要配置软连接名字,或者升级时,将软连接指向新jdk就可以了
ln -s jdk1..0_231 jdk
这样我们就给jdk1.8.0_231创建一个jdk软连接,我们只使用jdk软连接就可以了

给jdk配置环境变量
vim /etc/profile
添加
# jdk
export JAVA_HOME=/opt/soft/jdk
export PATH=$PATH:$JAVA_HOME/bin
重新编译profile文件
source /etc/profile
3.安装hadoop2.10.0
将hadoop2.10.0安装包解压到/opt/soft目录下
tar -zxvf hadoop-2.10..tar.gz -C /opt/soft/
创建hadoop软链接
ln -s hadoop-2.10. hadoop

配置hadoop环境变量
vim /etc/profile
添加
# hadoop
export HADOOP_HOME=/opt/soft/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
重新编译profile文件
source /etc/profile
验证hadoop安装是否成功:
hadoop version

安装成功
配置hadoop伪分布:
配置hadoop配置文件core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml
core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost/</value>
</property>
hdfs-site.xml
<property>
<name>dfs.replication</name>
<value></value>
</property>
mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
4.hadoop在使用时会使用ssh免密登录,我们就需要配置ssh免密登录
1)检查是否安装了ssh相关软件包(openssh-server + openssh-clients + openssh)
$> yum list installed | grep ssh
2)检查是否启动了sshd进程
$> ps -Af | grep sshd
3)在client侧生成公私秘钥对。
$> ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
4)生成~/.ssh文件夹,里面有id_rsa(私钥) + id_rsa.pub(公钥)
5)追加公钥到~/.ssh/authorized_keys文件中(文件名、位置固定)
$> cd ~/.ssh
$> cat id_rsa.pub >> authorized_keys
6)修改authorized_keys的权限为644.
$> chmod 644 authorized_keys
7)测试
$> ssh localhost
5.在hdfs用户下格式化hadoop
如果是在root用户下,可以使用su进入hdfs用户
su - hdfs
格式化hdfs
hadoop namenode -format

这样就格式化成功了
启动hdfs,启动命令在hadoop/sbin下的start-all.sh,由于我们已经将sbin加入到PATH中,所有我们现在可以在任何地方执行该命令
start-all.sh
但是hdfs没有像我们预想的一样起来,似乎报错了

hadoop找不到jdk环境变量
这时就需要我们修改hadoop配置文件,手动指定JAVA_HOME环境变量
[${HADOOP_HOME}/etc/hadoop/hadoop-env.sh]
...
export JAVA_HOME=/opt/soft/jdk
...
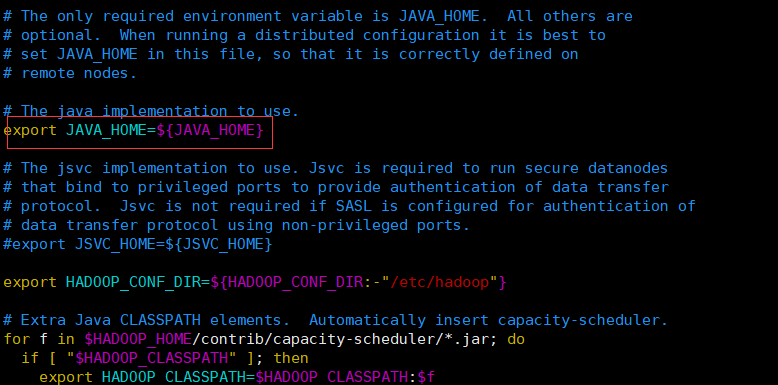
改为

再重新启动hadoop
start-all.sh

看着似乎是起来了
我们查看一下进程
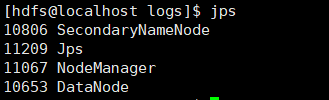
似乎少了namenode
查看namenode启动日志,进入到${HADOOP_HOME}/logs下
tail -200f hadoop-hdfs-namenode-localhost.log

namenode 启动报错了
Directory /tmp/hadoop-hdfs/dfs/name is in an inconsistent state: storage directory does not exist or is not accessible.?dfs/name文件夹不存在或没有访问权限,但是为什么刚装完时是存在的呢
进入/tmp/hadoop-hdfs/dfs/下看一下,果然没有name文件夹

于是抱着试试的心理,又重新格式化了hadoop
hadoop namenode -format
再看name文件夹是否存在

这次出来了
再次重启hdfs
先stop
stop-all.sh
重新启动
start-all.sh
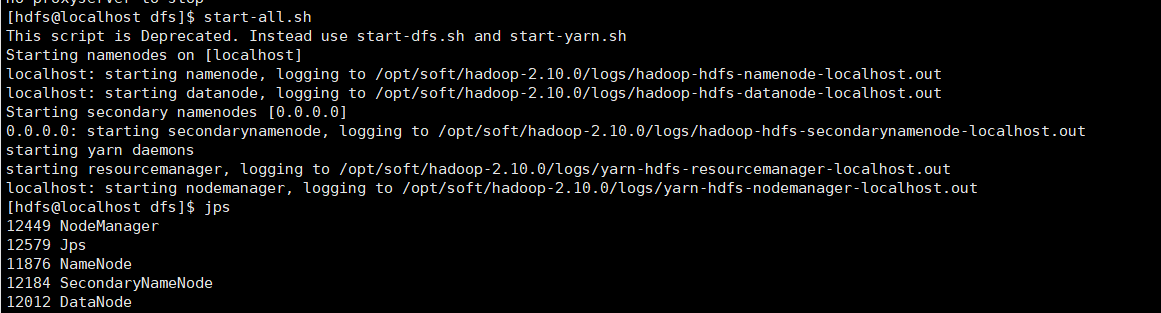
namenode已经起来了
我们通过浏览器验证一下是否启动,在浏览器中输入:http://192.168.30.141:50070 ,根据自己的IP修改
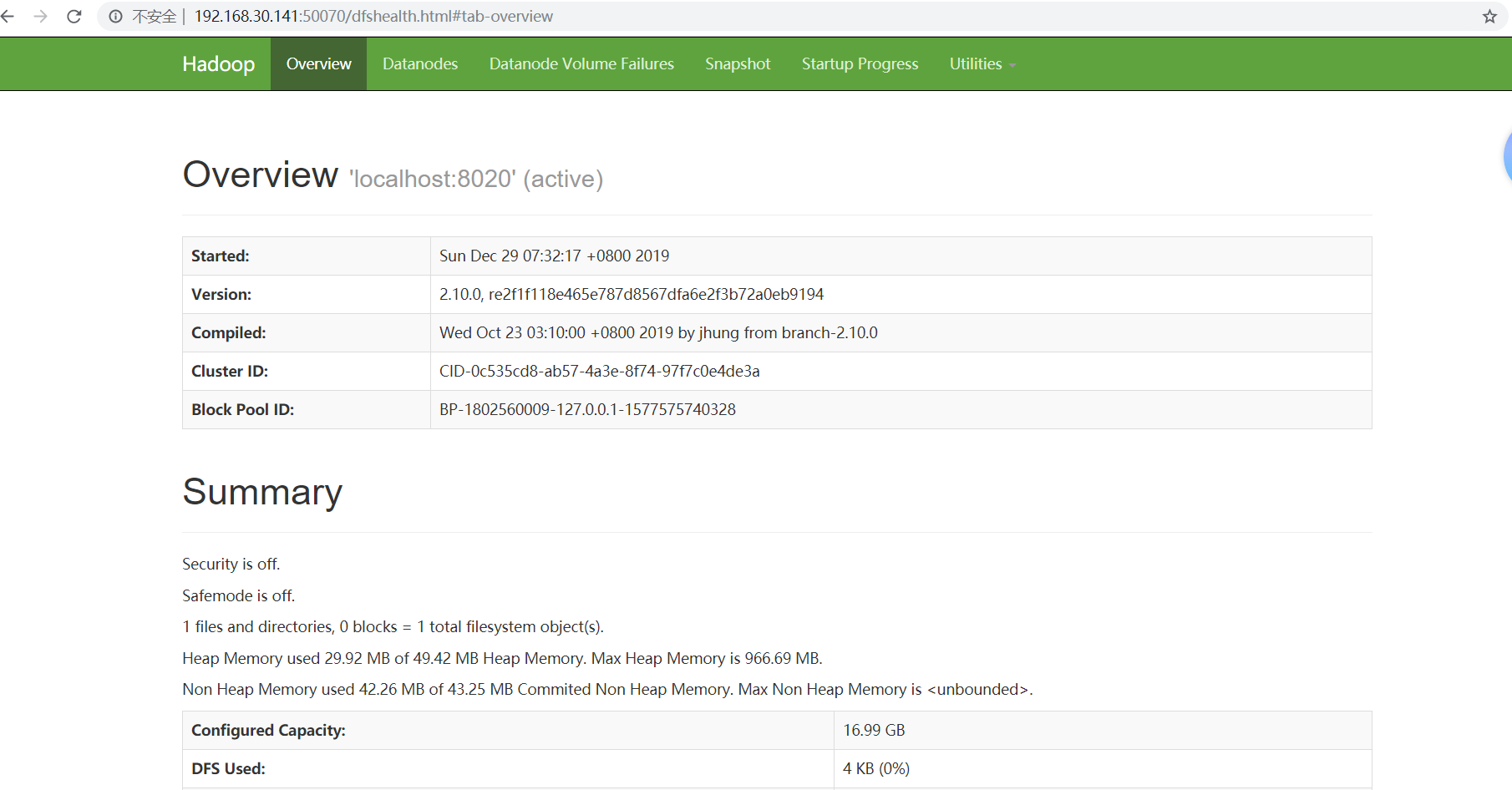
看到这个页面说明hadoop伪分布模式已经启动,如果网页无法访问,先看一下服务器的防火墙是否关闭
firewall-cmd --state

我这里已经将防火墙关闭
如果没有关闭,使用如下命令关闭(需在root用户下进行,否则没有权限),再查看网页是否正常:
停止firewall,这样在下次重启机器,会失效
systemctl stop firewalld.service
如果想一直关闭防火墙,请禁止firewall开机启动
centos7搭建hadoop2.10伪分布模式的更多相关文章
- centos7搭建hadoop2.10高可用(HA)
本篇介绍在centos7中搭建hadoop2.10高可用集群,首先准备6台机器:2台nn(namenode);4台dn(datanode):3台jns(journalnodes) IP hostnam ...
- centos7搭建hadoop2.10完全分布式
本篇介绍在centos7中大家hadoop2.10完全分布式,首先准备4台机器:1台nn(namenode);3台dn(datanode) IP hostname 进程 192.168.30.141 ...
- centos7搭建hadoop-2.7.3,zookeeper-3.4.6,hbase-1.2.5(root用户)
环境:[centos7.hadoop-2.7.3.zookeeper-3.4.6.hbase-1.2.5] 两个节点:[主节点,主机名为Master,用户为root:从节点,主机名为Slave,用户为 ...
- CentOS7搭建Hadoop2.8.0集群及基础操作与测试
环境说明 示例环境 主机名 IP 角色 系统版本 数据目录 Hadoop版本 master 192.168.174.200 nameNode CentOS Linux release 7.4.1708 ...
- CentOS7搭建hadoop2.6.4+HBase1.1.6
环境: CentOS7 hadoop2.6.4两个节点:master.slave1 HBase1.1.6 过程: hadoop安装目录:/usr/hadoop-2.6.4 master节点,hadoo ...
- CentOS7搭建hadoop2.6.4双节点集群
环境: CentOS7+SunJDK1.8@VMware12. NameNode虚拟机节点主机名:master,IP规划:192.168.23.101,职责:Name node,Secondary n ...
- 18-基于CentOS7搭建RabbitMQ3.10.7集群镜像队列+HaProxy+Keepalived高可用架构
集群架构 虚拟机规划 IP hostname 节点说明 端口 控制台地址 192.168.247.150 rabbitmq.master rabbitmq master 5672 http://192 ...
- Centos7 搭建hadoop2.6 HA
用户配置: User :root Password:toor 2.创建新用户 student Pwd: student 3.安装virtualbox的增强工具软件 4.系统默认安装的是openjdk ...
- hadoop-2.10.0安装hive-2.3.6
公司建立数仓,hive是必不可少的,hive是建立在hadoop基础上的数据库,前面已经搭建起了hadoop高可用,要学习hive,先从搭建开始,下面梳理一下hive搭建过程 1.下载hive安装包 ...
随机推荐
- 文字内容展开与折叠jquery代码
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- oralce分析函数如何工作
语法 FUNCTION_NAME(<参数>,…) OVER (<PARTITION BY 表达式,…> <ORDER BY 表达式 <ASC DESC> &l ...
- LeetCode63 Unique Paths II
题目: Follow up for "Unique Paths": Now consider if some obstacles are added to the grids. H ...
- Hbase数据模型 行
- Mysql统计信息处理及binlog解释
TODO use db_name; -- 分析表 ANALYZE TABLE table_name; -- 查看表信息 ; -- 查看索引 SHOW INDEX FROM table_name; ht ...
- js实现圆形的碰撞检测
文章地址:https://www.cnblogs.com/sandraryan/ 碰撞检测这个东西写小游戏挺有用der~~~ 注释写的还挺全,所以就不多说了,看注释 这是页面结构.wrap存放生成的小 ...
- Python--day67--Jsonresponse响应介绍和路由系统的分组命名匹配方式(简单介绍)
1,Jsonresponse响应介绍: ,2,路由系统的分组命名匹配方式:(简单介绍)
- Centos下添加用户到用户组
将一个用户添加到用户组中,千万不能直接用: usermod -G groupA 这样做会使你离开其他用户组,仅仅做为 这个用户组 groupA 的成员. 应该用 加上 -a 选项: usermod - ...
- H3C 链路聚合显示及维护
- 洛谷4139 bzoj 3884 上帝与集合的正确用法
传送门 •题意 求$2^{2^{2^{2^{2^{2^{...^{2}}}}}}}$ (无穷个2) 对p取模的值 •思路 设答案为f(p) $2^{2^{2^{2^{2^{2^{...^{2}}}}} ...