近两年AI成了最火热领域的代名词,各大高校纷纷推出了人工智能专业。但其实,人工智能也好,还是前两年的深度学习或者是机器学习也罢,都离不开底层的数据支持。对于动辄数以TB记级别的数据,显然常规的数据库是满足不了要求的。今天,我们就来看看大数据时代的幕后英雄——Hadoop。
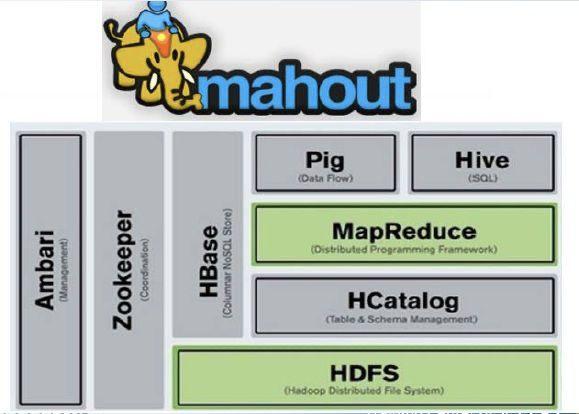
Hadoop这个关键词其实有两重含义,最早它其实指的就是单纯的分布式计算系统。但是随着时代的发展,Hadoop系统扩大,如今hadoop已经是成了一个完整的技术家族。从底层的分布式文件系统(HDFS)到顶层的数据解析运行工具(Hive、Pig),再到分布式系统协调服务(ZooKeeper)以及分布式数据库(HBase),都属于Hadoop家族,几乎涵盖了大半大数据的应用场景。在Spark没有流行之前,Hadoop一直是大数据应用中的绝对主流,即使是现在,依旧有大量的中小型公司,还是依靠Hadoop搭建大数据系统。
如今的Hadoop虽然家族庞大,但是早年Hadoop的结构非常简单,几乎只有两块,一块是分布式文件系统,这个是整个数据的支撑,另一个就是MapReduce算法。
大数据时代,数据的量级大规模增长,动辄以TB甚至PB计。对于这么海量的数据,如果我们还使用常规的方法是非常困难的。因为即使是 O(n) 的算法,将所有的数据遍历一遍,所消耗的时间也肯定是以小时计,这显然是不能接受的。不仅如此,像是MySQL这样的数据库对于数据规模也是有限制的,一旦数据规模巨大,超过了数据库的承载能力,那几乎是系统级的噩梦(重要的数据不能丢弃,但是现在的系统无法支撑)。
既然我们把数据全部存储在一起,会导致系统问题,那么我们可不可以把数据分成很多份分别存储,当我们需要处理这些数据的时候,我们对这些分成许多小份的数据分别处理,最后再合并在一起?
答案当然是可行的,Hadoop的文件系统正是基于这个思路。
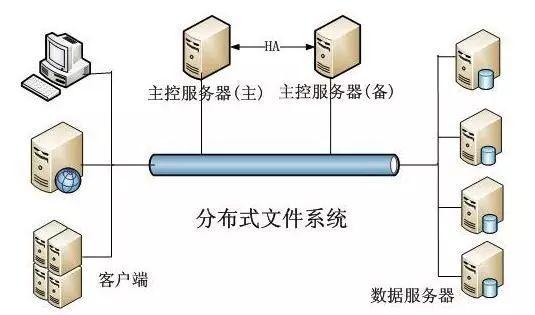
在HDFS当中,将数据分割成一个一个的小份。每个小份叫做一个存储块,每个存储块为64MB。这样一个巨大的文件会被打散存储在许多存储块当中。当我们需要操作这些数据的时候,Hadoop会同时起动许多个执行器(executor)来并发执行这些存储块。理论上来说,执行器的数量越多,执行的速度也就越快。只要我们有足够多的执行器,就可以在短时间内完成海量数据的计算工作。
但是有一个小问题,为什么每个存储块偏偏是64MB,而不是128MB或者256MB呢?
原因也很简单,因为数据存储在硬盘上,当我们查找数据的时候,CPU其实是不知道数据究竟存放在什么地方的。需要有一个专门的程序去查找数据的位置,这个过程被称为寻址。寻址的时候会伴随着硬盘的高速旋转。硬盘的旋转速度是有限的,自然我们查找文件的速度也会存在瓶颈。如果存储块太小,那么存储块的数量就会很多,我们寻址的时间就会变长。
如果存储块设置得大一些行不行?也不行,因为我们在执行的时候,需要把存储块的数据拷贝到执行器的内存里执行。这个拷贝伴随着读写和网络传输的操作,传输数据同样耗时不少。存储块过大,会导致读写的时间过长,同样不利于系统的性能。根据业内的说法,希望寻址的耗时占传输时间的1%,目前的网络带宽最多可以做到100MB/s,根据计算,每个存储块大约在100MB左右最佳。也许是程序员为了凑整,所以选了64MB这个大小。
目前为止,我们已经搞清楚了Hadoop内部的数据存储的原理。那么,Hadoop又是怎么并发计算的呢?这就下一个关键词——MapReduce出场了。
严格说起来MapReduce并不是一种算法, 而是一个计算思想。它由map和reduce两个阶段组成。
先说map,MapReduce中的map和Java或者是C++以及一些其他语言的map容器不同,它表示的意思是映射。负责执行map操作的机器(称作mapper)从HDFS当中拿到数据之后,会对这些数据进行处理,从其中提取出我们需要用到的字段或者数据,将它组织成key->value的结构,进行返回。
为什么要返回key->value的结构呢?直接返回我们要用到的value不行吗?
不行,因为在map和reduce中间,Hadoop会根据key值进行排序,将key值相同的数据归并到一起之后,再发送给reducer执行。也就是说,key值相同的数据会被同一个reducer也就是同一台机器处理,并且key相同的数据连续排列。reducer做的是通过mapper拿到的数据,生成我们最终需要的结果。
这个过程应该不难理解, 但是初学者可能面临困惑,为什么一开始的时候,要处理成key-value结构的呢?为什么又要将key值相同的数据放入一个reducer当中呢,这么做有什么意义?
MapReduce有一个经典的问题,叫做wordCount,顾名思义就是给定一堆文本,最后计算出文本当中每个单词分别出现的次数。Map阶段很简单,我们遍历文本当中的单词,每遇到一个单词,就输出单词和数字1。写成代码非常简单:
def map(text): for line in text: words = line.split(' ') for w in words: print(w, 1)
这样当然还是不够的,我们还需要把相同的单词聚合起来,清点一下看看究竟出现了多少次,这个时候就需要用到reducer了。reducer也很简单,我们读入的是map输出的结果。由于key相同的数据都会进入同一个reducer当中,所以我们不需要担心遗漏,只需要直接统计就行:
def reduce(text): wordNow = None totCount = 0 for line in text: elements = line.split(' ') word, count = elements[0], int(elements[1]) # 碰到不同的key,则输出之前的单词以及数量 if word != wordNow: if wordNow is not None: print(wordNow, totCount) wordNow = word totCount = 1 #否则,更新totCount else: totCount += count
如果我们map的结果不是key-value结构,那么Hadoop就没办法根据key进行排序,并将key相同的数据归并在一起。那么我们在reduce的时候,同一个单词就可能出现在不同的reducer当中,这样的结果显然是不正确的。
当然,如果我们只做一些简单的操作,也可以舍弃reduce阶段,只保留map产出的结果。
现在看MapReduce的思想其实并不复杂,但是当年大数据还未兴起的时候,MapReduce横空出世,既提升了计算性能,又保证了结果的准确。一举解决了大规模数据并行计算的问题,回想起来,应该非常惊艳。虽然如今技术更新,尤其是Spark的流行,抢走了Hadoop许多荣光。但MapReduce的思想依旧在许多领域广泛使用,比如Python就支持类似的MapReduce操作,允许用户自定义map和reduce函数,对数据进行并行处理。
不过,MapReduce也有短板,比如像是数据库表join的操作通过MapReduce就很难实现。而且相比于后来的Hive以及Spark SQL来说,MapReduce的编码复杂度还是要大一些。但不管怎么说,瑕不掩瑜,对于初学者而言,它依旧非常值得我们深入了解。
- 大数据笔记10:大数据之Hadoop的MapReduce的原理
1. MapReduce(并行处理的框架) 思想:分而治之,一个大任务分解成多个小的子任务(map),并行执行后,合并结果(Reduce) (1)大任务分解成多个小任务,这个过程就是map: (2)多 ...
- 大数据:Hadoop入门
大数据:Hadoop入门 一:什么是大数据 什么是大数据: (1.)大数据是指在一定时间内无法用常规软件对其内容进行抓取,管理和处理的数据集合,简而言之就是数据量非常大,大到无法用常规工具进行处理,如 ...
- 大数据技术Hadoop入门理论系列之一----hadoop生态圈介绍
Technorati 标记: hadoop,生态圈,ecosystem,yarn,spark,入门 1. hadoop 生态概况 Hadoop是一个由Apache基金会所开发的分布式系统基础架构. 用 ...
- 大数据和Hadoop生态圈
大数据和Hadoop生态圈 一.前言: 非常感谢Hadoop专业解决方案群:313702010,兄弟们的大力支持,在此说一声辛苦了,经过两周的努力,已经有啦初步的成果,目前第1章 大数据和Hadoop ...
- 大数据测试之hadoop集群配置和测试
大数据测试之hadoop集群配置和测试 一.准备(所有节点都需要做):系统:Ubuntu12.04java版本:JDK1.7SSH(ubuntu自带)三台在同一ip段的机器,设置为静态IP机器分配 ...
- 老李分享:大数据框架Hadoop和Spark的异同 1
老李分享:大数据框架Hadoop和Spark的异同 poptest是国内唯一一家培养测试开发工程师的培训机构,以学员能胜任自动化测试,性能测试,测试工具开发等工作为目标.如果对课程感兴趣,请大家咨 ...
- 大数据与Hadoop
figure:first-child { margin-top: -20px; } #write ol, #write ul { position: relative; } img { max-wid ...
- Hadoop专业解决方案-第1章 大数据和Hadoop生态圈
一.前言: 非常感谢Hadoop专业解决方案群:313702010,兄弟们的大力支持,在此说一声辛苦了,经过两周的努力,已经有啦初步的成果,目前第1章 大数据和Hadoop生态圈小组已经翻译完成,在此 ...
- 细细品味大数据--初识hadoop
初识hadoop 前言 之前在学校的时候一直就想学习大数据方面的技术,包括hadoop和机器学习啊什么的,但是归根结底就是因为自己太懒了,导致没有坚持多长时间,加上一直为offer做准备,所以当时重心 ...
随机推荐
- Person Re-identification 系列论文笔记(一):Scalable Person Re-identification: A Benchmark
打算整理一个关于Person Re-identification的系列论文笔记,主要记录近年CNN快速发展中的部分有亮点和借鉴意义的论文. 论文笔记流程采用contributions->algo ...
- 18.libgdx制作预览图,背景移动循环,改变地图颜色
经过构思,游戏将分为两部分, 1,预览图,只负责展示世界形势 2,根据预览图生成的战役项 现在要记录的是我制作预览图的部分 1.预览图只有实际地图的1/4,首先生成地图(建议不要缩放以前地图,由于误差 ...
- 模板—Hash_map
struct Hash_map { ],nx[]; ];]; inline double &operator [] (int x) { ,i=fi[k]; for(;i&&st ...
- LeetCode59 Spiral Matrix II
题目: Given an integer n, generate a square matrix filled with elements from 1 to n2 in spiral order. ...
- 报错No module named IPython的解决方法
没有按照 ipython 或者 ide 没有选择编译器
- [***]HZOJ 柱状图
神仙题. 作者的正解: *logn). 算法三:对于100%的数据: 我们枚举屋顶位置再三分高度的做法,复杂度的瓶颈在于花费的计算.假设屋顶在i处,高度为hi,如果j<i,有hj-j=hi ...
- 20190608笔试题のCSS-属性继承
以下的CSS属性哪些可以继承?(单选) A. font-sizeB. marginC. widthD. padding emmm,这题答案是A,看到这题我是能选对的,但又不由让我想到一 ...
- hdu 2225 The nearest fraction (数学题)
Problem - 2225 一道简单数学题,要求求出一个分母不超过m的最接近sqrt(n)的分数. 做法就是暴力枚举,注意中间过程不能用浮点数比较,误差要求比较高. 代码如下: #include & ...
- 【BestCoder Round #93 1002】MG loves apple
[题目链接]:http://acm.hdu.edu.cn/showproblem.php?pid=6020 [题意] 给你一个长度为n的数字,然后让你删掉k个数字,问你有没有删数方案使得剩下的N-K个 ...
- hdu 1358 Period (KMP求循环次数)
Problem - 1358 KMP求循环节次数.题意是,给出一个长度为n的字符串,要求求出循环节数大于1的所有前缀.可以直接用KMP的方法判断是否有完整的k个循环节,同时计算出当前前缀的循环节的个数 ...