elasticsearch(lucene)索引数据过程
倒排索引存储-分段存储(lucene的功能)
在lucene中:lucene index包含了若干个segment
在elasticsearch中:index包含了若干主从shard,shard包干了若干segment
segment是elasticsearch中存储的最小文件单元,也就是分段存储,segment被设计为不可变的
新增:新创建索引时,新建一个segment存储新的数据
删除:由于segment是只读的,所以在索引文件中新增了.del文件,专门存储被删除的数据id,当查询时被删除的数据仍能被查询,进行查询结果合并时才会过滤掉,merge segment时会真正删除
更新:新增和删除的组合
segment的不可变性的优点
- 不需要锁(没有直接修改已经存在段的情况)
- 可以利用内存,由于segment不可变,所以segment被加载到内存后无需改变,只要内存足够,segment就可以长期驻村,大大提升查询性能
- 更新、新增的增量的方式很轻,性能好
segment的不可变性的缺点
- 删除操作不会马上删除有一定的空间浪费
- 频繁更新涉及到大量的删除动作,会有大量的空间浪费
- segment的数量可能非常多,对服务器的文件句柄消耗很大,查询性能会随着segment的数量增加而增加
新增数据的过程
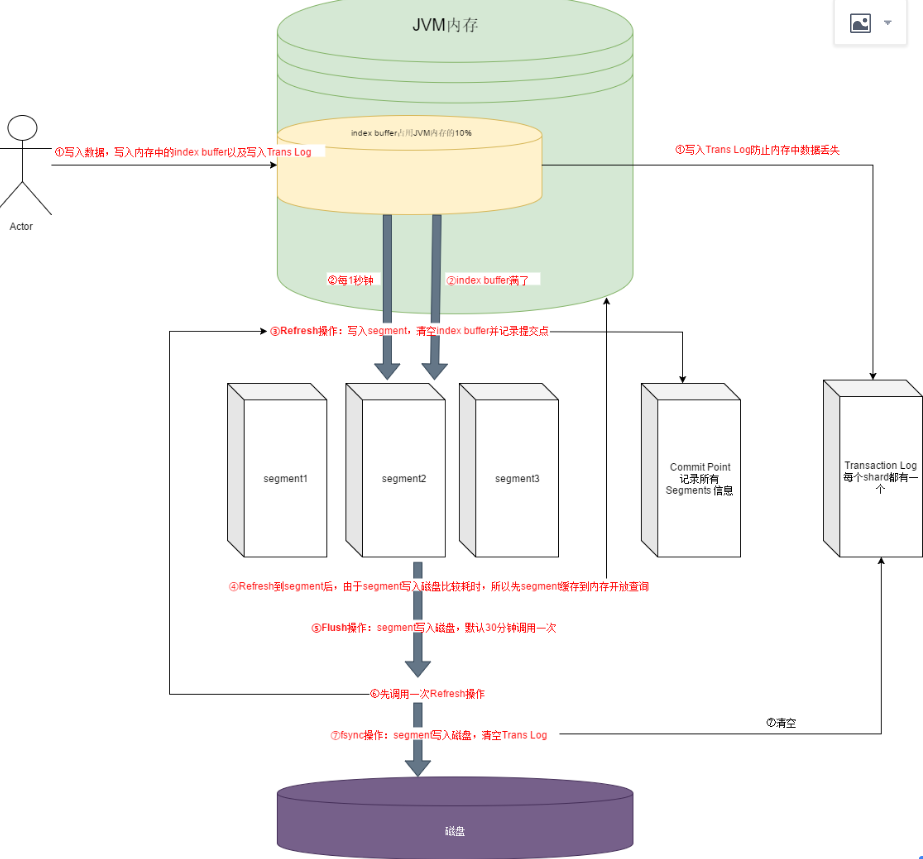
这个流程的目的是:提升写入性能(异步落盘)
1、保存到index buffer中,同时写入Transaction log(防止内存的数据丢失,有点想redo log)
2、当index buffer空间满了(默认占用jvm10%)或每1秒(通过index.refresh_interval 配置)执行Refresh操作,写入segment并清空index buffer(这里的1秒内是查不到刚保存的数据的,所以es也被成为近实时的搜索引擎)
3、于此同时将segment刷入内存,开放查询
4、flush操作将segment写入磁盘(默认30分钟执行一次)
flash操作包含:
- 调用一次refresh
- fsync:将segment写入磁盘
- 清空对应的trans log

elasticsearch(lucene)索引数据过程的更多相关文章
- ES 18 - (底层原理) Elasticsearch写入索引数据的过程 以及优化写入过程
目录 1 Lucene操作document的流程 1.1 添加document的流程 1.2 删除document的流程 2 优化写入流程 - 实现近实时搜索 2.1 流程的改进思路 2.2 设置re ...
- Heka–>Elasticsearch 索引数据过程的优化
Heka 的参数配置跟Elasticsearch的参数没有关系,Heka只负责按照配置发送数据,所以索引的优化主要在 Elaticsearch端来完成. 下面是Elasticsearch的一些相关概念 ...
- elasticsearch批量索引数据示例
示例数据文件document.json(index表示在索引中增加或替换现有文档,create表示如果文档不存在则添加文档,delete表示删除文档): { "index": { ...
- 使用Flink实现索引数据到Elasticsearch
使用Flink实现索引数据到Elasticsearch 2018-07-28 23:16:36 Yanjun 使用Flink处理数据时,可以基于Flink提供的批式处理(Batch Proce ...
- Lucene学习总结之四:Lucene索引过程分析
对于Lucene的索引过程,除了将词(Term)写入倒排表并最终写入Lucene的索引文件外,还包括分词(Analyzer)和合并段(merge segments)的过程,本次不包括这两部分,将在以后 ...
- Lucene学习总结之四:Lucene索引过程分析 2014-06-25 14:18 884人阅读 评论(0) 收藏
对于Lucene的索引过程,除了将词(Term)写入倒排表并最终写入Lucene的索引文件外,还包括分词(Analyzer)和合并段(merge segments)的过程,本次不包括这两部分,将在以后 ...
- Lucene学习笔记: 四,Lucene索引过程分析
对于Lucene的索引过程,除了将词(Term)写入倒排表并最终写入Lucene的索引文件外,还包括分词(Analyzer)和合并段(merge segments)的过程,本次不包括这两部分,将在以后 ...
- Elasticsearch Lucene 数据写入原理 | ES 核心篇
前言 最近 TL 分享了下 <Elasticsearch基础整理>https://www.jianshu.com/p/e8226138485d ,蹭着这个机会.写个小文巩固下,本文主要讲 ...
- 使用Lucene索引和检索POI数据
1.简介 关于空间数据搜索,以前写过<使用Solr进行空间搜索>这篇文章,是基于Solr的GIS数据的索引和检索. Solr和ElasticSearch这两者都是基于Lucene实现的,两 ...
随机推荐
- vue-learning:10-template-ref
使用ref直接访问DOM元素 传统DOM操作或jQuery操作DOM,都必须是选择器先选择对应的DOM元素.比如: <button id="btn">按钮</bu ...
- node-sass安装报错
npm install --save-dev node-sass --registry=https://registry.npm.taobao.org --disturl=https://npm.ta ...
- linux 搭建jenkins
一.什么是持续集成? (1)Continuous integration(CI) 持续集成是一种软件开发实践,即团队开发成员经常集成他们的工作,通常每个成员至少集成一次,也就意味着每天可能会发生多次集 ...
- CITRIX VPX配置四层负载
网络拓扑如下: Step1:开启四层负载特性 在Configuration->Traffic Management->Load Balancing上右键弹出菜单点击enable,如下图: ...
- Spring Boot中路径及配置文件读取问题
编译时src/main/java中*.java文件会被编译成*.class文件,在classpath中创建对应目录及class文件 src/main/resources目录中的文件 ...
- windows下PostgreSQL 安装与配置
下载地址 https://www.postgresql.org/download/ Download the installer certified by EnterpriseDB for all s ...
- $loj\ 6045$ [雅礼集训 $2017\ Day8$] 价 网络流
正解:网络流 解题报告: 传送门$QwQ$ 这题还,挺有趣的我$jio$得. 考虑依然先是照着最小割的模子建图呗,然后从意义上来分析,割一条边就相当于不吃一种减肥药/买一种药材.由已知得,买的药材数量 ...
- FTP服务器红帽5.4搭建图文教程!!!
FTP服务器搭建 服务器的环境 红帽5.4 vm15 挂载光盘 mount mount -t iso9660 设备目录 /mnt 表示挂载 软件包安装 FTP服务器安装包命令: rpm -ivh /m ...
- HashMap,HashTable 区别,实现原理。
HashMap是HashTable 的轻量级,非线程安全的,都是实现了map接口 区别:hashmap 允许空键值对的存在,非线程安全,效率高于hashtable,因为hashtable 是synch ...
- oracle官网下载jdk跑不动太慢了,给出快速下载方式mac
oracle官网下载jdk8跑不动太慢了,给出快速下载方式 之前在oracle官网下载jdk1.8实在速度太慢,只有20K左右的下载速度,有时候甚至不动,最关键的慢也就算了,cookie有效期有限,有 ...