python3-常用模块之re
正则表达式
定义:
正则表达式是对字符串操作的一种逻辑公式,用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
是一种独立的规则,独立的语言。只和字符串打交道。
能做什么?
例子1:把一个文件中所有的手机号码都找出来;
# open打开文件
# 读文件 str
# 从一长串的字符串中找到所有的11位数字
# 一个字符一个字符的读
例子2:爬虫,从网页的字符串中获取你想要的数据
例子3:提取特定日志内容
规则
字符组:
[] 写在中括号中的内容,都出现在下面的某一个字符的位置上都是符合规则的
[0-9] 匹配数字
[a-z] 匹配小写字母
[A-Z] 匹配大写字母
[4-9] 匹配4到9数字
[a-zA-Z] 匹配大小写字母
[a-zA-Z0-9] 匹配大小写字母+数字
[a-zA-Z0-9_] 匹配数字字母下滑线
转义符+元字符
\w 匹配数字字母下滑线 word关键字 [a-zA-Z0-9_]
\d 匹配所有的数字 digit [0-9]
\s 匹配所有的空白符 回车/换行符 制表符 空格 space [\n\t ]
\W \D \S 和\w \d \s取反
\b 表示单词的边界
[\s\S] [\d\D] [\w\W] 三组全集 意思是匹配所有字符
和转义字母相关的 元字符
\w \d \s(\n\t) \b \W \D \S
元字符
^ 匹配一个字符串的开始
$ 匹配一个字符串的结束
. 表示匹配除换行符之外的所有字符
[] 只要出现在中括号内的内容都可以被匹配
[^] 只要不出现在中括号中的内容都可以被匹配
a|b 或 符合a规则的或者b规则的都可以被匹配
# 如果a规则是b规则的一部分,且a规则比b规则要苛刻/长,就把a规则写在前面
# 将更复杂的\更长的规则写在最前面
() 分组 表示给几个字符加上量词约束的需求的时候,就给这些量词分在一个组
量词
{n}表示 这个量词之前的字符出现n次
{n,} 表示这个量词之前的字符至少出现n次
{n,m} 表示这个量词之前的字符出现n-m次
? 表示匹配量词之前的字符出现 0次 或者 1次 表示可有可无
+ 表示匹配量词之前的字符出现 1次 或者 多次
* 表示匹配量词之前的字符出现 0次 或者 多次
练习:
匹配整数 \d+
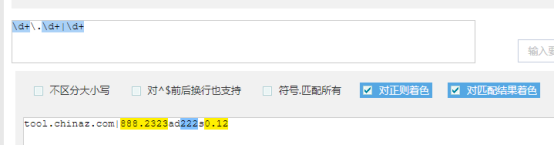
匹配小数 \d+\.\d+
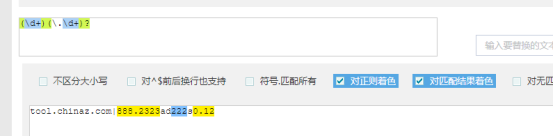
匹配小数或者整数 \d+\.\d+|\d+ \d+(\.\d+)?
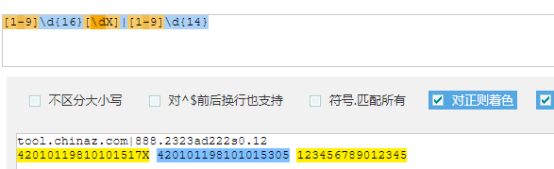
匹配身份证号(暂不考虑校验规则):
[1-9]\d{14}(\d{2}[\dX])?

[1-9]\d{16}[\dX]|[1-9]\d{14}
贪婪匹配
在允许的范围内取最长的结果
非贪婪模式/惰性匹配 : 在量词的后面加上?
.*?x 匹配任意非换行符字符任意长度 直到遇到x就停止
字符+量词 约束一个字符连续出现的次数
字符+量词+? 约束一个字符连续出现的最少次数
字符+量词+?+x 约束一个字符连续出现量词范围内的最少次数,遇到x就立即停止
以上都是正则表达式自身的规则,与python没有毛关系
Re模块
findall : 匹配所有 每一项都是列表中的一个元素

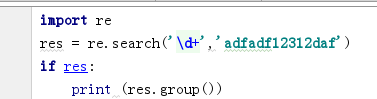
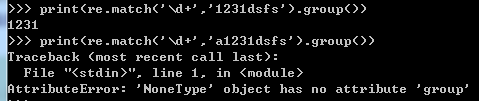
search : 只匹配从左到右的第一个,得到的不是直接的结果,而是一个变量,通过这个变量的group方法来获取结果

如果没有匹配到,会返回None,使用group会报错

程序中一般都是这样使用:
match:从头开始匹配,相当于search中的正则表达式加上一个^
字符串处理的扩展 : 替换 切割
split

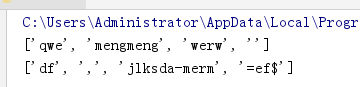
sub 旧的 新的 替换次数

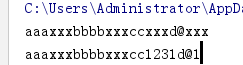
subn 返回一个元组,第二个元素是替换的次数


compile 模块 节省时间
直接把正则表达式编译成字节码,在多次使用的过程中,不会多次编译
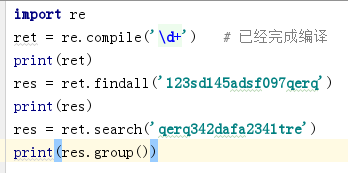
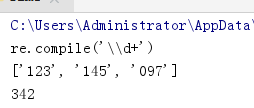
finditer 节省使用正则表达式解决问题的空间/内存
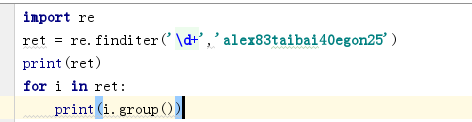
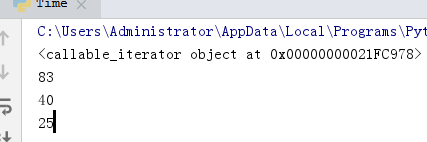
分组
group()表示总体匹配出的内容,group(num)表示匹配出第num个分组
import re
s = "<a>happy every day</a>"
res = re.search('(<\w+>)([\w\W]+)(</\w+>)',s)
print(res.group()) # 所有结果
print(res.group(1)) # 数字代表第几个分组
print(res.group(2))
print(res.group(3))
输出
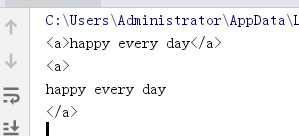
Findall 优先级
ret = re.findall('www.(baidu|sina).com', 'www.sina.com')
print(ret) # ['sina'] 这是因为findall会优先把匹配结果组里内容返回,如果想要匹配结果,取消权限即可
ret = re.findall('www.(?:baidu|sina).com', 'www.sina.com')
print(ret) # ['www.sina.com']
flags有很多可选值:
re.I(IGNORECASE)忽略大小写,括号内是完整的写法
re.M(MULTILINE)多行模式,改变^和$的行为
re.S(DOTALL)点可以匹配任意字符,包括换行符
re.L(LOCALE)做本地化识别的匹配,表示特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境,不推荐使用
re.U(UNICODE) 使用\w \W \s \S \d \D使用取决于unicode定义的字符属性。在python3中默认使用该flag
re.X(VERBOSE)冗长模式,该模式下pattern字符串可以是多行的,忽略空白字符,并可以添加注释
python3-常用模块之re的更多相关文章
- python3 常用模块详解
这里是python3的一些常用模块的用法详解,大家可以在这里找到它们. Python3 循环语句 python中模块sys与os的一些常用方法 Python3字符串 详解 Python3之时间模块详述 ...
- python3 常用模块
一.time与datetime模块 在Python中,通常有这几种方式来表示时间: 时间戳(timestamp):通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量.我们 ...
- Python3常用模块的安装
1.mysql驱动:mysql-connector-python 1.安装 $ pip3 install mysql-connector-python --allow-external mysql-c ...
- Python3 常用模块3
目录 numpy模块 创建numpy数组 numpy数组的属性和用法 matplotlib模块 条形图 直方图 折线图 散点图 + 直线图 pandas模块 numpy模块 numpy模块可以用来做数 ...
- Python3 常用模块2
目录 time 模块 时间戳形式 格式化时间 结构化时间 time.time() time.sleep() datetime 模块 random 模块 hashlib 模块 和 hmac 模块 typ ...
- Python3 常用模块1
目录 os模块 对文件夹操作 对文件进行操作 sys模块 json 和pickle模块 logging模块 日志等级 longging模块的四大组件 自定义配置 os模块 通过os模块我们可以与操作系 ...
- Python3基础(5)常用模块:time、datetime、random、os、sys、shutil、shelve、xml处理、ConfigParser、hashlib、re
---------------个人学习笔记--------------- ----------------本文作者吴疆-------------- ------点击此处链接至博客园原文------ 1 ...
- Python3基础笔记--常用模块
目录: 参考博客:Python 之路 Day5 - 常用模块学习 Py西游攻关之模块 一.time模块 二.random模块 三.os模块 四.sys模块 五.hashlib模块 六.logging模 ...
- day--6_python常用模块
常用模块: time和datetime shutil模块 radom string shelve模块 xml处理 configparser处理 hashlib subprocess logging模块 ...
- python基础之常用模块以及格式化输出
模块简介 模块,用一砣代码实现了某个功能的代码集合. 类似于函数式编程和面向过程编程,函数式编程则完成一个功能,其他代码用来调用即可,提供了代码的重用性和代码间的耦合.而对于一个复杂的功能来,可能需要 ...
随机推荐
- 十个非常实用的MySQL命令
建赟 版主 楼主 前言 今天介绍一些MySQL常用的实用命令,都是一些比较简单的命令.已经知道的朋友,就当是巩固吧,不知道的童鞋,可以好好在自己的机器上,练习下. 0. 显示数据库 命令:s ...
- ie8以下不兼容h5新标签的解决方法
HTML5新添了一些语义化标签,他们能让代码语义化更直观易懂,有利于SEO优化.但是此HTML5新标签在IE6/IE7/IE8上并不能识别,需要进行JavaScript处理. 解决思路就是用js创建h ...
- 威布尔weibull distribution
data = wblrnd(0.5,0.8,100,1); 生成威布尔随机函数,尺寸参数为0.5,形状参数为0.8,生成数列100行,一列: parmhat = wblfit(data) 对data的 ...
- 导入导出sql结构和数据
导入导出sql结构和数据
- python3正则表达式指南
1.正则表达式基础 1.1 简单介绍 正则表达式并不是Python的一部分.正则表达式是用于处理字符串的强大工具,拥有自己独特的语法以及一个独立的处理引擎,效率上可能不如str自带的方法,但功能十分强 ...
- layui弹框文件导入
lr.ajax({ type : "post", data :formFile, url : importUrl, contentType: false,// 且已经声明了属性en ...
- Eclipse中servlet简易模版
package ${enclosing_package}; import java.io.IOException; import javax.servlet.ServletException; imp ...
- 基础数据类型补充 set集合 深浅拷贝
一.基础数据类型补充 1. "拼接字符串".join(可迭代对象) 可迭代对象为列表时,输出列表元素与拼接字符串的拼接 li = ['张三', '李四', '王五', '赵四'] ...
- 出现java.lang.NoClassDefFoundError: org/apache/commons/collections/FastHashMap错误问题解决
首先出现这个问题,你应该是用了 BeanUtils.populate(meter,map); import org.apache.commons.beanutils.BeanUtils;并且导入了co ...
- echars前端处理数据、pyechars后端处理数据
echars -- 后端给数据,前端根据数据做渲染 - echarts:https://www.echartsjs.com/zh/index.htmlhtml文件 <!DOCTYPE html& ...