【转】KAFKA分布式消息系统
Kafka[1]是linkedin用于日志处理的分布式消息队列,linkedin的日志数据容量大,但对可靠性要求不高,其日志数据主要包括用户行为(登录、浏览、点击、分享、喜欢)以及系统运行日志(CPU、内存、磁盘、网络、系统及进程状态)。
当前很多的消息队列服务提供可靠交付保证,并默认是即时消费(不适合离线)。高可靠交付对linkedin的日志不是必须的,故可通过降低可靠性来提高性能,同时通过构建分布式的集群,允许消息在系统中累积,使得kafka同时支持离线和在线日志处理。
注:本文中发布者(publisher)与生产者(producer)可以互换,订阅者(subscriber)与消费者(consumer)可以互换。
Kafka的架构如下图所示:
Kafka存储策略
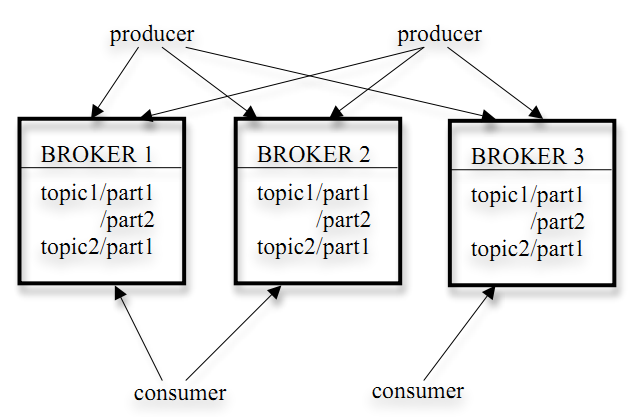
- kafka以topic来进行消息管理,每个topic包含多个part(ition),每个part对应一个逻辑log,有多个segment组成。
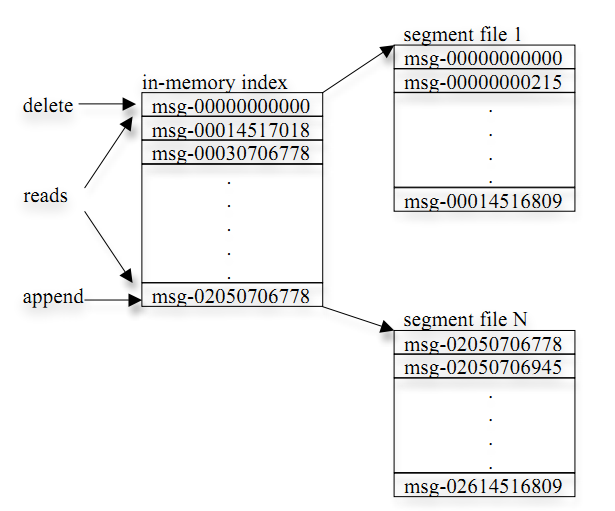
- 每个segment中存储多条消息(见下图),消息id由其逻辑位置决定,即从消息id可直接定位到消息的存储位置,避免id到位置的额外映射。
- 每个part在内存中对应一个index,记录每个segment中的第一条消息偏移。
- 发布者发到某个topic的消息会被均匀的分布到多个part上(随机或根据用户指定的回调函数进行分布),broker收到发布消息往对应part的最后一个segment上添加该消息,当某个segment上的消息条数达到配置值或消息发布时间超过阈值时,segment上的消息会被flush到磁盘,只有flush到磁盘上的消息订阅者才能订阅到,segment达到一定的大小后将不会再往该segment写数据,broker会创建新的segment。
发布与订阅接口
发布消息时,kafka client先构造一条消息,将消息加入到消息集set中(kafka支持批量发布,可以往消息集合中添加多条消息,一次行发布),send消息时,client需指定消息所属的topic。
订阅消息时,kafka client需指定topic以及partition num(每个partition对应一个逻辑日志流,如topic代表某个产品线,partition代表产品线的日志按天切分的结果),client订阅后,就可迭代读取消息,如果没有消息,client会阻塞直到有新的消息发布。consumer可以累积确认接收到的消息,当其确认了某个offset的消息,意味着之前的消息也都已成功接收到,此时broker会更新zookeeper上地offset registry(后面会讲到)。
高效的数据传输
- 发布者每次可发布多条消息(将消息加到一个消息集合中发布), sub每次迭代一条消息。
- 不创建单独的cache,使用系统的page cache。发布者顺序发布,订阅者通常比发布者滞后一点点,直接使用linux的page cache效果也比较后,同时减少了cache管理及垃圾收集的开销。
- 使用sendfile优化网络传输,减少一次内存拷贝。
无状态broker
- Broker没有副本机制,一旦broker宕机,该broker的消息将都不可用。
- Broker不保存订阅者的状态,由订阅者自己保存。
- 无状态导致消息的删除成为难题(可能删除的消息正在被订阅),kafka采用基于时间的SLA(服务水平保证),消息保存一定时间(通常为7天)后会被删除。
- 消息订阅者可以rewind back到任意位置重新进行消费,当订阅者故障时,可以选择最小的offset进行重新读取消费消息。
Consumer group
- 允许consumer group(包含多个consumer,如一个集群同时消费)对一个topic进行消费,不同的consumer group之间独立订阅。
- 为了对减小一个consumer group中不同consumer之间的分布式协调开销,指定partition为最小的并行消费单位,即一个group内的consumer只能消费不同的partition。
Zookeeper 协调控制
1. 管理broker与consumer的动态加入与离开。
2. 触发负载均衡,当broker或consumer加入或离开时会触发负载均衡算法,使得一
个consumer group内的多个consumer的订阅负载平衡。
3. 维护消费关系及每个partion的消费信息。
Zookeeper上的细节:
- 每个broker启动后会在zookeeper上注册一个临时的broker registry,包含broker的ip地址和端口号,所存储的topics和partitions信息。
- 每个consumer启动后会在zookeeper上注册一个临时的consumer registry:包含consumer所属的consumer group以及订阅的topics。
- 每个consumer group关联一个临时的owner registry和一个持久的offset registry。对于被订阅的每个partition包含一个owner registry,内容为订阅这个partition的consumer id;同时包含一个offset registry,内容为上一次订阅的offset。
消息交付保证
- kafka对消息的重复、丢失、错误以及顺序型没有严格的要求。
- kafka提供at-least-once delivery,即当consumer宕机后,有些消息可能会被重复delivery。
- 因每个partition只会被consumer group内的一个consumer消费,故kafka保证每个partition内的消息会被顺序的订阅。
- Kafka为每条消息为每条消息计算CRC校验,用于错误检测,crc校验不通过的消息会直接被丢弃掉。
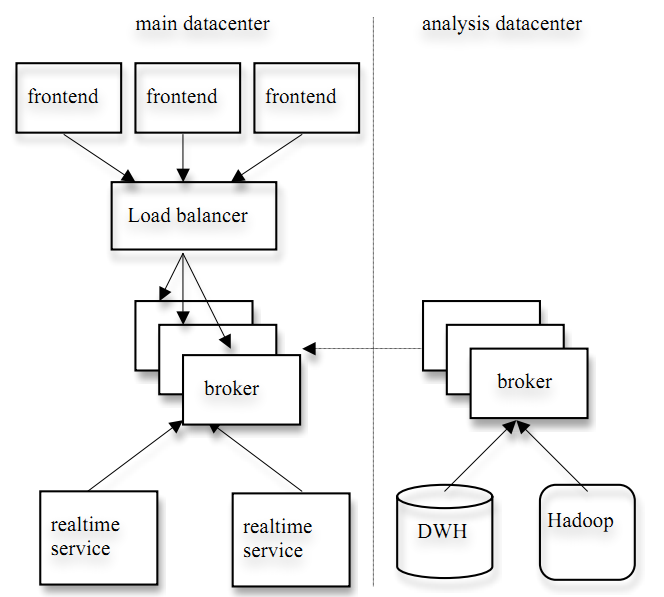
Linkedin的应用环境
如下图,左边的应用于日志数据的在线实时处理,右边的应用于日志数据的离线分析(现将日志pull至hadoop或DWH中)。
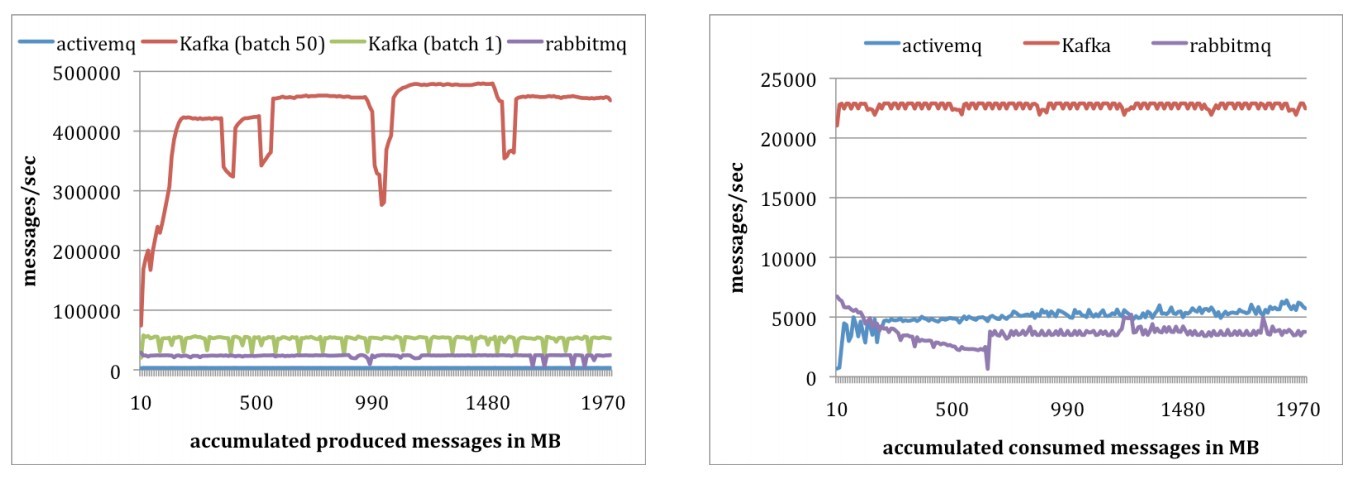
Kafka的性能
测试环境: 2 Linux machines, each with 8 2GHz cores, 16GB of memory, 6 disks with RAID 10. The two machines are connected with a 1Gb network link. One of the machines was used as the broker and the other machine was used as the producer or the consumer.
测试评价(by me):(1)环境过于简单,不足以说明问题。(2)对于producer持续的波动没有进行分析。(3)只有两台机器zookeeper都省了??
测试结果:如下图,完胜其他的message queue,单条消息发送(每条200bytes),能到50000messages/sec,50条batch方式发送,平均为400000messages/sec.
Kafka未来研究方向
1. 数据压缩(节省网络带宽及存储空间)
2. Broker多副本
3. 流式处理应用
原文链接:http://blog.chinaunix.net/uid-20196318-id-2420884.html
【转】KAFKA分布式消息系统的更多相关文章
- Kafka——分布式消息系统
Kafka——分布式消息系统 架构 Apache Kafka是2010年12月份开源的项目,采用scala语言编写,使用了多种效率优化机制,整体架构比较新颖(push/pull),更适合异构集群. 设 ...
- KAFKA分布式消息系统[转]
KAFKA分布式消息系统 转自:http://blog.chinaunix.net/uid-20196318-id-2420884.html Kafka[1]是linkedin用于日志处理的分布式消 ...
- 在Centos 7上安装配置 Apche Kafka 分布式消息系统集群
Apache Kafka是一种颇受欢迎的分布式消息代理系统,旨在有效地处理大量的实时数据.Kafka集群不仅具有高度可扩展性和容错性,而且与其他消息代理(如ActiveMQ和RabbitMQ)相比,还 ...
- KAFKA分布式消息系统
2015-01-05 大数据平台 Hadoop大数据平台 基本概念 kafka的工作方式和其他MQ基本相同,只是在一些名词命名上有些不同.为了更好的讨论,这里对这些名词做简单解释.通过这些解释应该可以 ...
- [转载] KAFKA分布式消息系统
转载自http://blog.chinaunix.net/uid-20196318-id-2420884.html Kafka[1]是linkedin用于日志处理的分布式消息队列,linkedin的日 ...
- Kafka 分布式消息系统详解
实际上kafka对机器的需求与Hadoop的类似. 原来,对于Linkin这样的互联网企业来说,用户和网站上产生的数据有三种: 需要实时响应的交易数据,用户提交一个表单,输入一段内容,这种数据最后是存 ...
- 分布式消息系统Kafka初步
终于可以写kafka的文章了,Mina的相关文章我已经做了索引,在我的博客中置顶了,大家可以方便的找到.从这一篇开始分布式消息系统的入门. 在我们大量使用分布式数据库.分布式计算集群的时候,是否会遇到 ...
- 分布式消息系统kafka
kafka:一个分布式消息系统 1.背景 最近因为工作需要,调研了追求高吞吐的轻量级消息系统Kafka,打算替换掉线上运行的ActiveMQ,主要是因为明年的预算日流量有十亿,而ActiveMQ的分布 ...
- 分布式消息系统Kafka初步(一) (赞)
终于可以写kafka的文章了,Mina的相关文章我已经做了索引,在我的博客中置顶了,大家可以方便的找到.从这一篇开始分布式消息系统的入门. 在我们大量使用分布式数据库.分布式计算集群的时候,是否会遇到 ...
随机推荐
- python面向对象之三大特性
继承 先看个简单的例子了解一下继承. class Animal: # 父类 def __init__(self, name, age, department): self.name = name se ...
- BoundsChecker下载
首先,单独的BoundsChecker已经没了,被收购了,整合进了DevPartner 其次,DevPartner是收费软件,属于Borland的.官方地址:http://www.borland.co ...
- Ajax与PHP通信
以下是HTML的Js代码 $data = { va:$('#num').text() }; $.ajax({ type: 'POST', url: "A.php", data: $ ...
- SpringMVC 非注解配置
web.xml配置: <servlet> <servlet-name>springmvc</servlet-name> <servlet-class>o ...
- linux 阻塞 open 作为对 EBUSY 的替代
当设备不可存取, 返回一个错误常常是最合理的方法, 但是有些情况用户可能更愿意等待 设备. 例如, 如果一个数据通讯通道既用于规律地预期地传送报告(使用 crontab), 也用于根据 用户的需要偶尔 ...
- Linux内存页大小
当使用内存时, 记住一个内存页是 PAGE_SIZE 字节, 不是 4KB. 假定页大小是 4KB 并且 硬编码这个值是一个 PC 程序员常见的错误, 相反, 被支持的平台显示页大小从 4 KB 到 ...
- Vue2.0 Vue.set的使用
原文链接: https://blog.csdn.net/qq_30455841/article/details/78666571
- spring的69个问题
1.什么是Spring? Spring是一个开源的Java EE开发框架.Spring框架的核心功能可以应用在任何Java应用程序中,但对Java EE平台上的Web应用程序有更好的扩展性.Sprin ...
- [Linux] 使用awk比较两个文件的内容
当需要比较A , B两个文件 , A文件中存在 , 并且把也在B文件中存在的行去除掉 , 可以使用这个awk的用法来 awk '{if(ARGIND==1) {val[$0]}else{if($0 ...
- IDE介绍之——CLion
CLion是JetBrains公司旗下发布的一款跨平台C/C++IDE开发工具. 使用CLion上最好要会手写CMake.要先安装编译器套件(一般安装MinGW就行). 对C++标准的支持:基本上Cl ...