solr服务中集成IKAnalyzer中文分词器、集成dataimportHandler插件
昨天已经在Tomcat容器中成功的部署了solr全文检索引擎系统的服务;今天来分享一下solr服务在海量数据的网站中是如何实现数据的检索。
在solr服务中集成IKAnalyzer中文分词器的步骤:
1、下载IKAnalyzer分词器的压缩包并解压;

2、将IKAnalyzer压缩包中的jar包复制到Tomcat容器中已经部署的solr项目中的WEB-INF/lib目录下;

3、在Tomcat容器的solr项目中的WEB-INF/目录创建一个classes目录(默认该目录是不存在的,需手动创建),并将分词器压缩包中的配置文件、自定义词典、通用词典三个文件拷贝到classes目录中;
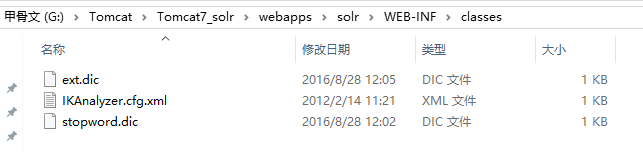
4、找到solr的家目录,即solrHome目录,修改solrHome/collection1/conf/schema.xml文件中定义IK域的类型、定义自定义域配置内容;
<!-- IKAnalyzer-->
<fieldType name="text_ik" class="solr.TextField">
<analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType> <!--IKAnalyzer Field-->
<field name="content_ik" type="text_ik" indexed="true" stored="true" />
5、重新启动Tomcat容器,检验是否配置成功,如果出现以下界面中的内容,则集成成功,可以看到我们刚才在solrHome的配置文件中配置的自定义域和IK域的类型。

使用dataimportHandler插件批量导入数据,在solr服务中集成dataimportHandler插件的步骤:
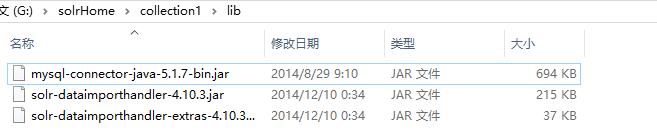
1、找到solrHome/collection1目录,创建一个lib目录,将插件所依赖的jar包和数据库驱动包拷贝到lib目录下(dataimportHandler插件依赖的jar包可以在下载好的solr压缩包中找到);
插件依赖的jar包在dist目录下:

2、找到solrHome/collection1/conf/solrconfig.xml文件,添加如下配置内容:
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<str name="config">data-config.xml</str>
</lst>
</requestHandler>
3、根据创建的数据表在solrHome/collection1/conf/schema.xml配置文件中配置业务域(温馨提示:业务域根据数据表的字段名称来配置);
<!--product-->
<field name="product_name" type="text_ik" indexed="true" stored="true"/>
<field name="product_price" type="float" indexed="true" stored="true"/>
<field name="product_description" type="text_ik" indexed="true" stored="false" />
<field name="product_picture" type="string" indexed="false" stored="true" />
<field name="product_catalog_name" type="string" indexed="true" stored="true" /> <field name="product_keywords" type="text_ik" indexed="true" stored="false" multiValued="true"/>
<copyField source="product_name" dest="product_keywords"/>
<copyField source="product_description" dest="product_keywords"/>
4、需要创建一个文件名称为data-config.xml的配置文件,并且拷贝到solrHome/collection1/conf目录下;data-config.xml文件中的配置内容如下(温馨提示:根据自己的需求的来添加配置内容,如数据库连接的参数信息,数据库中表字段的名称等):
<?xml version="1.0" encoding="UTF-8" ?>
<dataConfig>
<dataSource type="JdbcDataSource"
driver="com.mysql.jdbc.Driver"
url="jdbc:mysql://localhost:3306/solr"
user="root"
password="123"/> <document>
<!-- column代表数据表中的字段名称,name代表配置文件中的业务域的name属性值名称 -->
<entity name="product" query="SELECT pid,name,catalog_name,price,description,picture FROM products ">
<field column="pid" name="id"/>
<field column="name" name="product_name"/>
<field column="catalog_name" name="product_catalog_name"/>
<field column="price" name="product_price"/>
<field column="description" name="product_description"/>
<field column="picture" name="product_picture"/>
</entity>
</document>
</dataConfig>
5、重启Tomcat容器,检验插件是否集成成功,如果集成成功,则会看到如下界面,看到成功界面后,就可以导入指定数据表中的数据,导入操作在下图中已表明:

[后续会更新京东站内搜索-solr架构案例,有需要的朋友可以继续关注!!!]
solr服务中集成IKAnalyzer中文分词器、集成dataimportHandler插件的更多相关文章
- Solr学习笔记之2、集成IK中文分词器
Solr学习笔记之2.集成IK中文分词器 一.下载IK中文分词器 IK中文分词器 此文IK版本:IK Analyer 2012-FF hotfix 1 完整分发包 二.在Solr中集成IK中文分词器 ...
- Lucene系列四:Lucene提供的分词器、IKAnalyze中文分词器集成、扩展 IKAnalyzer的停用词和新词
一.Lucene提供的分词器StandardAnalyzer和SmartChineseAnalyzer 1.新建一个测试Lucene提供的分词器的maven项目LuceneAnalyzer 2. 在p ...
- Solr的学习使用之(三)IKAnalyzer中文分词器的配置
1.为什么要配置? 1.我们知道要使用Solr进行搜索,肯定要对词语进行分词,但是由于Solr的analysis包并没有带支持中文的包或者对中文的分词效果不好,需要自己添加中文分词器:目前呼声较高的是 ...
- 2.IKAnalyzer 中文分词器配置和使用
一.配置 IKAnalyzer 中文分词器配置,简单,超简单. IKAnalyzer 中文分词器下载,注意版本问题,貌似出现向下不兼容的问题,solr的客户端界面Logging会提示错误. 给出我配置 ...
- 我与solr(六)--solr6.0配置中文分词器IK Analyzer
转自:http://blog.csdn.net/linzhiqiang0316/article/details/51554217,表示感谢. 由于前面没有设置分词器,以至于查询的结果出入比较大,并且无 ...
- 【solr】solr5.0整合中文分词器
1.solr自带的分词器远远满足不了中文分词的需求,经查使用最多的分词器是solr是mmseg4j分词器,具体整合大家可以参考 https://github.com/zhuomingliang/mms ...
- Solr集成IK中文分词器
1.将IKAnalyzer-2012-4x.jar拷贝到example\solr-webapp\webapp\WEB-INF\lib下: 2.在schema.xml文件中添加fieldType: &l ...
- Solr 安装与集成IK中文分词器
创建wangchuanfu core 1. 在example目录下创建wangchuanfu-solr文件夹: 2. 将./solr下的solr.xml拷贝到wangchuanfu-solr目录下 ...
- solr 7.7.0配置中文分词器的数据类型
<dynamicField name="*_is" type="pints" indexed="true" stored=" ...
随机推荐
- 菜鸟Python学习笔记第一天:关于一些函数库的使用
2017年1月3日 星期二 大一学习一门新的计算机语言真的很难,有时候连函数拼写出错查错都能查半天,没办法,谁让我英语太渣. 关于计算机语言的学习我想还是从C语言学习开始为好,Python有很多语言的 ...
- 几个有趣的WEB设备API 前端提高B格必备(一)——电池状态&震动api
受到同事启发,突然发现了几个有趣又实用的web api,没想到前端还有这么多有趣的东西可以玩~~简直过分. 1.电池状态API navigator.getBattery():这个api返回的是一个pr ...
- bzoj4724--数论
题目大意: B进制数,每个数字i(i=0,1,...,B-1)有a[i]个.你要用这些数字组成一个最大的B进制数X(不能有前导零,不需要 用完所有数字),使得X是B-1的倍数.q次询问,每次询问X在B ...
- CSS3新特性应用之结构与布局
一.自适应内部元素 利用width的新特性min-content实现 width新特性值介绍: fill-available,自动填充盒子模型中剩余的宽度,包含margin.padding.borde ...
- Oracle:一个用户操作多个表空间中表的问题(转)
原文地址:http://blog.csdn.net/shmiloy001/article/details/6287317 首先,授权给指定用户. 一个用户的默认表空间只能有一个,但是你可以试下用下面的 ...
- mysql-5.6.34 Installation from Source code
Took me a while to suffer from the first successful souce code installation of mysql-5.6.34. Just pu ...
- Linux下编译安装Vim8.0
什么是Vim? Vim 是经典的 UNIX 编辑器 Vi 的深度改良版本.它增加了许多功能,包括:多级撤销.格式高亮.命令行历史.在线帮助.拼写检查.文件名补完.块操作.脚本支持,等等.除了字符界面版 ...
- Linux设备管理(二)_从cdev_add说起
我在Linux字符设备驱动框架一文中已经简单的介绍了字符设备驱动的基本的编程框架,这里我们来探讨一下Linux内核(以4.8.5内核为例)是怎么管理字符设备的,即当我们获得了设备号,分配了cdev结构 ...
- .NET跨平台之旅:数据库连接字符串写法引发的问题
最近在一个ASP.NET Core站点中遇到一个奇怪问题.当用dotnet run命令启动站点后,开始的一段时间请求执行速度超慢,有时要超过20秒,有时甚至超过1分钟,日志中会记录这样的错误: Sys ...
- fmt标签把时间戳格式化日期
jsp页面标签格式化日期 <%@taglib uri="http://java.sun.com/jsp/jstl/fmt" prefix="f" %> ...