iceoryx源码阅读(三)——共享内存通信(一)
0 导引
iceoryx源码阅读(四)——共享内存通信(二)
iceoryx源码阅读(五)——共享内存通信(三)
iceoryx源码阅读(六)——共享内存创建
iceoryx源码阅读(七)——服务发现机制
1 整体通信结构
订阅-发布结构实现一对多的通信模式,消息发布者可以将消息推送到多个订阅者。基于共享内存的订阅-发布通信结构如下图所示:
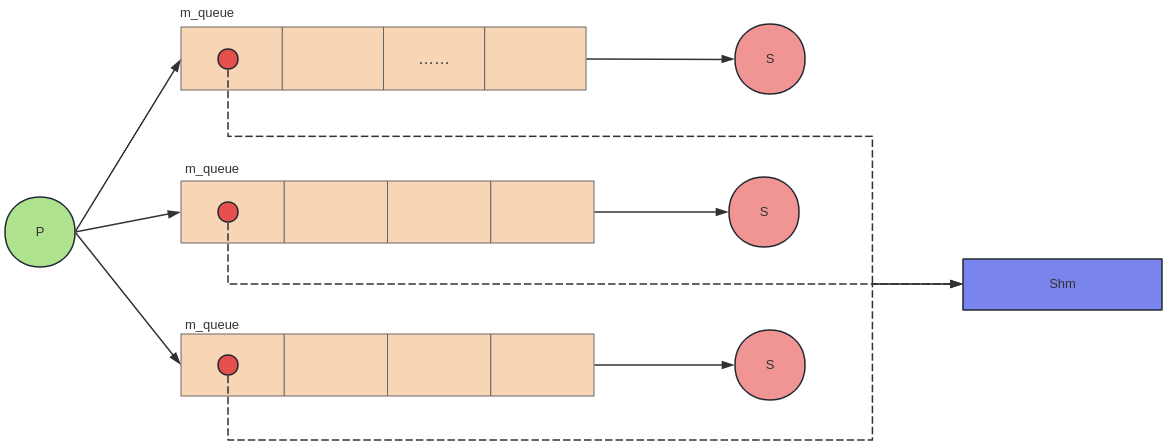
每一对订阅者和发布者之间通过队列联系,队列元素为发送数据的描述。发送者往队列中推入描述,订阅者取出描述,据此从共享内存获取真正的消息数据。队列中为什么不直接存放消息数据本身呢?原因一则是消息的长度是不确定的,二则是一对多通信结果下,直接将消息存放在队列中更浪费空间。
2 RelativePointer
上节说到队列存放消息存放位置的描述,可以是地址吗?
2.1 原理
使用共享内存内存前,需要映射到进程的虚拟地址空间,如下图所示:
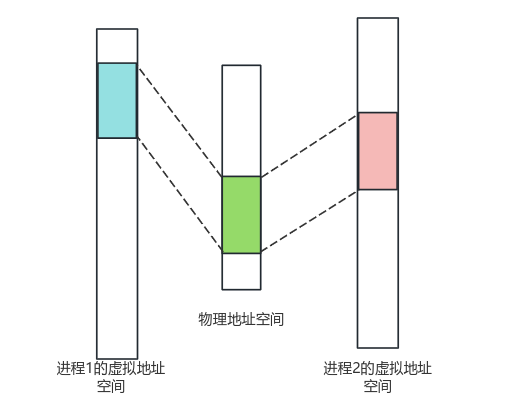
不同进程映射的区域不同,iceoryx使用数字唯一标识共享内存。实际上,iceoryx每个应用进程维护一张注册表,保存各个共享内存的起止地址,这里的数字就是共享内存在注册表中的索引。为了定位某个Chunk,还需要该Chunk相对共享内存首地址的偏移量。共享内存索引和偏移就定义了RelativePointer——用于定位共享内存的指定位置,相关代码如下所示:
template <typename T>
class RelativePointer final
{
public:
using ptr_t = T*;
using offset_t = std::uintptr_t;
explicit RelativePointer(ptr_t const ptr) noexcept;
T* computeRawPtr() const noexcept;
private:
segment_id_underlying_t m_id{NULL_POINTER_ID};
offset_t m_offset{NULL_POINTER_OFFSET};
};
上述代码中,除了共享内存索引和偏移外,还加了两个函数:
- 构造函数,通过普通指针构造
RelativePointer对象。 - 根据
RelativePointer获取其所代表的普通指针。
2.2 PointerRepository
上节我们引入了注册表的概念,了解了其作用,本节具体看看其实现。
constexpr uint64_t MAX_POINTER_REPO_CAPACITY{10000U};
template <typename id_t, typename ptr_t, uint64_t CAPACITY = MAX_POINTER_REPO_CAPACITY>
class PointerRepository final
{
private:
struct Info
{
ptr_t basePtr{nullptr};
ptr_t endPtr{nullptr};
};
public:
bool registerPtrWithId(const id_t id, const ptr_t ptr, const uint64_t size) noexcept;
cxx::optional<id_t> registerPtr(const ptr_t ptr, const uint64_t size = 0U) noexcept;
private:
iox::cxx::vector<Info, CAPACITY> m_info;
uint64_t m_maxRegistered{0U};
};
m_info就是注册表,元素类型为Info,存放共享内存的起始地址和结束地址。这里,我们贴了两个注册指针的函数——registerPtrWithId和registerPtr——分别用于打开共享内存和创建共享内存时调用。
2.3 构造函数
构造函数根据普通指针构造相对指针实例,其代码实现如下:
职责:
RelativePointer实例的构造。
入参:
ptr:普通指针。
template <typename T>
inline RelativePointer<T>::RelativePointer(ptr_t const ptr) noexcept
: RelativePointer([this, ptr]() noexcept -> RelativePointer {
const segment_id_t id{this->searchId(ptr)};
const offset_t offset{this->getOffset(id, ptr)};
return RelativePointer{offset, id};
}())
{
}
template <typename T>
inline segment_id_underlying_t RelativePointer<T>::searchId(ptr_t const ptr) noexcept
{
if (ptr == nullptr)
{
return NULL_POINTER_ID;
}
return getRepository().searchId(ptr);
}
template <typename id_t, typename ptr_t, uint64_t CAPACITY>
inline id_t PointerRepository<id_t, ptr_t, CAPACITY>::searchId(const ptr_t ptr) const noexcept
{
for (id_t id{1U}; id <= m_maxRegistered; ++id)
{
if ((ptr >= m_info[id].basePtr) && (ptr <= m_info[id].endPtr))
{
return id;
}
}
return RAW_POINTER_BEHAVIOUR_ID;
}
template <typename T>
inline typename RelativePointer<T>::offset_t RelativePointer<T>::getOffset(const segment_id_t id,
ptr_t const ptr) noexcept
{
if (static_cast<segment_id_underlying_t>(id) == NULL_POINTER_ID)
{
return NULL_POINTER_OFFSET;
}
const auto* const basePtr = getBasePtr(id);
return reinterpret_cast<offset_t>(ptr) - reinterpret_cast<offset_t>(basePtr);
}
template <typename T>
inline T* RelativePointer<T>::getBasePtr(const segment_id_t id) noexcept
{
return static_cast<ptr_t>(getRepository().getBasePtr(static_cast<segment_id_underlying_t>(id)));
}
template <typename id_t, typename ptr_t, uint64_t CAPACITY>
inline ptr_t PointerRepository<id_t, ptr_t, CAPACITY>::getBasePtr(const id_t id) const noexcept
{
if ((id <= MAX_ID) && (id >= MIN_ID))
{
return m_info[id].basePtr;
}
return nullptr;
}
逐段代码分析:
LINE 01 ~ LINE 09: 构造函数,调用成员函数
searchId和getOffset计算该指针在注册表中的索引id和偏移,以此初始化两个成员。LINE 11 ~ LINE 33: 这部分就是遍历注册表中所有共享内存,找到包含给定地址的共享内存区域的,返回其id。
LINE 35 ~ LINE 62: 从注册表中找出指定id共享内存首地址,入参指针减去首地址,计算得到偏移。
2.4 get函数
职责:
获取RelativePointer实例对应的普通指针。
返回:
普通指针。
template <typename T>
inline T* RelativePointer<T>::get() const noexcept
{
return static_cast<ptr_t>(computeRawPtr());
}
template <typename T>
inline T* RelativePointer<T>::computeRawPtr() const noexcept
{
return getPtr(segment_id_t{m_id}, m_offset);
}
template <typename T>
inline T* RelativePointer<T>::getPtr(const segment_id_t id, const offset_t offset) noexcept
{
if (offset == NULL_POINTER_OFFSET)
{
return nullptr;
}
const auto* const basePtr = getBasePtr(id);
return reinterpret_cast<ptr_t>(offset + reinterpret_cast<offset_t>(basePtr));
}
整体代码分析:
上面代码逻辑和2.3节类似,通过id从注册表中获取共享内存首地址,加上偏移量得到普通指针。
3 ShmSafeUnmanagedChunk
上一篇文章中,我们介绍了SharedChunk,用于管理共享内存。本节将介绍ShmSafeUnmanagedChunk,用于基于共享内存的通信。可以认为是从两个角度描述Chunk。
3.1 队列数据
第1节中的队列中存放的描述数据结构就是ShmSafeUnmanagedChunk,具体代码(去除和本节无关的代码)如下:
struct ChunkQueueData : public LockingPolicy
{
cxx::VariantQueue<mepoo::ShmSafeUnmanagedChunk, MAX_CAPACITY> m_queue;
};
3.2 RelativePointerData
ShmSafeUnmanagedChunk只有唯一的成员变量m_chunkManagement,其类型为RelativePointerData:
class ShmSafeUnmanagedChunk
{
private:
memory::RelativePointerData m_chunkManagement;
};
RelativePointerData的成员就是一个整数,如下:
class RelativePointerData
{
private:
uint64_t m_idAndOffset{LOGICAL_NULLPTR};
};
但是第2节我们知道,描述消息数据在共享内存中的位置,我们需要注册表中的索引id和偏移offset,一个整数怎么够呢?实际上,这个整数按位分成两部分,前48位表示offset,后16位表示id,如下图所示:

据此,我们来看求取id和offset的实现:
using identifier_t = uint16_t;
static constexpr uint64_t ID_BIT_SIZE{16U};
static constexpr identifier_t ID_RANGE{std::numeric_limits<identifier_t>::max()};
static constexpr offset_t OFFSET_RANGE{(1ULL << 48U) - 1U};
RelativePointerData::identifier_t RelativePointerData::id() const noexcept
{
return static_cast<identifier_t>(m_idAndOffset & ID_RANGE);
}
RelativePointerData::offset_t RelativePointerData::offset() const noexcept
{
return (m_idAndOffset >> ID_BIT_SIZE) & OFFSET_RANGE;
}
都是一些位运算,其中ID_RANGE和OFFSET_RANGE分别为后16为和48位为1的数字,取名为ID_MASK和OFFSET_MASK(掩码)更合适。
3.3 构造函数
发送数据的核心就是将SharedChunk转化为ShmSafeUnmanagedChunk,推入队列容器中。这就是ShmSafeUnmanagedChunk的构造函数的职责。
职责:
使用SharedChunk实例构造ShmSafeUnmanagedChunk实例。
入参:
ShmSafeUnmanagedChunk::ShmSafeUnmanagedChunk(mepoo::SharedChunk chunk) noexcept
{
if (chunk)
{
memory::RelativePointer<mepoo::ChunkManagement> ptr{chunk.release()};
auto id = ptr.getId();
auto offset = ptr.getOffset();
m_chunkManagement =
memory::RelativePointerData(static_cast<memory::RelativePointerData::identifier_t>(id), offset);
}
}
整体代码分析:
上述代码就是使用第2节中介绍的构造函数,根据普通指针构造RelativePointer,然后得到id和offset,以此构造RelativePointerData:
static constexpr identifier_t MAX_VALID_ID{ID_RANGE - 1U};
static constexpr offset_t MAX_VALID_OFFSET{OFFSET_RANGE - 1U};
constexpr RelativePointerData::RelativePointerData(identifier_t id, offset_t offset) noexcept
: m_idAndOffset(static_cast<uint64_t>(id) | (offset << ID_BIT_SIZE))
{
if ((id > MAX_VALID_ID) || (offset > MAX_VALID_OFFSET))
{
m_idAndOffset = LOGICAL_NULLPTR;
}
}
结合3.2节对RelativePointerData的介绍,上述构造函数是显然的。
3.4 releaseToSharedChunk
接收端需要将ShmSafeUnmanagedChunk转为SharedChunk,这就是releaseToSharedChunk的职责。
职责:
通过ShmSafeUnmanagedChunk构造SharedChunk实例。
返回:
SharedChunk实例。
SharedChunk ShmSafeUnmanagedChunk::releaseToSharedChunk() noexcept
{
if (m_chunkManagement.isLogicalNullptr())
{
return SharedChunk();
}
auto chunkMgmt = memory::RelativePointer<mepoo::ChunkManagement>(m_chunkManagement.offset(),
memory::segment_id_t{m_chunkManagement.id()});
m_chunkManagement.reset();
return SharedChunk(chunkMgmt.get());
}
根据id和offset构造RelativePointer实例,然后通过2.4节介绍的get方法获得指向ChunkManagement指针,据此构造SharedChunk实例(SharedChunk唯一的成员数据就是ChunkManagement指针,见:SharedChunk的数据成员)。
4 小结
本文介绍基于共享内存通信的主要数据结构,下文我们将介绍数据发送函数和接收函数的实现。
iceoryx源码阅读(三)——共享内存通信(一)的更多相关文章
- 26 BasicUsageEnvironment基本使用环境——Live555源码阅读(三)UsageEnvironment
26 BasicUsageEnvironment基本使用环境--Live555源码阅读(三)UsageEnvironment 26 BasicUsageEnvironment基本使用环境--Live5 ...
- 25 BasicUsageEnvironment0基本使用环境基类——Live555源码阅读(三)UsageEnvironment
25 BasicUsageEnvironment0基本使用环境基类——Live555源码阅读(三)UsageEnvironment 25 BasicUsageEnvironment0基本使用环境基类— ...
- 24 UsageEnvironment使用环境抽象基类——Live555源码阅读(三)UsageEnvironment
24 UsageEnvironment使用环境抽象基类——Live555源码阅读(三)UsageEnvironment 24 UsageEnvironment使用环境抽象基类——Live555源码阅读 ...
- SparkSQL(源码阅读三)
额,没忍住,想完全了解sparksql,毕竟一直在用嘛,想一次性搞清楚它,所以今天再多看点好了~ 曾几何时,有一个叫做shark的东西,它改了hive的源码...突然有一天,spark Sql突然出现 ...
- Qt源码阅读(三) 对象树管理
对象树管理 个人经验总结,如有错误或遗漏,欢迎各位大佬指正 @ 目录 对象树管理 设置父对象的作用 设置父对象(setParent) 完整源码 片段分析 对象的删除 夹带私货时间 设置父对象的作用 众 ...
- CoreCLR源码探索(三) GC内存分配器的内部实现
在前一篇中我讲解了new是怎么工作的, 但是却一笔跳过了内存分配相关的部分. 在这一篇中我将详细讲解GC内存分配器的内部实现. 在看这一篇之前请必须先看完微软BOTR文档中的"Garbage ...
- SpringMVC源码阅读(三)
先理一下Bean的初始化路线 org.springframework.beans.factory.support.AbstractBeanDefinitionReader public int loa ...
- JDK源码阅读(三) Collection<T>接口,Iterable<T>接口
package java.util; public interface Collection<E> extends Iterable<E> { //返回该集合中元素的数量 in ...
- 23 使用环境 UsageEnvironment——Live555源码阅读
23 使用环境 UsageEnvironment——Live555源码阅读(三)UsageEnvironment 23 使用环境 UsageEnvironment——Live555源码阅读(三)Usa ...
- Struts2源码阅读(一)_Struts2框架流程概述
1. Struts2架构图 当外部的httpservletrequest到来时 ,初始到了servlet容器(所以虽然Servlet和Action是解耦合的,但是Action依旧能够通过httpse ...
随机推荐
- #双指针#洛谷 7521 [省选联考 2021 B 卷] 取模
题目传送门 分析 将 \(a\) 排序后从大到小枚举 \(a_k\),注意枚举的时候重复的只考虑一次,那么可以将其它数按照模 \(a_k\) 后排序, 答案只可能来自最大值与次大值之和取模或者之和最接 ...
- #区间dp#CF1114D Flood Fill
题目 有一个长度为\(n\)的颜色序列,在游戏前选择一个固定的位置, 若当前轮该位置的颜色为\(x\),那么可以将所有颜色为\(x\)的连通块改为任意颜色, 问最少进行多少轮使得区间\([1,n]\) ...
- 密码学系列之:IDEA
密码学系列之:IDEA 目录 简介 IDEA简介 IDEA原理 IDEA子密钥的生成 简介 IDEA的全称是International Data Encryption Algorithm,也叫做国际加 ...
- Pandas统计计算
基本的统计方法 Method Description count Number of non-NA values describe Compute set of summary statistics ...
- Python - PEP572: 海象运算符
海象运算符 PEP572 的标题是「Assignment Expressions」,也就是「赋值表达式」,也叫做「命名表达式」 不过它现在被广泛的别名是「海象运算符」(The Walrus Opera ...
- kratos http原理
概念 kratos 为了使http协议的逻辑代码和grpc的逻辑代码使用同一份,选择了基于protobuf的IDL文件使用proto插件生成辅助代码的方式. protoc http插件的地址为:htt ...
- 【Oracle】获取字符串中特定字符在字符串中出现的次数
[Oracle]获取字符串中特定字符在字符串中出现的次数 使用regexp_count函数 例子: select regexp_count('A,B,D,E;Q;F;GQWEQWE:qwe',';') ...
- 力扣566(java)-重塑矩阵(简单)
题目: 在 MATLAB 中,有一个非常有用的函数 reshape ,它可以将一个 m x n 矩阵重塑为另一个大小不同(r x c)的新矩阵,但保留其原始数据. 给你一个由二维数组 mat 表示的 ...
- 牛客网-SQL专项训练6
①要将employee 的表名更改为 employee_info,下面MySQL语句正确的是(A) 解析: RENAME用于表的重命名:RENAME <NAME>(修改表名或索引名) 或 ...
- 力扣670(java)-最大交换(中等)
题目: 给定一个非负整数,你至多可以交换一次数字中的任意两位.返回你能得到的最大值. 示例 1 : 输入: 2736输出: 7236解释: 交换数字2和数字7.示例 2 : 输入: 9973输出: 9 ...