火山引擎DataLeap的数据血缘用例与设计概述
更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群
字节数据链路介绍
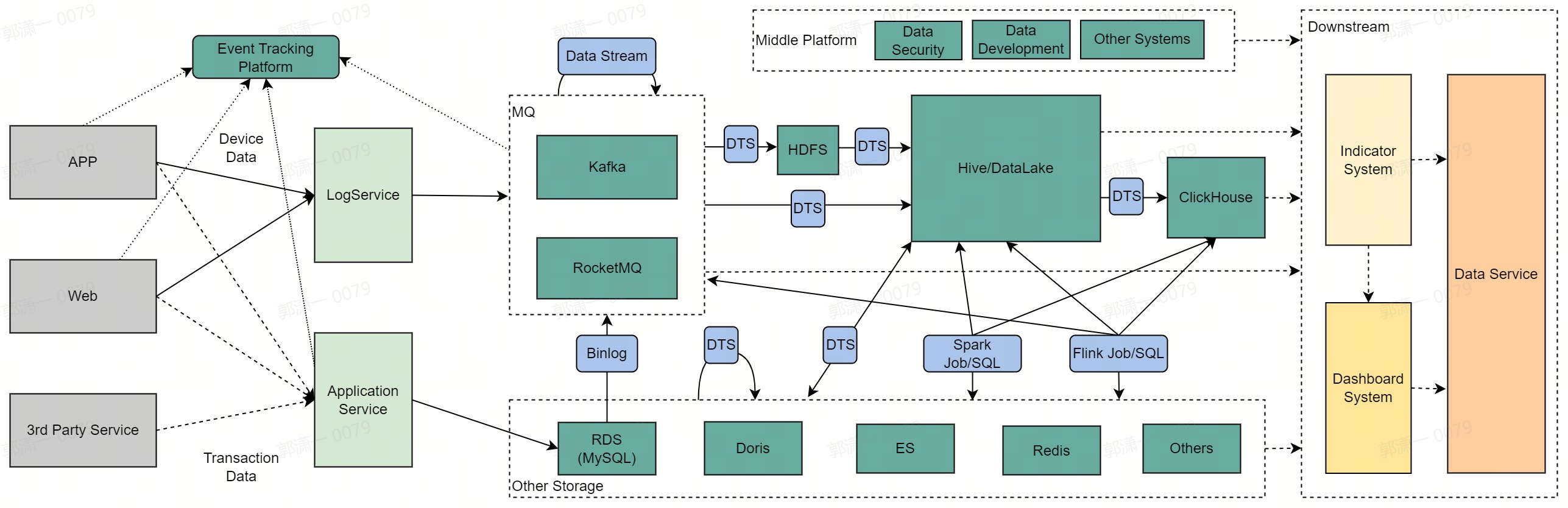
- 字节的数据的来源分为两种:
- 端数据:APP和Web端通过埋点SDK发送的,经过LogService,最终落入MQ
- 业务数据:APP,Web和第三方服务所进行的业务操作,通过各种应用的服务,最终落入RDS,RDS中的数据,经过Binlog的方式,汇入MQ
- MQ中的数据,在MQ之间有分流的过程,做转换格式,流量拆分等
- 离线数仓的核心是Hive,数据通过各种手段最终汇入其中,使用主流的HiveSQL或SparkJob做业务处理,流入下游Clickhouse等其他存储
- 实时数仓的核心是MQ,使用主流的FlinkSQL或通用FlinkJob做处理,期间与各种存储做SideJoin丰富数据,最终写入各种存储
- 典型的数据出口有三类:
- 指标系统:业务属性强烈的一组数据,比如“抖音日活”
- 报表系统:以可视化的形式,各种维度展示加工前或加工后的数据
- 数据服务:以API调用的形式进一步加工和获取数据
血缘的应用场景
|
领域
|
场景举例
|
场景描述
|
场景特点
|
|
数据资产
|
引用热度计算
|
资产被频繁消费和广泛引用,是对自身权威性的有利佐证,类似网页引用中的PageRank值,我们根据资产的下游血缘情况,定义了资产定义引用热度值。热度高的资产,更值得被信任。
|
离线方式批量消费血缘数据;
覆盖范围越广越好;
少量错误不会造成恶劣影响
|
|
理解数据上下文
|
在找数据时,通过查看一份数据资产的血缘,来更多的了解它的“前世今生”,可以更好的判定当前资产是不是自己需要的,或者是不是值得信赖的。就像了解一个人,可以从他周围的朋友中得到很多信息一样,是对这个人“生平”很好的补充。
|
实时方式获取血缘数据;
覆盖范围越广越好;
少量错误不会造成恶劣影响
|
|
|
数据开发
|
影响分析
|
当处于血缘上游的研发同学修改任务前,通过查看自己的下游,通知对应资产或任务的负责人,进行相应的修改,否则会造成严重的生产事故
|
实时方式获取血缘数据;
覆盖范围越广越好;
血缘错误可能会造成严重事故
|
|
归因分析
|
当某个任务出现问题时,通过查看血缘上游的任务或资产,排查出造成问题的根因是什么
|
实时方式获取血缘数据;
覆盖范围越广越好;
血缘错误会影响效率
|
|
|
数据治理
|
链路状态追踪
|
事先挑选已知的核心任务,通过血缘关系,自动化的梳理出其所在的核心链路,并做重点的治理与保障
|
离线方式批量消费血缘数据;
覆盖核心链路;
血缘错误可能会造成严重事故
|
|
数仓治理
|
数仓规范化治理,包括但不限于:数仓分层中不合理的逆向引用;数仓分层不合理;冗余的表与链路等
|
离线方式批量消费血缘数据;
覆盖离线和实时数仓;
少量错误不会造成恶劣影响
|
|
|
数据安全
|
安全合规检查
|
资产本身具有安全等级,资产的安全等级不应该低于上游资产的安全等级,否则会有权限泄露风险。基于血缘,通过扫描高安全等级资产的下游,来排除安全合规风险
|
离线方式批量消费血缘数据;
覆盖离线和实时数仓;
错误可能会造成安全风险
|
|
标签传播
|
首先根据规则自动识别(或人工)部分资产的安全标签,基于血缘,将标签自动传播到下游更广泛的资产
|
离线方式批量消费血缘数据;
覆盖离线和实时数仓;
少量不准确不会造成恶劣影响
|
数据血缘系统的整体设计
概览
- 可扩展性:在字节,业务复杂而庞大,整条数据链路中,使用到的各种存储有几十种,细分的任务类型也是几十种,血缘系统需要可以灵活的支持各种存储和任务类型
- 开放的集成方式:消费血缘时,有实时查询的场景,也有离线消费的场景,还有可能下游系统会基于当前数据做扩展

- 任务接入:以某种方式,从任务管理系统中获取任务信息
- 血缘解析:通过解析任务中的信息,获取到血缘数据
- 数据导出:负责将血缘数据存储到Data Catalog系统中,并供下游系统消费
任务接入
- 提供两种可选的链路,以应对不同下游系统对于数据实时性的不同要求:
- 近实时链路:任务管理系统将任务的修改的消息写入MQ,供血缘模块消费
- 离线链路:血缘模块周期性的调用任务管理系统的API接口,拉取全量(或增量)任务信息,进行处理
- 定义统一的Task模型,并通过TaskType来区分不同类型任务,确保后续处理的可扩展性:
- 不同任务管理系统,可能管理相同类型的任务,比如都支持FlinkSQL类型的任务;同一任务管理系统,有时会支持不同类型的任务,比如同时支持编写FlinkSQL和HiveSQL
- 新增任务管理系统或者任务类型,可以添加TaskType
血缘解析
- 定义统一的血缘数据模型LineageInfo,将在下一章节中展开讨论
- 针对不同的TaskType,灵活定制不同的解析实现,也支持不同TaskType可服用的兜底解析策略。比如:
- SQL类任务:比如HiveSQL与FlinkSQL,会调用SQL类的解析服务
- Data Transfer Service(DTS)类:解析任务中的配置,建立源与目标之间的血缘关系
- 其他类任务:比如一些通用任务会登记依赖和产出,报表类系统的控制面会提供报表来源的库表信息等
数据导出
- 血缘解析所产出的LineageInfo,会首先送入DataCatalog系统
- 支持三种集成方式:
- 对于Data Catalog中血缘相关API调用,实时拉取需要的血缘数据
- 消费MQ中的血缘修改增量消息,以近实时能力构造其他周边系统
- 消费数仓中的离线血缘导出数据,做分析梳理等业务
血缘的数据模型
概览

- 数据节点:对于存储数据的介质的抽象,比如一张Hive表,或者是Hive表的一列
- 任务节点:对于任务(或链路)的抽象,比如一个HiveSQL脚本
- 从数据节点指向任务节点的边:代表一种消费关系,任务读取了这个数据节点的数据
- 从任务节点指向数据节点的边:代表一种生产关系,任务生产了这个数据节点的数据
- 将血缘的生命周期与任务的生命周期统一,通过更新任务关联的边来更新血缘关系
- 可以灵活的支持从任务切入和从数据节点切入的不同场景。比如数据资产领域从数据节点切入的居多,而数据开发领域从任务切入的场景居多,不同的应用场景可以在一张大图上灵活遍历
字段(Column)级血缘
|
方案
|
优势
|
劣势
|
备注
|
|
1:复用任务节点,为字段之间的关系添加特殊定义的边
|
直观上更容易理解
|
边类型数量可能爆炸,写入与遍历复杂
|
上下游的Column之间映射关系多时,劣势明显
|
|
2:在字段之间添加冗余的任务节点,复用边的语义
|
统一了数据模型与遍历过程。
|
冗余了任务节点
|
通常字段之间的任务节点没有实际意义,如果想知道由什么任务引入的关联关系,可以多查询一次虚拟节点与任务节点之间的边。
|
血缘衡量指标
准确率
定义:假设一个任务实际的输入和产出与血缘中该任务的上游和下游相符,既不缺失也不多余,则认为这个任务的血缘是准确的,血缘准确的任务占全量任务的比例即为血缘准确率。
- SQL类任务:比如HiveSQL和FlinkSQL任务,血缘来源于SQL的解析,当SQL解析服务给出的质量保证是,成功解析的SQL任务,产生的血缘关系就一定是准确的,那么这类任务的血缘准确率,就可以转化成SQL解析的成功率。
- 数据集成(DTS)类任务:比如MySQL->Hive这类通道任务,血缘来源于对用户登记上下游映射关系的配置,这类血缘的准确率,可以转化成对于任务配置解析的成功率。
- 脚本类任务:比如shell,python任务等,这些血缘来源于用户登记的任务产出,这类血缘的准确率,可以转化成登记产出中正确的比例。
- 人工校验:通过构造测试用例来验证其他系统一样,血缘的准确性问题也可以通过构造用例来验证。实际操作时,我们会从线上运行的任务中采样出一部分,人工校验解析结果是否正确,有必要的时候,会mock掉输出,持续运行校验。
- 埋点数据验证:字节中的部分存储会产生访问埋点数据,通过清洗这些埋点数据,可以分析出部分场景的血缘链路,以此来校验程序中血缘产出的正确性。比如,HDFS的埋点数据可以用来校验很多Hive相关链路的血缘产出。
- 用户反馈:全量血缘集合的准确性验证是个浩瀚的过程,但是具体到某个用户的某个业务场景,问题就简化多了。实际操作中,我们会与一些业务方深入的合作,一起校验血缘准确性,并修复问题。
覆盖率
定义:当至少有一条血缘链路与资产相关时,称为资产被血缘覆盖到了。被血缘覆盖到的资产占关注资产的比例即为血缘覆盖率。
时效性
定义:从任务发生修改,到最终反应到血缘存储系统的端到端延时。
未来工作
火山引擎DataLeap的数据血缘用例与设计概述的更多相关文章
- 火山引擎 DataLeap:3 个关键步骤,复制字节跳动一站式数据治理经验
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,并进入官方交流群 DataLeap 是火山引擎数智平台 VeDI 旗下的大数据研发治理套件产品,帮助用户快速完成数据集成.开发.运维.治理. ...
- 火山引擎 DataLeap:揭秘字节跳动数据血缘架构演进之路
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 DataLeap 是火山引擎数智平台 VeDI 旗下的大数据研发治理套件产品,帮助用户快速完成数据集成.开发.运维 ...
- 火山引擎 DataLeap:一家企业,数据体系要怎么搭建?
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 导读:经过十多年的发展,数据治理在传统行业以及新兴互联网公司都已经产生落地实践.字节跳动也在探索一种分布式的数据治 ...
- 火山引擎 DataLeap 的 Data Catalog 系统公有云实践
Data Catalog 通过汇总技术和业务元数据,解决大数据生产者组织梳理数据.数据消费者找数和理解数的业务场景.本篇内容源自于火山引擎大数据研发治理套件 DataLeap 中的 Data Ca ...
- 如何又快又好实现 Catalog 系统搜索能力?火山引擎 DataLeap 这样做
摘要 DataLeap 是火山引擎数智平台 VeDI 旗下的大数据研发治理套件产品,帮助用户快速完成数据集成.开发.运维.治理.资产.安全等全套数据中台建设,降低工作成本和数据维护成本.挖掘数据价 ...
- 火山引擎DataLeap数据调度实例的 DAG 优化方案
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,并进入官方交流群 实例 DAG 介绍 DataLeap 是火山引擎自研的一站式大数据中台解决方案,集数据集成.开发.运维.治理.资产管理能力 ...
- 还原火山引擎 A/B 测试产品——DataTester 私有化部署实践经验
作为一款面向ToB市场的产品--火山引擎A/B测试(DataTester)为了满足客户对数据安全.合规问题等需求,探索私有化部署是产品无法绕开的一条路. 在面向ToB客户私有化的实际落地中,火 ...
- 火山引擎 A/B 测试产品——DataTester 私有化架构分享
作为一款面向 ToB 市场的产品--火山引擎A/B测试(DataTester)为了满足客户对数据安全.合规问题等需求,探索私有化部署是产品无法绕开的一条路. 在面向 ToB 客户私有化的实际落地中,火 ...
- 高性能、快响应!火山引擎 ByteHouse 物化视图功能及入门介绍
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 物化视图是指将视图的计算结果存储在数据库中的一种技术.当用户执行查询时,数据库会直接从已经预计算好的结果中获取数据 ...
- ROS数据可视化工具Rviz和三维物理引擎机器人仿真工具V-rep Morse Gazebo Webots USARSimRos等概述
ROS数据可视化工具Rviz和三维物理引擎机器人仿真工具V-rep Morse Gazebo Webots USARSimRos等概述 Rviz Rviz是ROS数据可视化工具,可以将类似字符串文本等 ...
随机推荐
- linux 条件语句和逻辑判断
目录 一.条件判断 二.逻辑判断 三.if和case 四.七个实验 一.条件判断 1.test测试 test [ 条件表达式 ] -e:测试目录是否存在 -d:测试是否为目录 -f:是否为文件 ...
- ChatGPT在工业领域的研究与应用探索-AI助手实验应用
为什么我的工作效率和质量要比其他人要高,因为我的电脑里有代码库.产品库.方案库.自己工作经验资料库等,根据一个应用场景或需求能够很快关联到想要的资料,并且整合成新的方案.我的核心竞争力是什么?各种资料 ...
- 了解基于模型的元学习:Learning to Learn优化策略和Meta-Learner LSTM
摘要:本文主要为大家讲解基于模型的元学习中的Learning to Learn优化策略和Meta-Learner LSTM. 本文分享自华为云社区<深度学习应用篇-元学习[16]:基于模型的元学 ...
- Gitlab版本升级
Gitlab docker部署命令 docker run -d -p 8443:443 -p 30080:80 -p 9444:22 --name gitlab --restart always \ ...
- 自然语言处理 Paddle NLP - 快递单信息抽取 (ERNIE 1.0)
文档检索:需要把业务问题拆解成子任务.文本分类 -> 文本匹配 -> 等任务 -> Panddle API 完成子任务 -> 子任务再拼起来 介绍 在2017年之前,工业界和学 ...
- WPF 入门笔记 - 05 - 依赖属性
如果预计中的不幸没有发生的话,我们就会收获意外的喜悦. --人生的智慧 - 叔本华 WPF属性系统 这一部分是中途加的,直接依赖属性有点迷糊,正好有了绑定的基础,理解起来还一些. WPF提供一组服务, ...
- 在线免费chatgpt网页版-支持gpt4
为了吸引更多的用户体验最先进的自然语言处理技术,我们推出了在线免费ChatGPT.这是一个基于OpenAI训练的大型语言模型,它可以提供智能响应.自然对话和语音识别等功能.不仅如此,我们还提供了完全免 ...
- 关于linq Where中的”或者“运算只查询出来满足一种条件的数据的问题,本质是IEnumerable和IQuerable之间的区别
如下代码所示,其中的"query"返回值类型为IQuerable var query = _deviceRepository.GetAll().AsNoTracking() .Wh ...
- 逍遥自在学C语言 | 多级指针探秘
前言 多级指针在C语言中是一种特殊的指针类型,它可以指向其他指针的指针. 通过多级指针,我们可以间接地访问或修改存储在内存中的数据. 在本文中,我们将讨论多级指针的概念.使用方法.使用场景以及常见错误 ...
- React后台管理系统 04 配置路径别名、全局样式设置、模块化scss
ts中对于@符号指定的路径不支持,同时vite中也是不支持的,所以我们需要在vite.config.ts中进行指定配置,path是node中自带的一个模块这里爆红的原因是没有进行声明: 我们使用命令对 ...