这才是批量update的正确姿势!
前言
最近我有位小伙伴问我,在实际工作中,批量更新的代码要怎么写。
这个问题挺有代表性的,今天拿出来给大家一起分享一下,希望对你会有所帮助。
1 案发现场
有一天上午,在我的知识星球群里,有位小伙伴问了我一个问题:批量更新你们一般是使用when case吗?还是有其他的批量更新方法?
我的回答是:咱们星球的商城项目中,有批量更新的代码可以参考一下,这个项目中很多代码,大家平时可以多看看。
然后我将关键代码发到群里了,这是批量重置用户密码的业务场景:
<update id="updateForBatch" parameterType="cn.net.susan.entity.sys.UserEntity">
<foreach collection="list" item="entity" separator=";">
UPDATE sys_user
SET password = #{entity.password},update_user_id=#{entity.updateUserId},update_user_name=#{entity.updateUserName}
<where>
id = #{entity.id}
</where>
</foreach>
</update>
有小伙伴说,第一次见到这种写法,涨知识了。
如果对知识星球感兴趣,可以点击这个:星球。
还有小伙伴问,上面这种写法,跟直接for循环中update有什么区别?
for(UserEntity userEntity: list) {
userMapper.update(userEntity);
}
直接for循环需要多次请求数据库,网络有一定的开销,很显然没有批量一次请求数据库的好。
2 其他的批量更新写法
有小伙说,他之前一直都是用的case when的写法。
类似下面这样的:
<update id="updateForBatch" parameterType="cn.net.susan.entity.sys.UserEntity">
update sys_user
<trim prefix="set" suffixOverrides=",">
<trim prefix="password = case id" suffix="end,">
<foreach collection="list" item="item">
when #{item.id} then #{item.password}
</foreach>
</trim>
<trim prefix="update_user_id = case id" suffix="end,">
<foreach collection="list" item="item">
when #{item.id} then #{item.updateUserId}
</foreach>
</trim>
<trim prefix="update_user_name = case id" suffix="end">
<foreach collection="list" item="item">
when #{item.id} then #{item.updateUserName}
</foreach>
</trim>
</trim>
<where>
id in (
<foreach collection="list" separator="," item="item">
#{item.id}
</foreach>
)
</where>
</update>
但这种写法显然需要拼接很多条件,有点复杂,而且性能也不太好。
还有些文章中介绍,可以使用在insert的时候,可以在语句最后加上ON DUPLICATE KEY UPDATE关键字。
<update id="updateForBatch" parameterType="cn.net.susan.entity.sys.UserEntity">
insert into sys_user
(id,username,password) values
<foreach collection="list" index="index" item="item" separator=",">
(#{item.id},
#{item.username},
#{item.password})
</foreach>
ON DUPLICATE KEY UPDATE
password=values(password)
</update>
在插入数据时,数据库会先判断数据是否存在,如果不存在,则执行插入操作。如果存在,则执行更新操作。
这种方式我之前也用过,一般需要创建唯一索引。
因为很多时候主键id,是自动增长的或者根据雪花算法生成的,每次都不一样,没法区分多次相同业务参数请求的唯一性。
因此,建议创建一个唯一索引,来保证业务数据的唯一性。
比如:给username创建唯一索引,在insert的时候,发现username已存在,则执行update操作,更新password。
这种方式批量更新数据,性能比较好,但一般的大公司很少会用,因为非常容易出现死锁的问题。
因此,目前批量更新数据最好的选择,还是我在文章开头介绍的第一种方法。
3 发现了一个问题
群里另外一位小伙伴,按照我的建议,在自己的项目中尝试了一下foreach的这种批量更新操作,但代码报了一个异常:
sql injection violation, multi-statement not allow
这个异常是阿里巴巴druid包的WallFilter中报出来了。
它里面有个checkInternal方法,会对sql语句做一些校验,如果不满足条件,就会抛异常:
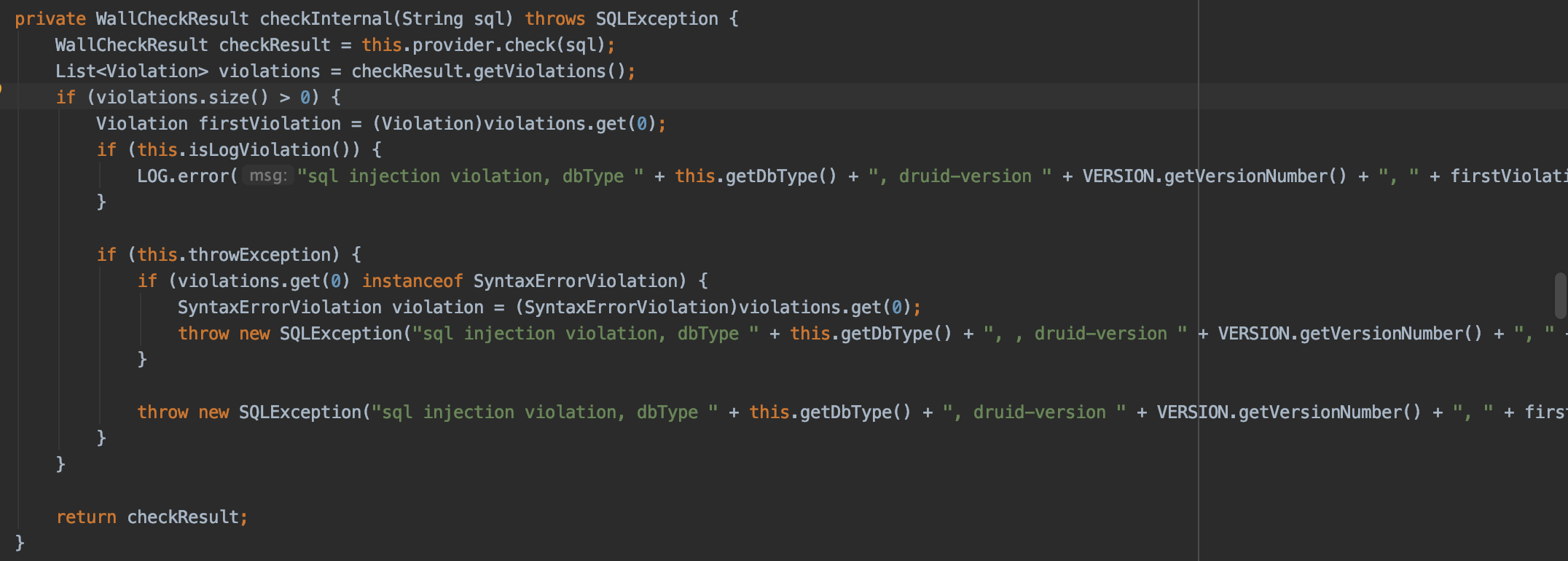
而druid默认不支持一条sql语句中包含多个statement语句,例如:我们的批量update数据的场景。
此外,MySQL默认也是关闭批量更新数据的,不过我们可以在jdbc的url要上,添加字符串参数:&allowMultiQueries=true,开启批量更新操作。
比如:
datasource:
type: com.alibaba.druid.pool.DruidDataSource
druid:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/console?useUnicode=true&characterEncoding=utf-8&useSSL=false&allowMultiQueries=true
username: root
password: root
这个改动非常简单。
但WallFilter中的校验问题如何解决呢?
于是,我上网查了一下,可以通过参数调整druid中的filter的判断逻辑,比如:
spring:
datasource:
url: jdbc:xxx&serverTimezone=Asia/Shanghai&rewriteBatchedStatements=true&allowMultiQueries=true
username: xxx
password: xxx
driver-class-name: com.mysql.cj.jdbc.Driver
type: com.alibaba.druid.pool.DruidDataSource
druid:
filter:
wall:
config:
multi-statement-allow: true
none-base-statement-allow: true
通过设置filter中的multi-statement-allow和none-base-statement-allow为true,这样就能开启批量更新的功能。
4 一直不生效
普通使用druid的datasource配置,通过上面这样调整是OK的。
但有些小伙伴发现,咱们的商城项目中,通过上面的两个地方的修改,还是一直报下面的异常:
sql injection violation, multi-statement not allow
这是怎么回事呢?
答:咱们商城项目中的订单表,使用shardingsphere做了分库分表,并且使用baomidou实现多个数据源动态切换的功能:
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>dynamic-datasource-spring-boot-starter</artifactId>
<version>3.1.1</version>
</dependency>
我们是使用了baomidou包下的数据源配置,这个配置在DynamicDataSourceProperties类中:
/**
* Copyright 2018 organization baomidou
* <pre>
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
* <pre/>
*/
package com.baomidou.dynamic.datasource.spring.boot.autoconfigure;
import com.baomidou.dynamic.datasource.spring.boot.autoconfigure.druid.DruidConfig;
import com.baomidou.dynamic.datasource.spring.boot.autoconfigure.hikari.HikariCpConfig;
import com.baomidou.dynamic.datasource.strategy.DynamicDataSourceStrategy;
import com.baomidou.dynamic.datasource.strategy.LoadBalanceDynamicDataSourceStrategy;
import com.baomidou.dynamic.datasource.toolkit.CryptoUtils;
import lombok.Getter;
import lombok.Setter;
import lombok.extern.slf4j.Slf4j;
import org.springframework.boot.autoconfigure.jdbc.DataSourceProperties;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.boot.context.properties.NestedConfigurationProperty;
import org.springframework.core.Ordered;
import java.util.LinkedHashMap;
import java.util.Map;
/**
* DynamicDataSourceProperties
*
* @author TaoYu Kanyuxia
* @see DataSourceProperties
* @since 1.0.0
*/
@Slf4j
@Getter
@Setter
@ConfigurationProperties(prefix = DynamicDataSourceProperties.PREFIX)
public class DynamicDataSourceProperties {
public static final String PREFIX = "spring.datasource.dynamic";
public static final String HEALTH = PREFIX + ".health";
/**
* 必须设置默认的库,默认master
*/
private String primary = "master";
/**
* 是否启用严格模式,默认不启动. 严格模式下未匹配到数据源直接报错, 非严格模式下则使用默认数据源primary所设置的数据源
*/
private Boolean strict = false;
/**
* 是否使用p6spy输出,默认不输出
*/
private Boolean p6spy = false;
/**
* 是否使用seata,默认不使用
*/
private Boolean seata = false;
/**
* 是否使用 spring actuator 监控检查,默认不检查
*/
private boolean health = false;
/**
* 每一个数据源
*/
private Map<String, DataSourceProperty> datasource = new LinkedHashMap<>();
/**
* 多数据源选择算法clazz,默认负载均衡算法
*/
private Class<? extends DynamicDataSourceStrategy> strategy = LoadBalanceDynamicDataSourceStrategy.class;
/**
* aop切面顺序,默认优先级最高
*/
private Integer order = Ordered.HIGHEST_PRECEDENCE;
/**
* Druid全局参数配置
*/
@NestedConfigurationProperty
private DruidConfig druid = new DruidConfig();
/**
* HikariCp全局参数配置
*/
@NestedConfigurationProperty
private HikariCpConfig hikari = new HikariCpConfig();
/**
* 全局默认publicKey
*/
private String publicKey = CryptoUtils.DEFAULT_PUBLIC_KEY_STRING;
}
这个类是数据库的配置类,我们可以看到master和druid的配置是在同一层级的,于是,将application.yml文件中的配置改成下面这样的:
spring:
application:
name: mall-job
datasource:
dynamic:
primary: master
datasource:
master:
username: root
password: 123456
url: jdbc:mysql://localhost:3306/susan_mall?serverTimezone=Asia/Shanghai&characterEncoding=utf8&useSSL=false&zeroDateTimeBehavior=convertToNull
driver-class-name: com.mysql.cj.jdbc.Driver
druid:
wall:
multiStatementAllow: true
noneBaseStatementAllow: true
这样改动之后,商城项目中使用foreach这种批量更新数据的功能OK了。
5 最后
本文由一位球友的问题开始,讨论了批量更新的四种常见方式:
- for循环中一条条更新
- foreach拼接update语句后批量更新。
- 使用case when的方式做判断。
- 使用insert into on duplicate key update语法,批量插入或者批量更新。
虽说有很多种方式,但我个人认为批量update的最佳方式是第2种方式。
但需要需要的地方是,使用foreach做批量更新的时候,一次性更新的数据不宜太多,尽量控制在1000以内,这样更新的性能还是不错的。
如果需要更新的数据超过了1000,则需要分成多批更新。
此外,如果大家遇到执行批量update操作,不支持批量更新问题时:
sql injection violation, multi-statement not allow
首先要在数据库连接的url后面增加&allowMultiQueries=true参数,开启数据的批量更新操作。
如果使用了druid数据库驱动的,可以在配置文件中调整filter的参数。
spring:
datasource:
druid:
filter:
wall:
config:
multi-statement-allow: true
none-base-statement-allow: true
主要是multi-statement-allow设置成true。
如果你还使用了其他第三方的数据库中间件,比如我使用了baomidou实现多个数据源动态切换的功能。
这时候,需要查看它的源码,确认它multi-statement-allow的配置参数是怎么配置的,有可能跟druid不一样。
最后说一句(求关注,别白嫖我)
如果这篇文章对您有所帮助,或者有所启发的话,帮忙扫描下发二维码关注一下,您的支持是我坚持写作最大的动力。
求一键三连:点赞、转发、在看。
关注公众号:【苏三说技术】,在公众号中回复:进大厂,可以免费获取我最近整理的10万字的面试宝典,好多小伙伴靠这个宝典拿到了多家大厂的offer。
这才是批量update的正确姿势!的更多相关文章
- Spring Boot 2实现分布式锁——这才是实现分布式锁的正确姿势!
参考资料 网址 Spring Boot 2实现分布式锁--这才是实现分布式锁的正确姿势! http://www.spring4all.com/article/6892
- 这才是使用ps命令的正确姿势
这才是使用ps命令的正确姿势 前言 在linux系统当中我们通常会使用命令去查看一些系统的进程信息,我们最常使用的就是 ps (process status).ps 命令主要是用于查看当前正在运行的程 ...
- 升级pip3的正确姿势--python3 pip3 update
升级pip3的正确姿势为: pip3 install --upgrade pip 而不是 pip3 install --upgrade pip3
- 转载 Python 操作 MySQL 的正确姿势 - 琉璃块
Python 操作 MySQL 的正确姿势 收录待用,修改转载已取得腾讯云授权 作者 |邵建永 编辑 | 顾乡 使用Python进行MySQL的库主要有三个,Python-MySQL(更熟悉的名字可能 ...
- 在Linux(ubuntu server)上面安装NodeJS的正确姿势
上一篇文章,我介绍了 在Windows中安装NodeJS的正确姿势,这一篇,我们继续来看一下在Linux上面安装和配置NodeJS. 为了保持一致,这里也列举三个方法 第一个方法:通过官网下载安装 h ...
- ios监听ScrollView/TableView滚动的正确姿势
主要介绍 监测tableView垂直滚动的舒畅姿势 监测scrollView/collectionView横向滚动的正确姿势 1.监测tableView垂直滚动的舒畅姿势 通常我们用KVO或者在scr ...
- 程序员节应该写博客之.NET下使用HTTP请求的正确姿势
程序员节应该写博客之.NET下使用HTTP请求的正确姿势 一.前言 去年9月份的时候我看到过外国朋友关于.NET Framework下HttpClient缺陷的分析后对HttpClient有了一定的了 ...
- Redis实现分布式锁的正确姿势
分布式锁一般有三种实现方式:1. 数据库乐观锁:2. 基于Redis的分布式锁:3. 基于ZooKeeper的分布式锁.本篇博客将介绍第二种方式,基于Redis实现分布式锁.虽然网上已经有各种介绍Re ...
- 使用 Java8 Optional 的正确姿势(转)
我们知道 Java 8 增加了一些很有用的 API, 其中一个就是 Optional. 如果对它不稍假探索, 只是轻描淡写的认为它可以优雅的解决 NullPointException 的问题, 于是代 ...
- Golang错误和异常处理的正确姿势
Golang错误和异常处理的正确姿势 错误和异常是两个不同的概念,非常容易混淆.很多程序员习惯将一切非正常情况都看做错误,而不区分错误和异常,即使程序中可能有异常抛出,也将异常及时捕获并转换成错误.从 ...
随机推荐
- [rCore学习笔记 06]运行Lib-OS
QEMU运行第一章代码 切换分支 git checkout ch1 detail git checkout ch1 命令是用来切换到名为 ch1 的分支或者恢复工作目录中的文件到 ch1 提交的状态 ...
- 使用JavaScript编写vue指令v-model,v-model原理实现
首先先要知道的是v-model的作用是实现数据的双向绑定,即: 数据在视图层的双向响应. 实现思路主要分为两步: 第一步:数据层到视图层的响应 将数据响应到视图层的方式,在vue2使用的是Object ...
- Cython与C函数的结合
技术背景 在前面一篇博客中,我们介绍了使用Cython加速谐振势计算的方法.有了Cython对于计算过程更加灵活的配置(本质上是时间占用和空间占用的一种均衡),及其接近于C的性能,并且还最大程度上的保 ...
- 搭建lnmp环境-php(第二步)
系统环境:centos7 php7.4 编译安装太繁琐,这里用yum安装即可 ===========yum形式安装======== # 安装EPEL源(nginx那里已安装了,跳过) yum inst ...
- 记一些java里的数据结构
0.Vector:过期的,被arraylist取代了 0.1Stack:也不建议使用 1.双向链表LinkedList:由list实现的接口类 2.队列Queue:操作为add remove elem ...
- k8s 环境搭建(2)
安装docker组件 配置本地源或者自带的网络源2选1 1.切换镜像源 wget https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce ...
- python变量 方法 属性
python变量 方法 属性 所有成员中,只有普通变量/字段/属性的内容保存对象中,即:根据此类创建了多少对象,在内存中就有多少个普通变量/字段/属性.而其他的成员,则都是保存在类中,即:无论对象的多 ...
- 解决004--Loading local data is disabled; this must be enabled on both the client and server sides问题及解决
因为下载了SQLyog的ultimate版本,现在就可以导入外部的数据了.有着之前使用insert into插入语句来添加近50条有着大概10个字段的记录的经历之后,本着能够导入现成的数据就导入的想法 ...
- 【Java】删除项目中多余的SVG图片资源
在DB库的菜单表,每个菜单会存放对应的svg图片名称,用于菜单渲染 在页面中的渲染: 在项目的目录的存放位置: 需求是这个目录还存放了很多不需要的svg图片,需要把他们删除掉 数量有七八十张,人肉手删 ...
- 【Spring-Security】Re09 CSFR处理
一.CSRF: CSRF 全称 Cross Site Request Forgery 跨站请求伪造 又称为OneClick Attack & SessionRiding 是非法请求访问,通过伪 ...