docker 安装 elasticsearch 集群
此处部署为单个服务器启动三个elasticsearch容器
问题:本打算在三个服务器上单独部署elasticsearch 容器,elasticsearch.yml 注册用的宿主机ip,但是容器之间通信发现用的是容器内部ip,导致节点之间通信失败,只能发现master节点,待大佬们解疑答惑
修改 max_map_count 否则启动失败,提示该值设置为262144
cat /proc/sys/vm/max_map_count
sysctl -w vm.max_map_count=262144
分别创建三个节点配置文件挂载目录
拉取 elasticsearch 镜像
docker pull elasticsearch:7.14.0
先启动一个容器,并将配置文件复制出来
docker run --name es01 -d -e ES_JAVA_OPTS="-Xms512m -Xmx512m" -v /opt/es01/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml -p 9200:9200 -p 9300:9300 elasticsearch:7.14.0
docker cp es01:/usr/share/elasticsearch/config/elasticsearch.yml /opt/es01/config
修改 es01 elasticsearch.yml
# 集群名称
cluster.name: es-cluster
# 节点名称
node.name: es-node1
# 启用该物理机器所有网卡网络访问
network.host: 0.0.0.0
http.host: 0.0.0.0
# 跨域
http.cors.enabled: true
http.cors.allow-origin: "*"
# 当前节点是否可以被选举为master节点,是:true、否:false
node.master: true
# 当前节点是否用于存储数据,是:true、否:false
node.data: true
# 设置节点之间通信的端口
transport.tcp.port: 9300
# es7.x 之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点
discovery.seed_hosts: 192.168.202.128:9300
# es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举master
cluster.initial_master_nodes: es-node1
# elasticsearch和其他节点通信的地址,如果不设置的话 会自动获取
network.publish_host: 192.168.202.128
# host地址,默认为network.host
transport.host: 0.0.0.0
# 设置这个集群,有多少个节点有master候选资格,如果集群较大官方建议为2-4个
discovery.zen.minimum_master_nodes: 1
docker restart es01
复制 elasticsearch.yml 到其他两个 es 挂载目录
es02 elasticsearch.yml
cluster.name: es-cluster
node.name: es-node2
network.host: 0.0.0.0
http.host: 0.0.0.0
http.cors.enabled: true
http.cors.allow-origin: "*"
node.master: true
node.data: true
transport.tcp.port: 9301
discovery.seed_hosts: 192.168.202.128:9300
cluster.initial_master_nodes: es-node1
network.publish_host: 192.168.202.128
transport.host: 0.0.0.0
discovery.zen.minimum_master_nodes: 1
es03 elasticsearch.yml
cluster.name: es-cluster
node.name: es-node3
network.host: 0.0.0.0
http.host: 0.0.0.0
http.cors.enabled: true
http.cors.allow-origin: "*"
node.master: true
node.data: true
transport.tcp.port: 9302
discovery.seed_hosts: 192.168.202.128:9300
cluster.initial_master_nodes: es-node1
network.publish_host: 192.168.202.128
transport.host: 0.0.0.0
discovery.zen.minimum_master_nodes: 1
启动es02 、 es03
docker run --name es02 -d -e ES_JAVA_OPTS="-Xms512m -Xmx512m" -v /opt/es02/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml -p 9201:9200 -p 9301:9300 elasticsearch:7.14.0 docker run --name es03 -d -e ES_JAVA_OPTS="-Xms512m -Xmx512m" -v /opt/es03/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml -p 9202:9200 -p 9302:9300 elasticsearch:7.14.0
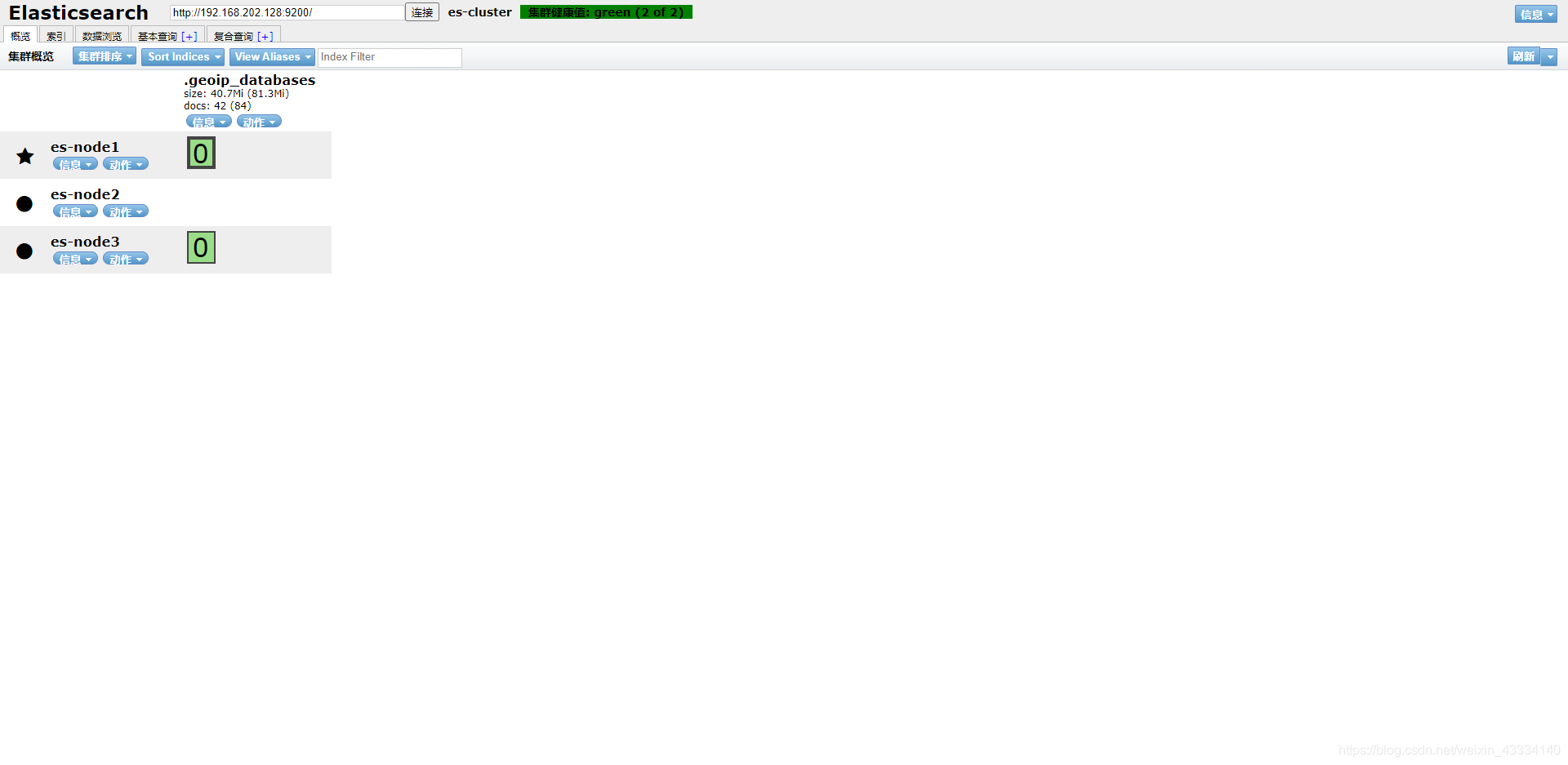
es 启动较慢,别着急 ,访问接口 http://192.168.202.128:9200/_cat/nodes
172.17.0.2 72 97 1 0.08 0.11 0.14 cdfhilmrstw * es-node1
172.17.0.4 53 97 1 0.08 0.11 0.14 cdfhilmrstw - es-node3
172.17.0.3 69 97 1 0.08 0.11 0.14 cdfhilmrstw - es-node2
显示以上信息表示集群搭建成功
安装 elasticsearch-head 可视化界面
#拉取镜像
docker pull mobz/elasticsearch-head:5 #创建容器
docker create --name elasticsearch-head -p 9100:9100 mobz/elasticsearch-head:5 #启动容器
docker start elasticsearch-head
or
docker start 容器id (docker ps -a 查看容器id )
启动成功后访问 http://192.168.202.128:9100/
docker 安装 elasticsearch 集群的更多相关文章
- Docker部署Elasticsearch集群
http://blog.sina.com.cn/s/blog_8ea8e9d50102wwik.html Docker部署Elasticsearch集群 参考文档: https://hub.docke ...
- Elasticsearch使用系列-Docker搭建Elasticsearch集群
Elasticsearch使用系列-ES简介和环境搭建 Elasticsearch使用系列-ES增删查改基本操作+ik分词 Elasticsearch使用系列-基本查询和聚合查询+sql插件 Elas ...
- docker安装hadoop集群
docker安装hadoop集群?图啥呢?不图啥,就是图好玩.本篇博客主要是来教大家如何搭建一个docker的hadoop集群.不要问 为什么我要做这么无聊的事情,答案你也许知道,因为没有女票.... ...
- Docker安装Consul集群
Docker 安装Consul集群 使用windows 环境,Docker desktop community 构建consul集群. 1.docker 容器网络 docker安装后,默认会创建三种网 ...
- 基于docker安装pxc集群
基于docker安装pxc集群 一.PXC 集群的安装 PXC集群比较特殊,需要安装在 linux 或 Docker 之上.这里使用 Docker进行安装! Docker的镜像仓库中包含了 PXC数据 ...
- 使用Docker搭建Elasticsearch集群环境
本篇文章首发于头条号单机如何搭建Elasticsearch集群?使用容器技术快速构建集群环境,欢迎关注头条号和微信公众号"大数据技术和人工智能"(微信搜索bigdata_ai_te ...
- k8s上安装elasticsearch集群
官方文档地址:https://www.elastic.co/guide/en/cloud-on-k8s/current/k8s-quickstart.html yaml文件地址:https://dow ...
- 基于docker搭建elasticsearch集群
es集群的搭建 - 基于单机搭建elasticsearch集群见官网 https://www.elastic.co/guide/en/elasticsearch/reference/current/d ...
- Centos8 Docker部署ElasticSearch集群
ELK部署 部署ElasticSearch集群 1.拉取镜像及批量生成配置文件 # 拉取镜像 [root@VM-24-9-centos ~]# docker pull elasticsearch:7. ...
- 利用 docker 部署 elasticsearch 集群(单节点多实例)
文章目录 1.环境介绍 2.拉取 `elasticserach` 镜像 3.创建 `elasticsearch` 数据目录 4.创建 `elasticsearch` 配置文件 5.配置JVM线程数量限 ...
随机推荐
- 单细胞测序最好的教程(十四)测序原始数据公开至NCBI数据库
作者按 国内对于单细胞测序相关的中文教程确实不够全面,当然NCBI官网给的上传教程也比较详细了,所以变成了会者不难.本教程你现在可能用不上,但是你如果做单细胞测序,那么未来你一定会用上,建议收藏. 在 ...
- 【js】 reduce、filter、map 数组链式调用求加和
let data = [ {hierarchy: '香蕉', count: 1}, {hierarchy: '苹果', count: 2}, {hierarchy: '葡萄', count: 3}, ...
- hmall | 引入ES实现高效搜索与同步双写
在gitee.飞书.百度云.B站中,黑马都没有上传该部分资料,以下皆为个人观点,如有纰漏欢迎指正 1.先把item-service中的searchcontroller抽出来,抽到一个模块中并将其设为h ...
- 趣谈n++与++n的differences
前言:今天小白在学习时无意发现一组有趣的孪生兄弟** n++ 与 ++n** 探索:二者不同之处 工具:VS2022 过程: 前者是++n,输出11,12,13,14 后者是n++,输出10,11,1 ...
- 【Java】CompletableFuture 异步任务编排
参考视频资料: https://www.bilibili.com/video/BV1nA411g7d2 https://www.bilibili.com/video/BV1S54y1u79K 一.启动 ...
- 【H5】16 表单 其五 表单验证
在将数据提交到服务器之前,重要的是确保以正确的格式填写所有必需的表单控件.这称为客户端表单验证,可帮助确保所提交的数据符合各种表单控件中规定的要求.本文将引导您通过基本概念和客户端表单验证示例. 先决 ...
- Jax框架的显存分析已经不支持gperftools,而是支持go语言下的新版本pprof
官方: https://jax.readthedocs.io/en/latest/device_memory_profiling.html
- 【转载】 5:0!AI战胜人类教官,AlphaDogfight大赛落幕
原文:https://baijiahao.baidu.com/s?id=1675621109599102721&wfr=spider&for=pc ------------------ ...
- Spring Boot 基于 SCRAM 认证集成 Kafka 的详解
一.说明 在现代微服务架构中,Kafka 作为消息中间件被广泛使用,而安全性则是其中的一个关键因素.在本篇文章中,我们将探讨如何在 Spring Boot 应用中集成 Kafka 并使用 SCRAM ...
- DolphinScheduler分布式集群部署指南(小白版)
官方文档地址:https://dolphinscheduler.apache.org/zh-cn/docs/3.1.9 DolphinScheduler简介 摘自官网:Apache DolphinSc ...