开发必会系列:《深入理解JVM(第二版)》读书笔记
- http://www.cnblogs.com/sunilsun/p/6078171.html ubuntu 编译OPENJDK8
- 运行时内存
- 运行时数据区:
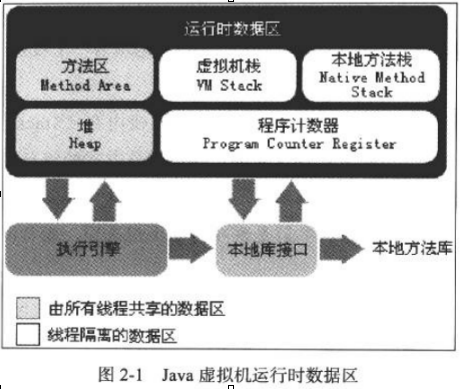
- 线程请求的栈深度大于虚拟机所允许的深度——StackOverflowError
- 当前大部分虚拟机可动态扩展,虚拟机栈在动态扩展时无法申请到足够的内存——OutOfMemoryError
- 本地方法栈:
- Java堆:
- 方法区:
- 检查完类加载,虚拟机就为新生对象分配内存。大小在类加载完后就能确定了。分配内存会触发java堆中指针碰撞(Bump the Pointer)或空闲列表(Free List)——遇到并发,可以采用CAS保证原子性或TLAB本地线程分配缓冲。
- 对对象进行设置,把类元数据信息、对象哈希码、对象GC分代年龄存到对象头(Object Header)
- 这时虚拟机的活干完了,但java程序还需要执行<init>方法
- 在Debug/Run的VM arguments写
- 在代码中做文档注释写:
- 虚拟机栈和本地方法栈溢出
- 方法区和运行时常量池溢出
- 垃圾收集器和内存分配策略
- 判断堆里实例对象死了没
- 引用,JDK1.2后,引用分四类:
- 方法区回收
- 垃圾收集算法
- hotspot的算法实现
- 具体咋收垃圾?垃圾收集器

- 虚拟机性能监控与故障处理工具
- jdk命令行工具
- jps,虚拟机进程状况工具。进程的本地虚拟机唯一ID(Local Virtual Machine Identifier, LVMID),它与操作系统进程(Process Identifier, PID)一致。
- 可视化工具
- 调优实战
- 高性能硬件上的程序部署策略
- 通过64位JDK来使用大内存
- 使用若干个32位虚拟机建立逻辑集群来利用硬件资源

- 集群间同步导致的内存溢出:避免过于频繁的写操作。
- 堆外内存导致的溢出错误:直接内存的问题

- 类文件结构
- 魔数
- 常量池
- 常量池后面,是访问标志,用于识别类或接口的访问信息。比如:这个Class是类还是接口,它是不是public类型……
- 后面是类索引、父类索引和接口索引,这三项数据确定这个类的继承关系。
- 后面是字段表集合,字段表用于描述接口或者类中声明的变量。此外还有方法表和属性表。
- 虚拟机类加载机制
- 类加载过程
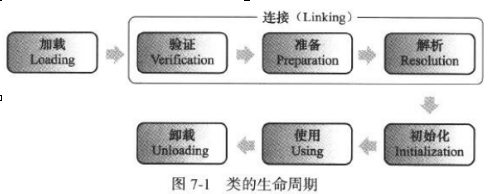
- 类加载器:
- 虚拟机如何执行定义在Class文件里的字节码
- 运行时栈针结构
- 局部变量表:其容量以变量槽(Variable Slot)为最小单位。
- 运行期优化
- 虚拟机刚开始用解释器解释执行,省编译时间,但渐渐发现某个代码很常用,就通过即时编译器JIT把它编译成与本地平台相关的机器码,提高运行效率。如何发现热点代码——方法调用计数器,计数器超过一定阈值,就触发JIT编译。
- 线程安全和锁优化
- 线程安全实现:
- 互斥同步:属于悲观,重量级锁。
- 非阻塞同步:乐观。
- 无同步
- 锁优化
- 自旋锁与自适应自旋:
- 锁消除:
- 锁粗化:
- 轻量级锁:
- 偏向锁:
开发必会系列:《深入理解JVM(第二版)》读书笔记的更多相关文章
- Spring 实战 第4版 读书笔记
第一部分:Spring的核心 1.第一章:Spring之旅 1.1.简化Java开发 创建Spring的主要目的是用来替代更加重量级的企业级Java技术,尤其是EJB.相对EJB来说,Spring提供 ...
- 深入浅出MySQL 数据库开发、优化与管理维护(第2版) -- 读书笔记 -- 基础篇
1.切换数据库 use blog; 2.显示当前数据库 所有的表. show tables; +----------------+ | Tables_in_blog | +------------ ...
- Spring实战第4版PDF下载含源码
下载链接 扫描右侧公告中二维码,回复[spring实战]即可获取所有链接. 读者评价 看了一半后在做评论,物流速度挺快,正版行货,只是运输过程有点印记,但是想必大家和你关注内容,spring 4必之3 ...
- Spring实战(第4版).pdf - 百度云资源
http://www.supan.vip/spring%E5%AE%9E%E6%88%98 Spring实战(第4版).pdf 关于本书 Spring框架是以简化Java EE应用程序的开发为目标而创 ...
- Spring实战第六章学习笔记————渲染Web视图
Spring实战第六章学习笔记----渲染Web视图 理解视图解析 在之前所编写的控制器方法都没有直接产生浏览器所需的HTML.这些方法只是将一些数据传入到模型中然后再将模型传递给一个用来渲染的视图. ...
- Spring实战第五章学习笔记————构建Spring Web应用程序
Spring实战第五章学习笔记----构建Spring Web应用程序 Spring MVC基于模型-视图-控制器(Model-View-Controller)模式实现,它能够构建像Spring框架那 ...
- Spring实战第四章学习笔记————面向切面的Spring
Spring实战第四章学习笔记----面向切面的Spring 什么是面向切面的编程 我们把影响应用多处的功能描述为横切关注点.比如安全就是一个横切关注点,应用中许多方法都会涉及安全规则.而切面可以帮我 ...
- 将Spring实战第5版中Spring HATEOAS部分代码迁移到Spring HATEOAS 1.0
最近在阅读Spring实战第五版中文版,书中第6章关于Spring HATEOAS部分代码使用的是Spring HATEOAS 0.25的版本,而最新的Spring HATEOAS 1.0对旧版的AP ...
- ASP.NET MVC开发必看系列
一.关于HTTP协议的那些事 这可以说我们开发WEB程序的空气,推荐不断温故知新! HTTP协议 (一) HTTP协议详解 HTTP协议 (二) 基本认证 HTTP协议 (三) 压缩 HTTP协议 ( ...
- Spring实战 (第3版)——AOP
在软件开发中,分布于应用中多处的功能被称为横切关注点.通常,这些横切关注点从概念上是与应用的 业务逻辑相分离的(但是往往直接嵌入到应用的业务逻辑之中).将这些横切关注点与业务逻辑相分离正是 面向切面编 ...
随机推荐
- 【LGR-156-Div.3】洛谷网校 8 月普及组月赛 I & MXOI Round 1 & 飞熊杯 #2(同步赛)
[LGR-156-Div.3]洛谷网校 8 月普及组月赛 I & MXOI Round 1 & 飞熊杯 #2(同步赛) \(T1\) luogu P9581 宝箱 \(100pts\) ...
- Python 中获取文件名
Python 获取文件名import osimport sys # ①获取当前文件名os.path.basename(__file__)# ②获取程序启动文件名os.path.basename(sys ...
- C语言中,指针变量的坑
先看一个初始化带头结点单链表的例子,LNode是结点变量,LinkList是结点指针变量,等同于LNode* typedef struct LNode{ // 定义单链表节点类型 int data; ...
- MySQL查看bin_log日志
有这样一段业务逻辑,首先保存业务数据,然后发送报文,最后确认报文回来以后更新业务数据.伪代码大概是这样的: /** * 保存数据,并调用发送报文方法 */ public void save() { / ...
- Js中Symbol对象
Js中Symbol对象 ES6引入了一种新的基本数据类型Symbol,表示独一无二的值,最大的用法是用来定义对象的唯一属性名,Symbol()函数会返回symbol类型的值,该类型具有静态属性和静态方 ...
- ORA-22828 输入样式或替换参数超过了32k大小限制
今天调试程序报以下错误: ORA-22828: input pattern or replacement parameters exceed 32K size limit 22828. 00000 - ...
- jenkins配置github秘钥
1.登录github,打开Settings 2.点击Developer settings 3.点击Personal access tokens-->Generate new token 4.勾选 ...
- git回退至指定版本,并更新远程仓库
1. git log 查到commit记录 2.复制 commit 后面的id 3. git reset --hard commit 后面的id // 回退 4. 强制更新远程仓库 git ...
- 关于RabbitMQ消费者预取消息数量参数的合理设置
根据RabbitMQ官方文档描述,可以通过"预取数量"来限制未被确认的消息个数,本质上这也是一种对消费者进行流控的方法. 详见:https://www.rabbitmq.com/c ...
- python selenium list index out of range
常见错误原因 常见错误原因 其他错误原因 场景 使用selenium循环打开并跳转到新的网页,然后关闭新的窗口,然后回到原来窗口,这时候获取list中的值,报错: list index out of ...