OGG-Postgres实时同步到Kafka
(一)数据同步信息
|
名称 |
源端 |
名称 |
目标端 |
|
数据库类型 |
Postgresql 12.4 |
组件类型 |
Kafka |
|
IP地址 |
20.2.127.23 |
Broker地址 |
20.2.125.52:9092, 20.2.127.23:9092, 20.2.127.24:9092 |
|
端口 |
5432 |
端口 |
9092 |
|
数据库 |
testpdb |
Zookeeper |
Hadoop01:2181,hadoop02:2181,hadoop03:2181 |
|
用户 |
ogguser |
||
|
密码 |
ogguserP2021 |
||
|
表名 |
tb01 |
Topic |
oggtb01 |
postgreSQL数据库配置:
vi postgresql.conf
wal_level = logical # minimal, replica, or logical
# (change requires restart)
max_wal_senders = 10 # max number of walsender processes
# (change requires restart)
max_replication_slots = 10 # max number of replication slots
# (change requires restart)
修改后需要重启数据库。
(二)OGG安装信息
|
名称 |
源端OGG |
目标端OGG |
|
OGG版本 |
213000_ggs_Linux_x64_PostgreSQL_64bit.zip |
214000_ggs_Linux_x64_BigData_64bit.zip |
|
安装服务器IP |
20.2.125.52(hadoop03) |
20.2.125.52(hadoop03) |
|
OGG_HOME |
/data/ogg_pg/ |
/data/ogg_bigdata/ |
|
MGR进程 |
mgr |
mgr |
|
EXTRACT进程 |
pgext2 |
— |
|
PUMP进程 |
pgpump2 |
— |
|
REPLICAT进程 |
— |
mqkafka2 |
(三)前提准备
1.安装Java1.8及以上版本
2.设置环境变量
编辑变量:
vi /etc/profile
export LD_LIBRARY_PATH=/data/ogg_pg/lib:/data/ogg_mysql/lib:/data/ogg_bigdata/lib:$LD_LIBRARY_PATH
alias pg_ggsci='cd /data/ogg_pg; ./ggsci'
alias mysql_ggsci='cd /data/ogg_mysql; ./ggsci'
alias bigdata_ggsci='cd /data/ogg_bigdata; ./ggsci'
使环境变量生效
source /etc/profile
3.在PostgreSQL中创建库表
--创建数据库testpdb
create database testpdb ;
--进入testpdb数据库
\c testpdb
--创建表tb01
create table tb01(id int not null, name varchar(16), ts timestamp , primary key(id) );
4.在Kafka中创建Topic
cd /usr/local/kafka/bin
--创建一个名称为oggtb01的Topic,4个分区,并且复制因子为3:
./kafka-topics.sh --create --zookeeper hadoop01:2181,hadoop02:2181,hadoop03:2181 --replication-factor 3 --partitions 3 --topic oggtb01

--查看所有的topic
./kafka-topics.sh --describe --zookeeper hadoop01:2181,hadoop02:2181,hadoop03:2181
(四)OGG源端配置
1.启动PG的ggsci
pg_ggsci
2.PG 创建目录
create subdirs
3.配置并启动MGR
--编辑MGR
edit param mgr
port 2031
dynamicportlist 2032-2040
purgeoldextracts ./dirdat/*, usecheckpoints,minkeephours 24
AUTORESTART ER *, RETRIES 3, WAITMINUTES 2,RESETMINUTES 10
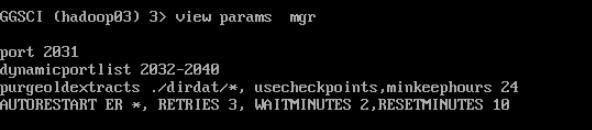
--查看MGR配置参数
view params mgr
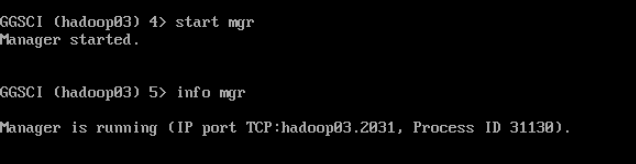
--启动MGR
start mgr
--查看MGR状态
Info mgr
4.登录PG数据库
cd /data/ogg_pg/
编辑 odbc.ini
[ODBC Data Sources]
PGDSN=DataDirect 12.4 PostgreSQL Wire Protocol
postgres=DataDirect 12.4 PostgreSQL Wire Protocol
scott=DataDirect 12.4 PostgreSQL Wire Protocol
[ODBC]
IANAAppCodePage=106
InstallDir=/data/ogg_pg
[TESTPDB]
Driver=/data/ogg_pg/lib/GGpsql25.so
Description=DataDirect 12.4 PostgreSQL Wire Protocol
Database=testpdb
HostName=20.2.127.23
PortNumber=5432
LogonID=ogguser
Password=ogguserP2021
TransactionErrorBehavior=2
--查看odbc.ini配置
shell cat odbc.ini
将如下一行添加到/etc/profile
export ODBCINI=/data/ogg_pg/odbc.ini
使环境变量生效
source /etc/profile

--登录
dblogin sourcedb testpdb, userid ogguser, password ogguserP2021

如果登录时报错,说明ODBCINI变量没有配置或者没有生效。

5.配置抽取进程
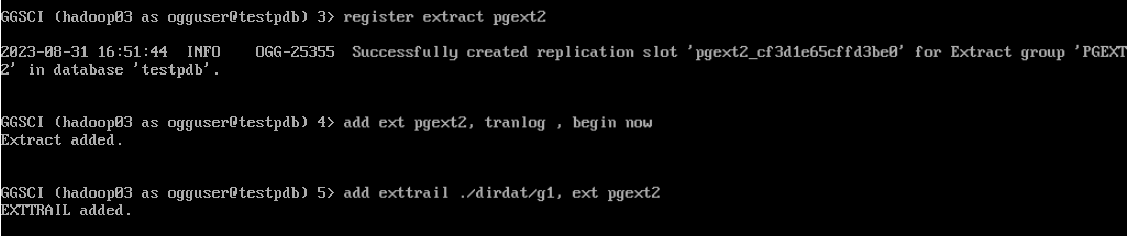
--注册抽取
register extract pgext2
--增加抽取进程日志
add ext pgext2, tranlog , begin now
add exttrail ./dirdat/g1, ext pgext2
--编辑抽取参数
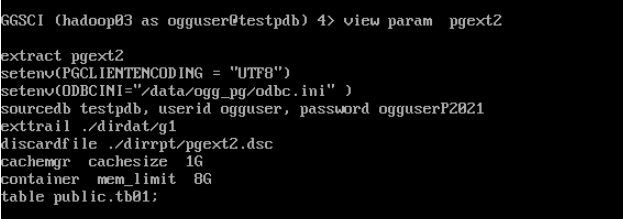
edit param pgext2
extract pgext2
setenv(PGCLIENTENCODING = "UTF8")
setenv(ODBCINI="/data/ogg_pg/odbc.ini" )
sourcedb testpdb, userid ogguser, password ogguserP2021
exttrail ./dirdat/g1
discardfile ./dirrpt/pgext2.dsc
cachemgr cachesize 1G
container mem_limit 8G
table public.tb01;
--查看抽取参数
view param pgext2
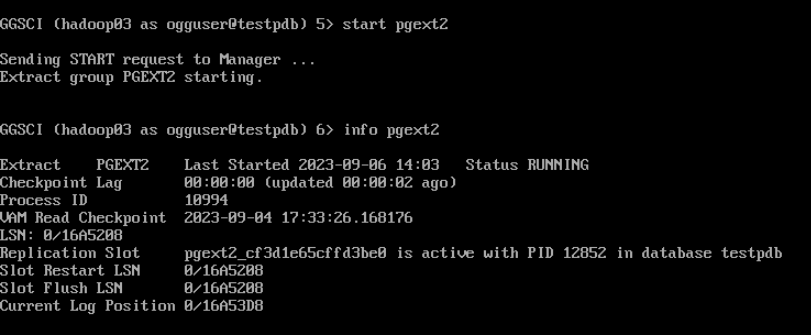
--启动抽取进程
start pgext2
--查看进程状态
info pgext2
6.配置投递进程
--编辑投递参数
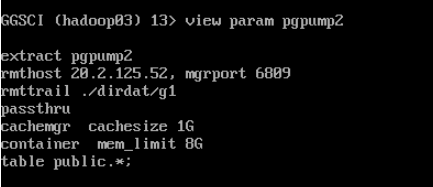
edit param pgpump2
extract pgpump2
rmthost 20.2.125.52, mgrport 6809
rmttrail ./dirdat/g1
passthru
cachemgr cachesize 1G
container mem_limit 8G
table public.tb01;
--查看配置投递参数
view param pgpump2
--添加投递进程日志
add extract pgpump2, exttrailsource ./dirdat/g1
add rmttrail ./dirdat/g1, extract pgpump2

--启动投递进程
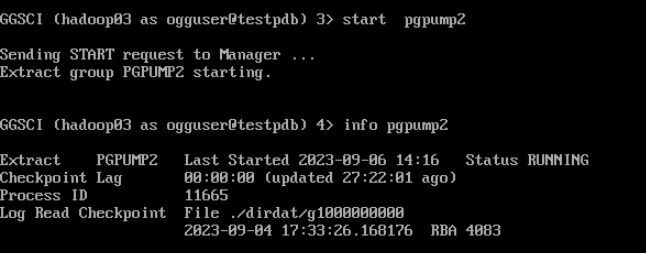
start pgpump2
--查看投递进程状态
Info pgpump2
7.测试抽取和投递进程
(1)登录PG数据库,插入数据
--创建sequence
create sequence seq01 increment by 1 start 1;
--以下语句手动执行,可以多执行几次。
insert into tb01
select
nextval('seq01'),
array_to_string(array(select substring('0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz' FROM (ceil(random()*62))::int FOR 1) FROM generate_series(1, 16)), ''),
now();
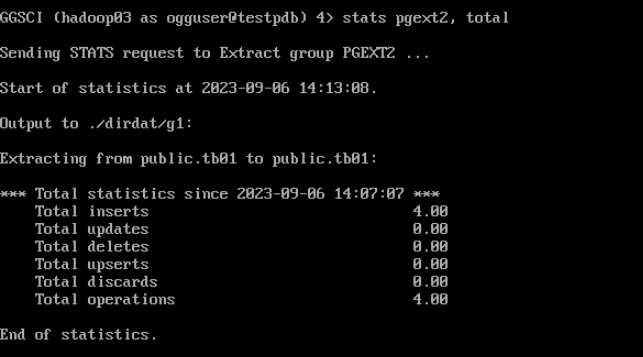
(2)登录源端OGG,查看抽取和投递统计信息
--OGG查看统计信息
stats pgext2, total
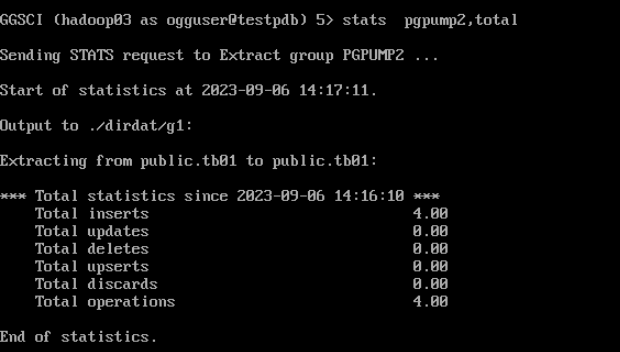
--查看投递统计信息
stats pgpump2,total
(五)OGG目标端配置
1.启动Bigdata的ggsci
bigdata_ggsci
2.创建目录
create subdirs
3.配置kafka相关参数
1) 配置custom_kafka_producer.properties
在dirprm目录下编辑文件custom_kafka_producer.properties,如果没有可以新建一个。
bootstrap.servers=hadoop01:9092,hadoop02:9092,hadoop03:9092
acks=1
compression.type=gzip
reconnect.backoff.ms=1000
value.serializer=org.apache.kafka.common.serialization.ByteArraySerializer
key.serializer=org.apache.kafka.common.serialization.ByteArraySerializer
batch.size=102400
linger.ms=10000
2) 配置kafka.props
kafka.props用户配置写入Kafka的topic、数据格式、日志打印等等。这里只给出一个可用的简单示例,更多配置可参考OGG for bigdata 官方文档。
在dirrpm目录下编辑文件kafka.props,如果没有可以新建一个。
gg.handlerlist=kafkahandler
gg.handler.kafkahandler.type=kafka
gg.handler.kafkahandler.KafkaProducerConfigFile=custom_kafka_producer.properties
#gg.handler.kafkahandler.TopicName=oggtb01
gg.handler.kafkahandler.topicMappingTemplate=oggtb01
gg.handler.kafkahandler.format=avro_op
gg.handler.kafkahandler.format=delimitedtext
gg.handler.kafkahandler.format.fieldDelimiter=|
gg.handler.kafkahandler.SchemaTopicName=oggtb01
gg.handler.kafkahandler.BlockingSend=false
gg.handler.kafkahandler.includeTokens=false
gg.handler.kafkahandler.mode=op
goldengate.userexit.timestamp=utc
goldengate.userexit.writers=javawriter
javawriter.stats.display=TRUE
javawriter.stats.full=TRUE
gg.log=log4j
gg.log.level=INFO
gg.report.time=30sec
gg.classpath=/usr/local/kafka/libs/*
javawriter.bootoptions=-Xmx512m -Xms32m -Djava.class.path=ggjava/ggjava.jar
4.配置并启动MGR
edit param mgr
PORT 6809
DYNAMICPORTLIST 6810-6909
AUTORESTART EXTRACT *,RETRIES 5,WAITMINUTES 3
PURGEOLDEXTRACTS ./dirdat/*,USECHECKPOINTS, MINKEEPDAYS 3
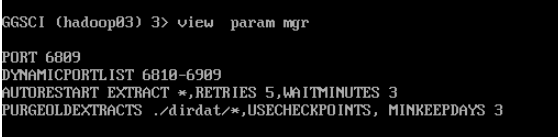
--查看MGR参数配置
view param mgr
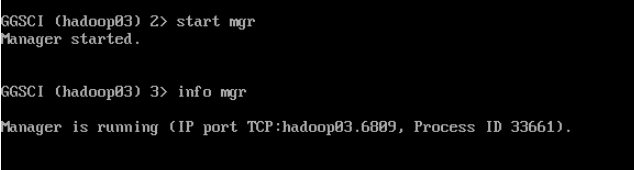
--启动MGR
start mgr
--查看MGR状态
Info mgr
5.回放(Replicat)进程配置
--添加/编辑回放进程配置文件
edit params mqkafka2
这里mqkafka为replicat进程名称,用户可任意定义。
REPLICAT mqkafka2
TARGETDB LIBFILE libggjava.so SET property=dirprm/kafka.props
REPORTCOUNT EVERY 1 MINUTES, RATE
GROUPTRANSOPS 10000
cachemgr cachesize 1G
##container mem_limit 8G
MAP public.tb01, TARGET public.tb01;
--添加进程
add replicat mqkafka2, exttrail ./dirdat/g1

--启动mqkafka2
start mqkafka2
--查看回放进程信息
Info mqkafka2
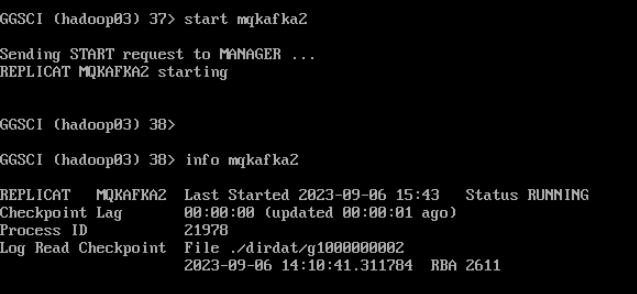
--查看回放进程统计信息
stats mqkafka2,total
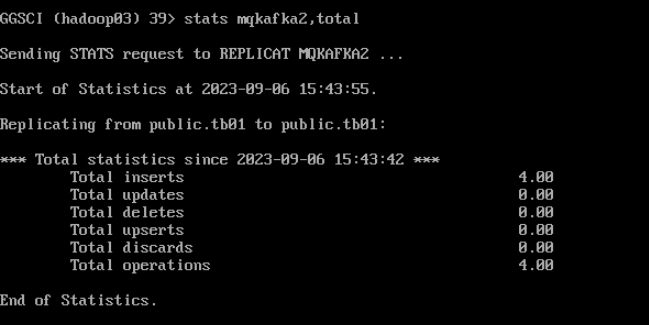
(六)测试验证
(1)PostgreSQL中插入数据
--登录PostgreSQL数据库
psql
--进入testpdb数据库
\c testpdb
--插入数据
insert into tb01 values(2001,'lgb',now()),(2002,'tom',now()),(2003,'alice',now());
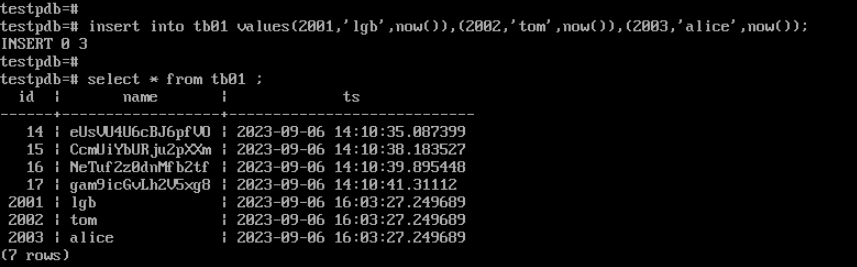
(2)PostgreSQL中更新数据
--更新tb01表中的时间
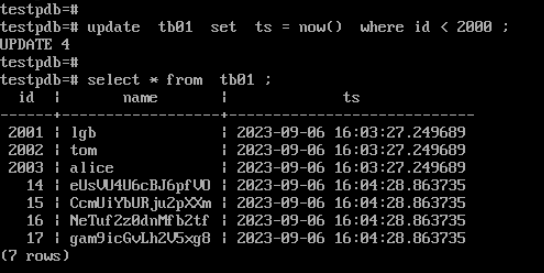
update tb01 set ts = now() where id < 2000 ;
--查询变更后的时间
select * from tb01 ;
(3)PostgreSQL中删除数据
--删除表中数据
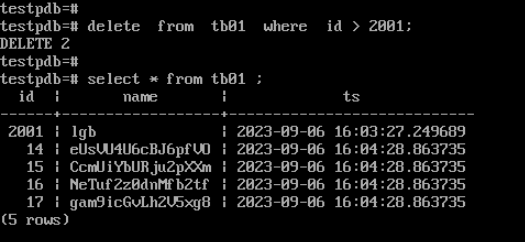
delete from tb01 where id > 2001;
--查询表中数据
select * from tb01 ;
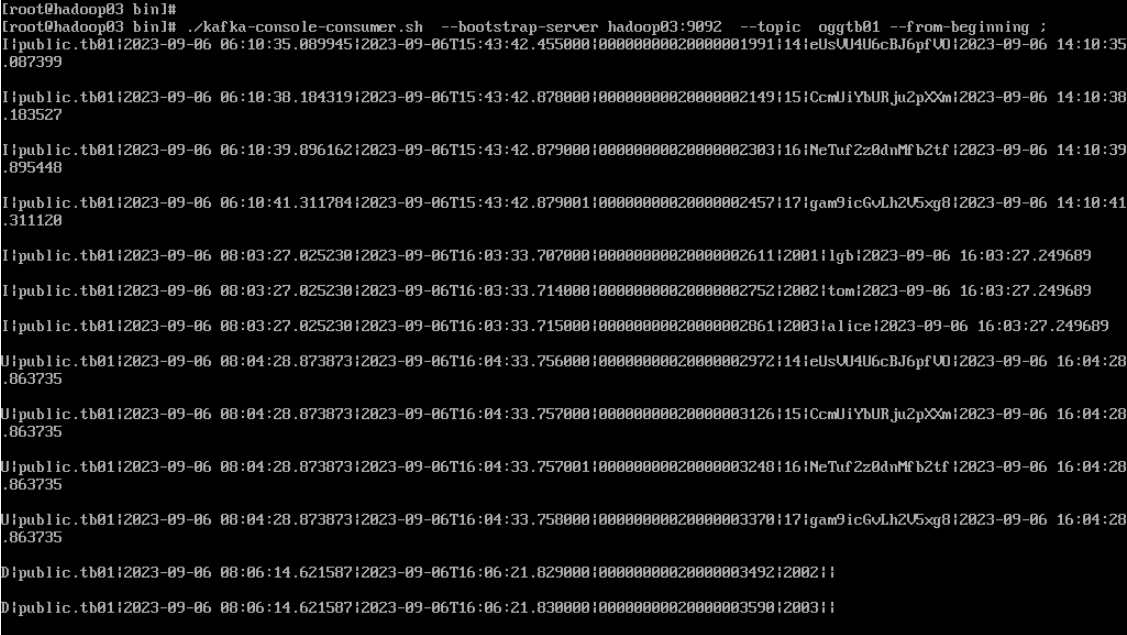
(4)Kafka查看消费消息
--启动Consumer,并订阅我们上面创建的Topic中生产的消息:
./kafka-console-consumer.sh --bootstrap-server hadoop03:9092 --topic oggtb01 ;
(七)常用命令总结
--查看所有OGG进程
info all
--查看某个OGG进程
info 进程名
info 进程名 detail
--管理OGG进程
start/stop/delete 进程名
--查看进程日志报告
view report 进程名
--修改进程参数
edit params 进程名
--修改全局参数
edit params ./GLOBAL
--查看统计信息,列出处理的所有记录数
stats 进程名,total
--查看详细处理过的事务记录
info 进程名 showch
--查看进程中最长的10个交易
send extract 进程名 ,showtrans thread 1 count 10
--查看当前GoldenGate环境信息
show
--历史命令
history
--执行本地shell
shell ls
--查看告警日志信息
view ggsevt
--查看延时,以及文件抽取应用情况
lag 进程名
OGG-Postgres实时同步到Kafka的更多相关文章
- 将postgresql中的数据实时同步到kafka中
参考地址:https://blog.csdn.net/weixin_33985507/article/details/92460419 参考地址:https://mp.weixin.qq.com/s/ ...
- 基于OGG的Oracle与Hadoop集群准实时同步介绍
版权声明:本文由王亮原创文章,转载请注明出处: 文章原文链接:https://www.qcloud.com/community/article/220 来源:腾云阁 https://www.qclou ...
- 几篇关于MySQL数据同步到Elasticsearch的文章---第一篇:Debezium实现Mysql到Elasticsearch高效实时同步
文章转载自: https://mp.weixin.qq.com/s?__biz=MzI2NDY1MTA3OQ==&mid=2247484358&idx=1&sn=3a78347 ...
- MySQL数据实时增量同步到Kafka - Flume
转载自:https://www.cnblogs.com/yucy/p/7845105.html MySQL数据实时增量同步到Kafka - Flume 写在前面的话 需求,将MySQL里的数据实时 ...
- MongoDB -> kafka 高性能实时同步(采集)mongodb数据到kafka解决方案
写这篇博客的目的 让更多的人了解 阿里开源的MongoShake可以很好满足mongodb到kafka高性能高可用实时同步需求(项目地址:https://github.com/alibaba/Mong ...
- 基于Canal和Kafka实现MySQL的Binlog近实时同步
前提 近段时间,业务系统架构基本完备,数据层面的建设比较薄弱,因为笔者目前工作重心在于搭建一个小型的数据平台.优先级比较高的一个任务就是需要近实时同步业务系统的数据(包括保存.更新或者软删除)到一个另 ...
- MongoDB -> kafka 高性能实时同步(sync 采集)mongodb数据到kafka解决方案
写这篇博客的目的 让更多的人了解 阿里开源的MongoShake可以很好满足mongodb到kafka高性能高可用实时同步需求(项目地址:https://github.com/alibaba/Mong ...
- Mysql数据实时同步
企业运维的数据库最常见的是 mysql;但是 mysql 有个缺陷:当数据量达到千万条的时候,mysql 的相关操作会变的非常迟缓; 如果这个时候有需求需要实时展示数据;对于 mysql 来说是一种灾 ...
- mysql数据实时同步到Elasticsearch
业务需要把mysql的数据实时同步到ES,实现低延迟的检索到ES中的数据或者进行其它数据分析处理.本文给出以同步mysql binlog的方式实时同步数据到ES的思路, 实践并验证该方式的可行性,以供 ...
- SQLServer数据实时同步PostgreSQL
SQLServer数据实时同步至PostgreSQL 前言: 为迎合工作需求有时候传送的数据保存在SQLServer中但由于工作需要需要保存到PostgreSQL中进行处理,本文主要通过在SQLSer ...
随机推荐
- Abstract Factory Pattern 抽象工厂模式简介与 C# 示例【创建型】【设计模式来了】
〇.简介 1.什么是抽象工厂模式? 一句话解释: 通过对抽象类和抽象工厂的一组实现,独立出一系列新的操作,客户端无需了解其逻辑直接访问. 抽象工厂模式(Abstract Factory Patte ...
- HttpURLConnection调用webservice,c#、java、python等HTTP调用webservice,简单的webservice调用
以前调用webservice一般使用axis.axis2先生成java类后,直接引用,多方便.但是有的webservice接口非常的函数,生成的java类非常多,有没有一种非常简化的方法. axis2 ...
- c# 如何将枚举以下拉数据源的形式返回给前端
前言: 相信各位有碰到过与我类似的问题,当表中存一些状态的字段,无非以下几种形式1.直接写死 如: 正常:1,异常:2 ,还有一种则是写在字典中,再或者就是加在枚举上,前两者对于返回下拉数据源来说比较 ...
- 【python基础】类-初识类
1.面向对象思想 在认识类之前,我们需要理解面向对象思想和面向过程思想. 面向过程思想:要拥有一间房屋,面向过程像是自己来修盖房屋,如果需要经过选址.购买材料.砌墙.装修等步骤,面向过程编程,就相当于 ...
- Kubernetes(k8s) Web-UI界面(一):部署和访问仪表板(Dashboard)
目录 一.系统环境 二.前言 三.仪表板(Dashboard)简介 四.部署Kubernetes仪表板(Dashboard) 五.访问Kubernetes仪表板(Dashboard) 5.1 使用to ...
- Linux相关概念及操作
目录 linux的文件系统是采用级层式的树状目录结构,在此结构中的最上层是根目录"/",然后在此目录下再创建其他的目录. 1./bin 是Binary的缩写,这个目录存放着最经常使 ...
- Python爬虫突破验证码技巧 - 2Captcha
在互联网世界中,验证码作为一种防止机器人访问的工具,是爬虫最常遇到的阻碍.验证码的类型众多,从简单的数字.字母验证码,到复杂的图像识别验证码,再到更为高级的交互式验证码,每一种都有其独特的识别方法和应 ...
- maven项目创建后添加resources等文件夹
maven项目初始化只生成src/main/resources目录,但是这个不够用,我们得创建 src/main/java目录 src/test/java目录 src/test/resources目录 ...
- 【原创】Ftrace使用及实现机制
Ftrace使用及实现机制 版权声明:本文为本文为博主原创文章,转载请注明出处 https://www.cnblogs.com/wsg1100 如有错误,欢迎指正. 目录 Ftrace使用及实现机制 ...
- [CF 1780B] GCD Partition
B. GCD Partition 题意 : 给一个长度为n的序列, 并将其分成连续的k块(k > 1), 得到序列b, 使得 \(gcd(b_{1}, b_{2}, b_{3}, ..., b_ ...