Redis实战解读-初识Redis&Redis基本数据类型
Redis实战解读
一.初识Redis
1.什么是Redis
Redis是一个速度非常快的非关系型数据库(non-relational database),它可以存储键(key)与五种不同类型的值的映射(mapping),可以将存储在内存的键值对数据持久化到磁盘,可以使用复制特性来扩展读性能,也可以采用客户端分片来扩展写性能。--《Redis实战》
2.Redis与其他数据库的对比
与memcached对比:Redis能够存储包括字符串类型的共计五种数据类型的键值,而memcached只能存储普通的字符串类型的键值。
二.Redis中的数据结构
Redis支持String(字符串),List(列表),Set(集合),Hash(散列),Zset(有序集合)共计五种数据类型以存储键值,接下来,我们将分别去讨论这五种数据类型
(我们将在Linux系统进行演示,如何在Linux系统上安装并运行Redis,请参照https://redis.io/docs/getting-started/installation/install-redis-on-linux/)
1.String(字符串)
字符串的内容可以是字符串,整数或者是浮点数,因此,字符串可以进行字符串相关的操作,以及数值型的自加自减操作。
相当于其他数据类型而言,字符串类型的内容较为简单,这里以代码过之。
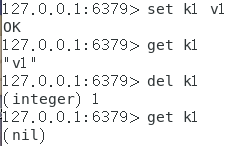
相关方法说明:
向数据库中添加一个key-value: set key value
获取数据库中指定key的value: get key
删除数据库中指定的key: del key
2.List(列表)
Redis中的链表结构能够顺序存储多个字符串,其中,链表中的每一个节点均代表着一个字符串
代码演示:
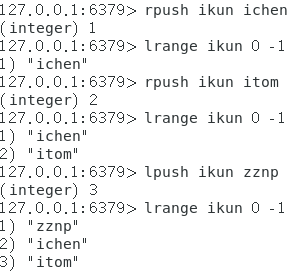
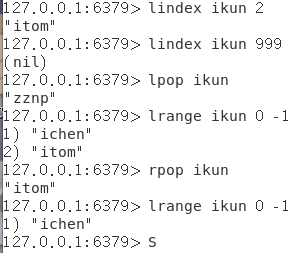
相关方法说明:
rpush key value:从左侧向key对应的链表插入一个value元素,并返回添加的元素的value值
lpush key value:从右侧向key对应的链表插入一个value元素,并返回添加的元素的value值
rpop key:从左侧删除key对应的链表的一个元素,并返回删除的元素的value值
lpop key:从右侧删除key对应的链表的一个元素,并返回删除的元素的value值
lindex key index :获取列表上指定(从右侧数)index处的元素的value值
lrange key startIndex endIndex:获取从startIndex索引到endIndex索引之间(即[startIndex,endIndex]区间上的元素)的元素的元素值
注意:当startIndex = 0,endIndex = -1,则表示获取整个链表内的所有元素。
index是从0开始计数。
3.Set(集合)
与List数据类型不同的是,Set不能存储多个相同的字符串值,也就是说,其存储的元素值具有唯一性,此外,其存储顺序也是不定的,即元素存储的顺序与插入顺序没有关系。

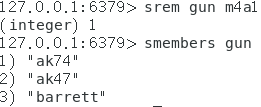
相关方法说明:
sadd key value : 向指定key的集合中添加一个值为value的元素,成功返回1,失败返回0
srem key value : 向指定key的集合中删除一个值为value的元素,成功返回1,失败返回0
smembers key : 获取指定key的集合中的全部元素
sismember key value :确定指定元素value是否存在于key的集合中,存在则返回1,不存在则返回0
4.Hash(散列)
Redis中的散列用于存储多个键值对之间的映射,类似于Java中的Map数据类型。


相关方法说明:
hset key sub_key sub_value : 向指定key的集合中添加 sub_key 与sub_value的键值映射,插入成功返回1,失败返回0
hget key sub_key : 获取指定key的集合中的sub_key对应的值,存在sub_key的关系映射,则返回相对应的值,不存在返回nil
hdel key sub_key : 删除指定key的集合中的sub_key的键值映射
hgetall key : 获取指定key集合中的全部键值映射,注意:结果是以key1,value1,key2,value2,.......交替展示
5.Zset(有序集合)
与Set一样,该种数据类型也是用于存储唯一性的键值的,与前者不同的是,后者在键值的基础上还添加了一个与之绑定的分数值(score),因此你可以依据score值去获取相应的value值,并且也可以查询指定score范围内的相对应的key值。

相关方法说明:
zadd key score item : 向指定key的有序集合中添加一个分数为score 的item元素,插入成功返回1,失败返回0
zrem key item : 删除指定key的有序集合中的指定item元素,删除成功返回1,失败返回0
zrange key startIndex endIndex [withscores] : 获取指定key的有序集合中的索引介于起始索引startIndex与结束索引endIndex之间的元素,添加withscores则返回的结果中为item与score的交替展示
zrangebyscore key minScore maxScore [withscores]: 获取指定key的有序集合中的分数值介于minScore与maxScore之间的元素值,添加withscores则返回的结果中为item与score的交替展示
Redis实战解读-初识Redis&Redis基本数据类型的更多相关文章
- Redis实战(一)Redis简介及环境安装(Windows)
提到Redis,大家肯定都听过,并且应该都在项目中或多或少的使用过,也许你觉得Redis用起来挺简单的呀,但如果有人问你下面的几个问题(比如同事或者面试官),你能回答的上来吗? 什么是Redis? R ...
- Redis实战(九)Redis的典型应用场景
序言 数据缓存 共享Session 分布式锁 https://www.cnblogs.com/wangrudong003/p/10627539.html Redlock(redis分布式锁)原理分析 ...
- Linux+Redis实战教程_day02_2、redis简述及安装与启动
2. redis简述及安装 关系型数据库(SQL): Mysql,oracle 特点:数据和数据之间,表和字段之间,表和表之间是存在关系的 例如:部门表 001部门, 员工表 001 用户表,用户 ...
- Redis实战(七)Redis开发与运维
Redis用途 1.缓存 Redis提供了键值过期时间设置, 并且也提供了灵活控制最大内存和内存溢出后的淘汰策略. 可以这么说, 一个合理的缓存设计能够为一个网站的稳定保驾护航. 2.排行榜系统 Re ...
- Redis实战(十一)Redis面试题
序言 单线程的redis为什么这么快? 1.纯内存操作不需要进行磁盘的 IO 2.单线程操作避免了频繁上下文切换 3.采用非阻塞的多路I/O复用模型 什么是路I/O复用模型? 核心是监听socket, ...
- Redis实战(三)Redis冷备如何做
Redis 的 RDB 持久化方案,相信大家都有所了解,但是对于企业来说,如果只是持久化了一个 RDB 文件,不足以应付生产级别的事故.通常的方案就是对 RDB 进行多个备份,今天带大家来真枪实弹操作 ...
- Redis实战(二)Redis 的 RDB 配置和数据恢复
RDB 配置解释 在 redis.conf 文件中,默认有 RDB 持久化配置: save 900 1 save 300 10 save 60 10000复制复制失败复制成功 解释: 这些配置称为检查 ...
- Linux+Redis实战教程_day02_3、redis数据类型_4、String命令_5、hash命令_6、java操作redis数据库技术
3. redis数据类型[重点] redis 使用的是键值对保存数据.(map) key:全部都是字符串 value:有五种数据类型 Key名:自定义,key名不要过长,否则影响使用效率 Key名不要 ...
- Redis实战(十三)Redis的三种集群方式
序言 能聊聊redis cluster集群模式的原理吗 资料 https://www.cnblogs.com/51life/p/10233340.html Redis 集群分片原理
- Redis实战(十)Redis常见问题及解决方案
序言
随机推荐
- 操作kubernets(k8s)的增删改查
资源的CRUD: 创建: Service service = client.services().inNamespace(namespace).create(service); 更新: Namespa ...
- python selenium 操作文件上传,并发操作时,文件选择窗口混乱解决方案
上传文件 使用的是 python + autoit 模块,这种方式有一个问题,当出现多条任务同时选择文件上传的时候,无法判断那个文件选择窗口的归属,从而出现上传了错误的文件! 解决方法: 要上载文件而 ...
- ssh基于主机名访问
登录一台服务器我们可以用ssh user@IP这种方式 还有一种快捷的方式,就是基于主机名访问,这需要先配置 /etc/hosts文件 假如我们又两台主机 192.168.75.131/165 分别为 ...
- 自己动手从零写桌面操作系统GrapeOS系列教程——12.QEMU+GDB调试
学习操作系统原理最好的方法是自己写一个简单的操作系统. 写程序不免需要调试,写不同的程序调试方式也不同.如果做应用软件开发,相应的程序调试方式是建立在有操作系统支持的基础上的.而我们现在是要开发操作系 ...
- MATLAB信号处理常用函数(转载)
https://shimo.im/docs/YyRXY8cQdqY8RJvc/ <MATLAB信号处理工具箱>,可复制链接后用石墨文档 App 或小程序打开 嗯这个肯定是随便看看,有个印象 ...
- Go 语言:如何利用好 TDD 学习指针并了解 Golang 中的 error 处理
我们在上一节中学习了结构体(structs),Go语言:利用 TDD 驱动开发测试 学习结构体.方法和接口 它可以组合与一个概念相关的一系列值. 你有时可能想用结构体来管理状态,通过将方法暴露给用户的 ...
- Django笔记五之字段类型
这篇笔记介绍字段的类型 Field Type. Django 的model 下的 field 对应的是 MySQL 中的表字段,而我们定义的 field 的类型则对应 MySQL 中的字段类型. 本次 ...
- Docker 基础及安装
目录 一.简介 二.Docker的基本组成 三.Docker的安装 四.配置国内阿里云镜像加速 五.Hello World 上手实践 六.Docker底层原理 更多内容,前往 IT-BLOG 一.简介 ...
- ZGC 最新一代垃圾回收器[NO]
ZGC(The Z Garbage Collector)是JDK 11中推出的一款低延迟垃圾回收器,ZGC可以说源自于 Azul System 公司开发的C4收集器[基本不用调优]它的设计目标包括: ...
- 制作一个同时具有PE和Windows原版安装方式的U盘
这个方法可能很多人已经制作成功过了,但是呢,也有些人不会的,也可能没想到过,那就是让Win PE与Windows原版安装包在一个U盘里面同时共存. 需要用到的软件有这几样:DiskGenius.Gim ...