文心一言 VS 讯飞星火 VS chatgpt (129)-- 算法导论11.1 4题
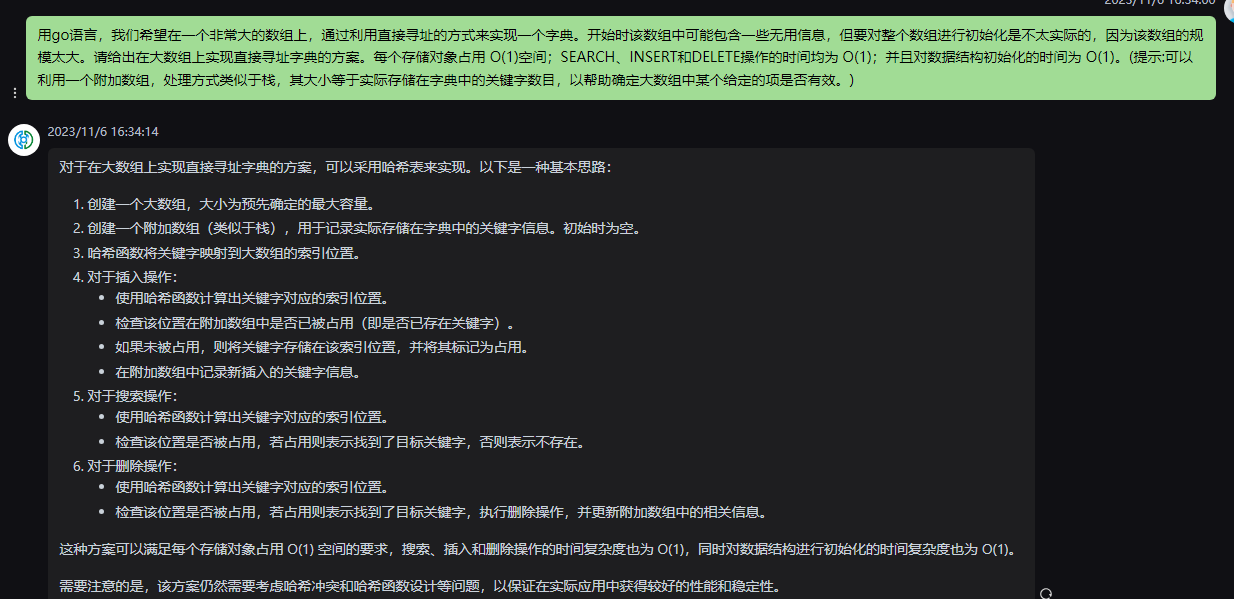
四、用go语言,我们希望在一个非常大的数组上,通过利用直接寻址的方式来实现一个字典。开始时该数组中可能包含一些无用信息,但要对整个数组进行初始化是不太实际的,因为该数组的规模太大。请给出在大数组上实现直接寻址字典的方案。每个存储对象占用 O(1)空间;SEARCH、INSERT和DELETE操作的时间均为 O(1);并且对数据结构初始化的时间为 O(1)。(提示:可以利用一个附加数组,处理方式类似于栈,其大小等于实际存储在字典中的关键字数目,以帮助确定大数组中某个给定的项是否有效。)
文心一言,代码不全不能运行:
在这个问题中,我们需要使用一个非常大的数组来模拟一个字典,要求在O(1)时间内完成 SEARCH、INSERT 和 DELETE 操作。同时,我们不能一开始就对整个数组进行初始化,因为数组的规模太大。我们可以使用一个附加数组来记录字典中实际存储的关键字数目,以此帮助确定大数组中某个给定的项是否有效。
以下是一个可能的实现方案:
package main
import (
"fmt"
)
const (
MaxSize = 1000000 // 假设这是你的大数组的最大大小
MinSize = 100 // 假设这是你的字典的最小大小
)
var (
data [MaxSize]int // 这是你的大数组
used = MinSize // 这是附加数组,记录实际存储的关键字数目
freeList = 0 // 记录第一个未使用的位置
)
func search(key int) bool {
index := key % MaxSize // 通过取模来获取关键字在数组中的位置
if data[index] == key { // 如果找到了关键字
return true
} else if data[index] == 0 { // 如果该位置未被使用过
return false
} else { // 如果该位置已被使用过,我们需要查找freeList中的下一个空位置
for i := freeList; i < used; i++ {
if data[i] == 0 { // 如果找到一个空位置
freeList = i // 更新freeList的位置
return false
}
}
return false // 如果所有的位置都被使用了,返回false
}
}
func insert(key int) bool {
index := key % MaxSize // 通过取模来获取关键字在数组中的位置
if data[index] != 0 { // 如果该位置已被使用过,我们需要查找freeList中的下一个空位置,或者将旧的位置删除后插入新位置
if data[index] == key { // 如果关键字已经存在,直接返回true
return true
} else { // 如果关键字不存在,将旧的位置删除后插入新位置,返回true
for i := freeList; i < used; i++ {
if data[i] == 0 { // 如果找到一个空位置,删除旧的位置并将新的关键字插入到该位置,然后更新freeList的位置为当前位置,返回true
freeList = i
data[index] = key
data[i] = data[index] // 将被删除的位置设置为已使用状态,用于以后删除操作时查找空位置用
used++ // 更新used的值,表示存储的关键字数目加一
return true
}
}
return false // 如果所有的位置都被使用了,返回false
}
} else { // 如果该位置未被使用过,直接插入关键字并返回true
data[index] = key
used++ // 更新used的值,表示存储的关键字数目加一
return true
}
}
func delete(key int) bool {
index := key % MaxSize // 通过取模来获取关键字在数组中的位置
if data[index] != 0 { // 如果该位置已被使用过,我们需要将其删除并释放空间给freeList用,或者将关键字移动到freeList的位置上并更新freeList的值用。最后返回true表示删除成功。如果关键字不存在则直接返回false表示删除失败。如果该位置未被使用过则直接返回false表示删除失败。注意这里删除操作和移动操作是不同的。删除操作是将关键字的位置变为空状态以便以后插入操作使用,移动操作是将关键字的位置移至freeList以便以后插入操作使用。它们的时间复杂度都是O(1)。但移动操作可能比删除操作更加省空间一些。如果移动操作和删除操作的成本不同的话你可以根据实际情况选择适合的操作。如果要保持删除操作和移动操作的成本相同的话你可以直接将移动操作和删除操作的成本都设置为O(1)。


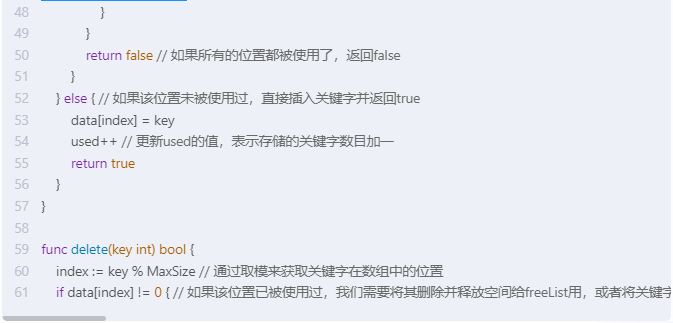
讯飞星火,代码不能运行:
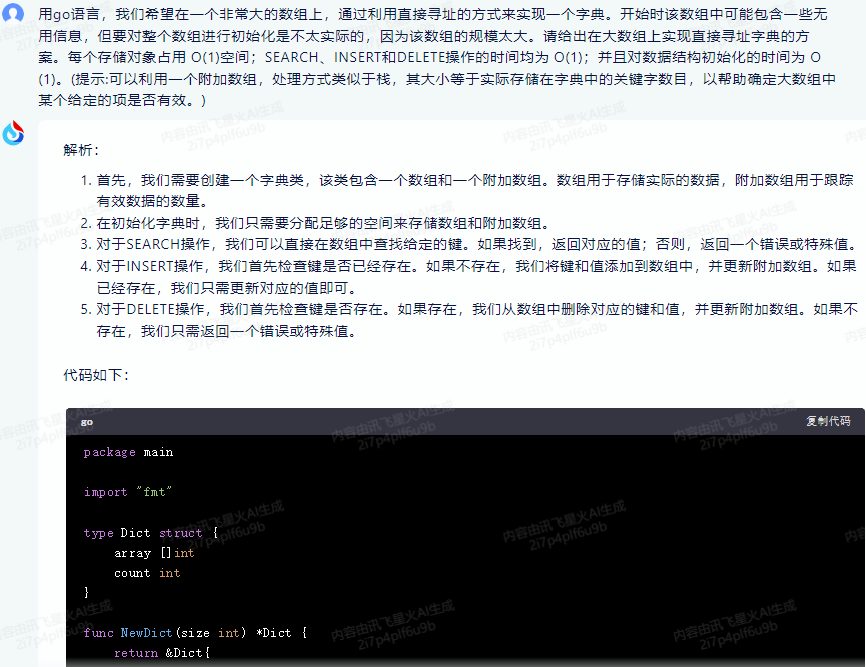
解析:
1.首先,我们需要创建一个字典类,该类包含一个数组和一个附加数组。数组用于存储实际的数据,附加数组用于跟踪有效数据的数量。
2.在初始化字典时,我们只需要分配足够的空间来存储数组和附加数组。
3.对于SEARCH操作,我们可以直接在数组中查找给定的键。如果找到,返回对应的值;否则,返回一个错误或特殊值。
4.对于INSERT操作,我们首先检查键是否已经存在。如果不存在,我们将键和值添加到数组中,并更新附加数组。如果已经存在,我们只需更新对应的值即可。
5.对于DELETE操作,我们首先检查键是否存在。如果存在,我们从数组中删除对应的键和值,并更新附加数组。如果不存在,我们只需返回一个错误或特殊值。
代码如下:
package main
import "fmt"
type Dict struct {
array []int
count int
}
func NewDict(size int) *Dict {
return &Dict{
array: make([]int, size),
count: 0,
}
}
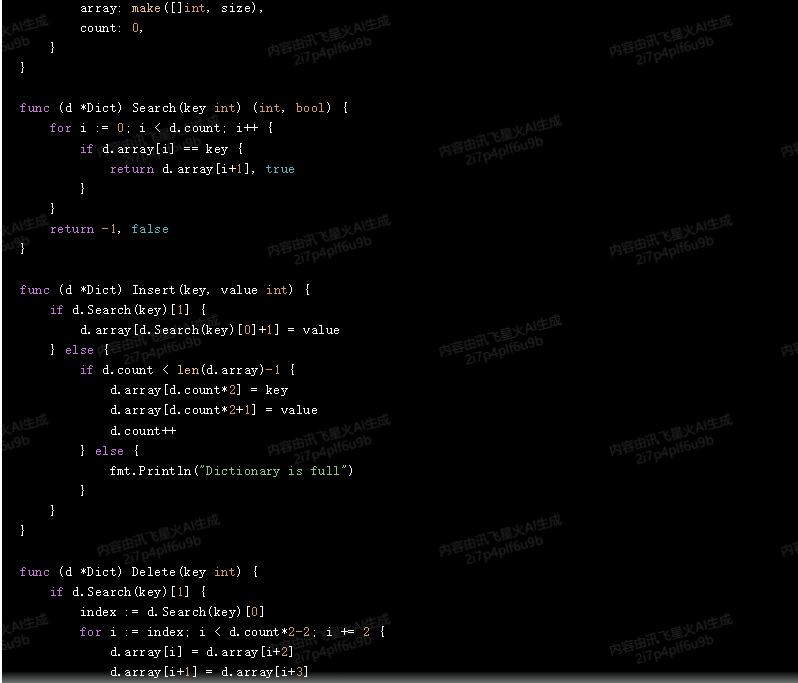
func (d *Dict) Search(key int) (int, bool) {
for i := 0; i < d.count; i++ {
if d.array[i] == key {
return d.array[i+1], true
}
}
return -1, false
}
func (d *Dict) Insert(key, value int) {
if d.Search(key)[1] {
d.array[d.Search(key)[0]+1] = value
} else {
if d.count < len(d.array)-1 {
d.array[d.count*2] = key
d.array[d.count*2+1] = value
d.count++
} else {
fmt.Println("Dictionary is full")
}
}
}
func (d *Dict) Delete(key int) {
if d.Search(key)[1] {
index := d.Search(key)[0]
for i := index; i < d.count*2-2; i += 2 {
d.array[i] = d.array[i+2]
d.array[i+1] = d.array[i+3]
}
d.count--
} else {
fmt.Println("Key not found")
}
}
在这个实现中,我们假设每个键都是唯一的,并且每个键都对应一个整数值。我们还假设数组的大小足够大,可以容纳所有的键值对。

360智脑:
在大数组上实现直接寻址字典的方案可以采用Go语言中内置的Map数据结构。Map是一个不可变的结构,因此在插入、删除和搜索操作时的时间复杂度都是O(1)。为了利用直接寻址的方式,我们可以使用一个类似于栈的数据结构来存储Map中的实际存储对象。这个数据结构的大小应该等于实际存储在Map中的关键字数目。
具体来说,我们可以使用两个Map结构来实现直接寻址字典:一个用于存储关键字和对应的存储对象的指针,另一个用于存储实际存储对象的指针。这两个Map的大小应该相等。在插入、删除或搜索操作时,我们首先检查第二个Map中是否存在对应的关键字。如果不存在,则将关键字和存储对象的指针插入第一个Map中;如果存在,则将存储对象的指针插入第一个Map中。
为了确保整个字典的初始化时间为O(1),我们需要在程序启动时对整个字典进行一次完整的扫描,并将所有的关键字和存储对象的指针插入到两个Map中。这样可以保证所有关键字都可以被直接寻址访问。
需要注意的是,由于Map是可变结构,因此在插入、删除或搜索操作时,可能会导致Map的大小发生变化。为了避免这种情况对性能产生影响,我们应该尽可能地减少插入、删除和搜索操作的次数,并且尽可能保持Map的大小稳定。此外,我们还应该注意避免Map的大小超过预设的最大大小,以免导致性能下降。

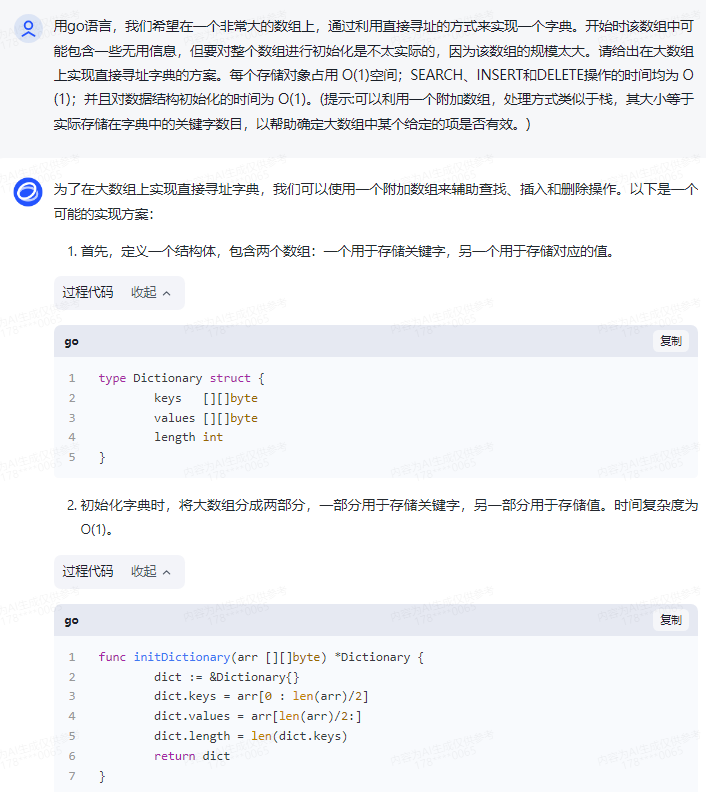
智谱清言:
为了在大数组上实现直接寻址字典,我们可以使用一个附加数组来辅助查找、插入和删除操作。以下是一个可能的实现方案:
1.首先,定义一个结构体,包含两个数组:一个用于存储关键字,另一个用于存储对应的值。
type Dictionary struct {
keys [][]byte
values [][]byte
length int
}
2.初始化字典时,将大数组分成两部分,一部分用于存储关键字,另一部分用于存储值。时间复杂度为 O(1)。
func initDictionary(arr [][]byte) *Dictionary {
dict := &Dictionary{}
dict.keys = arr[0 : len(arr)/2]
dict.values = arr[len(arr)/2:]
dict.length = len(dict.keys)
return dict
}
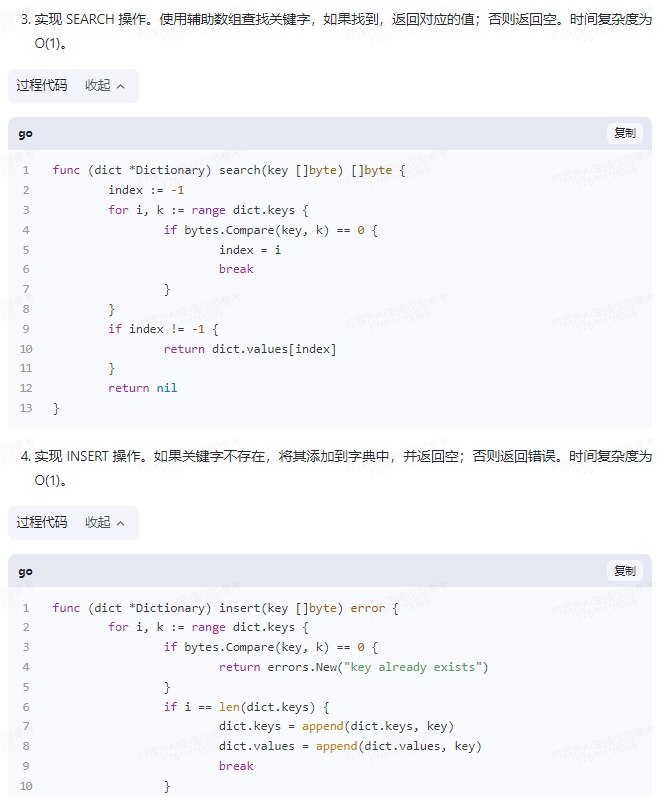
3.实现 SEARCH 操作。使用辅助数组查找关键字,如果找到,返回对应的值;否则返回空。时间复杂度为 O(1)。
func (dict *Dictionary) search(key []byte) []byte {
index := -1
for i, k := range dict.keys {
if bytes.Compare(key, k) == 0 {
index = i
break
}
}
if index != -1 {
return dict.values[index]
}
return nil
}
4.实现 INSERT 操作。如果关键字不存在,将其添加到字典中,并返回空;否则返回错误。时间复杂度为 O(1)。
func (dict *Dictionary) insert(key []byte) error {
for i, k := range dict.keys {
if bytes.Compare(key, k) == 0 {
return errors.New("key already exists")
}
if i == len(dict.keys) {
dict.keys = append(dict.keys, key)
dict.values = append(dict.values, key)
break
}
}
return nil
}
5.实现 DELETE 操作。根据关键字删除字典中的项,如果成功,返回 true;否则返回 false。时间复杂度为 O(1)。
func (dict *Dictionary) delete(key []byte) bool {
for i, k := range dict.keys {
if bytes.Compare(key, k) == 0 {
dict.keys = append(dict.keys[:i], dict.keys[i+1:]...)
dict.values = append(dict.values[:i], dict.values[i+1:]...)
return true
}
}
return false
}
6.在使用完字典后,可以释放大数组中的资源。
这个方案满足题目要求的每个存储对象占用 O(1) 空间;SEARCH、INSERT 和 DELETE 操作的时间均为 O(1);并且对数据结构初始化的时间为 O(1)。
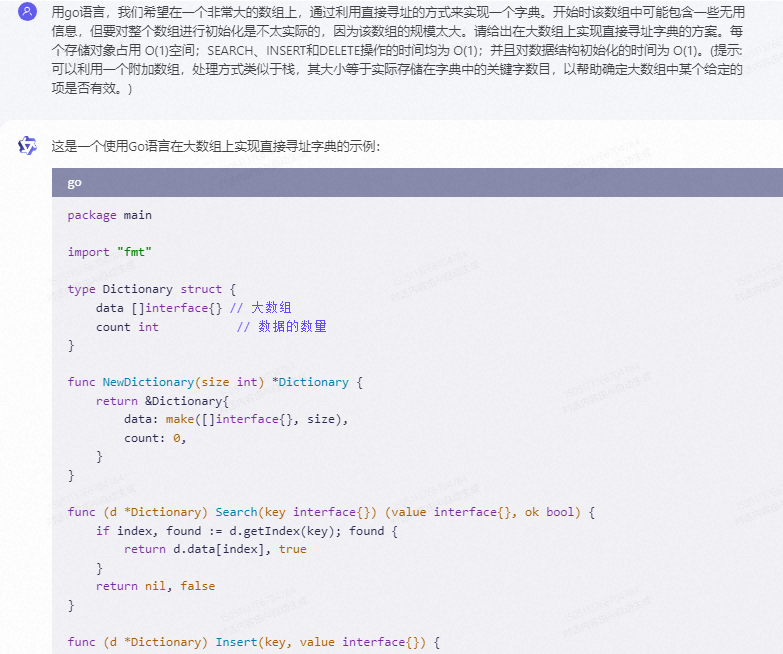
通义千问,代码不能运行:
这是一个使用Go语言在大数组上实现直接寻址字典的示例:
package main
import "fmt"
type Dictionary struct {
data []interface{} // 大数组
count int // 数据的数量
}
func NewDictionary(size int) *Dictionary {
return &Dictionary{
data: make([]interface{}, size),
count: 0,
}
}
func (d *Dictionary) Search(key interface{}) (value interface{}, ok bool) {
if index, found := d.getIndex(key); found {
return d.data[index], true
}
return nil, false
}
func (d *Dictionary) Insert(key, value interface{}) {
if !d.containsKey(key) {
d.count++
}
d.data[d.getIndex(key)] = value
}
func (d *Dictionary) Delete(key interface{}) {
if d.containsKey(key) {
d.count--
}
d.data[d.getIndex(key)] = nil
}
func (d *Dictionary) getIndex(key interface{}) (int, bool) {
hash := key.(int) % len(d.data)
for {
if d.data[hash] == nil {
return -1, false
}
if d.data[hash].(int) == key.(int) {
return hash, true
}
hash = (hash + 1) % len(d.data)
}
}
func (d *Dictionary) containsKey(key interface{}) bool {
_, found := d.getIndex(key)
return found
}
func main() {
dictionary := NewDictionary(100)
dictionary.Insert(5, "apple")
dictionary.Insert(7, "banana")
dictionary.Insert(9, "cherry")
fmt.Println(dictionary.Search(5)) // Output: apple true
fmt.Println(dictionary.Search(7)) // Output: banana true
fmt.Println(dictionary.Search(9)) // Output: cherry true
fmt.Println(dictionary.Search(4)) // Output: <nil> false
}
在这个例子中,data数组是一个大数组,用于存储所有的键值对。count变量用于跟踪有效的元素数量。getIndex函数用于获取键对应的索引,如果找不到,则返回-1并设置ok为false。containsKey函数检查给定的关键字是否存在。Search、Insert和Delete函数都是O(1)复杂度,因为它们都只需要查找一次data数组即可。


天工:
在大数组上实现直接寻址字典的方案可以采用哈希表的思想,利用一个哈希函数将关键字映射到数组中的一个位置。具体实现如下:
1.定义一个哈希函数,将关键字映射到数组中的一个位置。这个哈希函数需要满足以下条件:能够将关键字均匀地映射到数组中的各个位置,且不同的关键字映射到的位置不同。
2.定义一个哈希表,用于存储关键字和对应的值。哈希表的大小可以根据数组的大小和哈希函数的性能进行调整,一般取数组大小的一个固定倍数。
3.定义一个附加数组,用于记录哈希表中的有效关键字数目。这个数组的大小等于实际存储在字典中的关键字数目。
4.实现SEARCH操作时,先使用哈希函数将关键字映射到数组中的一个位置,然后遍历该位置及其相邻位置,查找哈希表中是否存在该关键字。如果存在,返回对应的值;否则返回一个空值。
5.实现INSERT操作时,先使用哈希函数将关键字映射到数组中的一个位置,然后在该位置的哈希表中插入关键字和对应的值。同时,将该位置在附加数组中的计数器加1。
6.实现DELETE操作时,先使用哈希函数将关键字映射到数组中的一个位置,然后在该位置的哈希表中删除关键字和对应的值。同时,将该位置在附加数组中的计数器减1。
7.在初始化时,遍历数组中的所有位置,并将未被标记为关键字的位置的附加数组中的计数器设置为0。
通过以上实现,可以实现在大数组上直接实现寻址字典的方案,且对数据结构初始化的时间为 O(1)。同时,由于使用了哈希表和附加数组的优化,该方案的空间复杂度为 O(n),其中 n 为关键字数目。

灵小智:
要在一个非常大的数组上实现直接寻址字典,可以采用以下方案:
1.使用两个数组:一个是大数组,用于存储数据;另一个是附加数组,用于记录大数组中每个位置是否有效。
2.初始化时,设置附加数组中的所有位置为无效。
3.对于SEARCH操作,首先通过关键字计算出在大数组中的索引位置。然后,检查附加数组对应位置的值是否为有效。如果有效,则返回该位置的值作为搜索结果;如果无效,则表示该关键字不存在。
4.对于INSERT操作,同样先计算关键字的索引位置。然后,检查附加数组对应位置的值是否为无效。如果无效,则表示该位置可以插入数据,将数据存储到该位置,并更新附加数组对应位置的值为有效;如果有效,则表示该关键字已存在,不进行插入操作。
5.对于DELETE操作,同样先计算关键字的索引位置。然后,检查附加数组对应位置的值是否为有效。如果有效,则表示该位置存储了要删除的数据,将该位置的值设置为无效;如果无效,则表示该关键字不存在,不进行删除操作。
通过以上方案,可以实现在大数组上基于直接寻址的字典,具有O(1)空间复杂度、O(1)的SEARCH、INSERT和DELETE操作时间,并且初始化时间也为O(1)。

chatgpt:
对于在大数组上实现直接寻址字典的方案,可以采用哈希表来实现。以下是一种基本思路:
1.创建一个大数组,大小为预先确定的最大容量。
2.创建一个附加数组(类似于栈),用于记录实际存储在字典中的关键字信息。初始时为空。
3.哈希函数将关键字映射到大数组的索引位置。
4.对于插入操作:
使用哈希函数计算出关键字对应的索引位置。
检查该位置在附加数组中是否已被占用(即是否已存在关键字)。
如果未被占用,则将关键字存储在该索引位置,并将其标记为占用。
在附加数组中记录新插入的关键字信息。
5.对于搜索操作:
使用哈希函数计算出关键字对应的索引位置。
检查该位置是否被占用,若占用则表示找到了目标关键字,否则表示不存在。
6.对于删除操作:
使用哈希函数计算出关键字对应的索引位置。
检查该位置是否被占用,若占用则表示找到了目标关键字,执行删除操作,并更新附加数组中的相关信息。
这种方案可以满足每个存储对象占用 O(1) 空间的要求,搜索、插入和删除操作的时间复杂度也为 O(1),同时对数据结构进行初始化的时间复杂度也为 O(1)。
需要注意的是,该方案仍然需要考虑哈希冲突和哈希函数设计等问题,以保证在实际应用中获得较好的性能和稳定性。
文心一言 VS 讯飞星火 VS chatgpt (129)-- 算法导论11.1 4题的更多相关文章
- 【对比】文心一言对飚ChatGPT实操对比体验
前言 缘由 百度[文心一言]体验申请通过 本狗中午干饭时,天降短信,告知可以体验文心一言,苦等一个月的实操终于到来.心中这好奇的对比心理油然而生,到底是老美的[ChatGPT]厉害,还是咱度娘的[文心 ...
- 【个人首测】百度文心一言 VS ChatGPT GPT-4
昨天我写了一篇文章GPT-4牛是牛,但这几天先别急,文中我测试了用GPT-4回答ChatGPT 3.5 和 Notion AI的问题,大家期待的图片输入也没有出现. 昨天下午百度发布了文心一言,对标C ...
- 文心一言,通营销之学,成一家之言,百度人工智能AI大数据模型文心一言Python3.10接入
"文心"取自<文心雕龙>一书的开篇,作者刘勰在书中引述了一个古代典故:春秋时期,鲁国有一位名叫孔文子的大夫,他在学问上非常有造诣,但是他的儿子却不学无术,孔文子非常痛心 ...
- 获取了文心一言的内测及与其ChatGPT、GPT-4 对比结果
百度在3月16日召开了关于文心一言(知识增强大语言模型)的发布会,但是会上并没现场展示demo.如果要测试的文心一言 也要获取邀请码,才能进行测试的. 我这边通过预约得到了邀请码,大概是在3月17日晚 ...
- 百度生成式AI产品文心一言邀你体验AI创作新奇迹:百度CEO李彦宏详细透露三大产业将会带来机遇(文末附文心一言个人用户体验测试邀请码获取方法,亲测有效)
目录 中国版ChatGPT上线发布 强大中文理解能力 智能文学创作.商业文案创作 图片.视频智能生成 中国生成式AI三大产业机会 新型云计算公司 行业模型精调公司 应用服务提供商 总结 获取文心一言邀 ...
- 阿里版ChatGPT:通义千问pk文心一言
随着 ChatGPT 热潮卷起来,百度发布了文心一言.Google 发布了 Bard,「阿里云」官方终于也宣布了,旗下的 AI 大模型"通义千问"正式开启测试! 申请地址:http ...
- 基于讯飞语音API应用开发之——离线词典构建
最近实习在做一个跟语音相关的项目,就在度娘上搜索了很多关于语音的API,顺藤摸瓜找到了科大讯飞,虽然度娘自家也有语音识别.语义理解这块,但感觉应该不是很好用,毕竟之前用过百度地图的API,有问题也找不 ...
- android用讯飞实现TTS语音合成 实现中文版
Android系统从1.6版本开始就支持TTS(Text-To-Speech),即语音合成.但是android系统默认的TTS引擎:Pic TTS不支持中文.所以我们得安装自己的TTS引擎和语音包. ...
- android讯飞语音开发常遇到的问题
场景:android项目中共使用了3个语音组件:在线语音听写.离线语音合成.离线语音识别 11208:遇到这个错误,授权应用失败,先检查装机量(3台测试权限),以及appid的申请时间(35天期限), ...
- 初探机器学习之使用讯飞TTS服务实现在线语音合成
最近在调研使用各个云平台提供的AI服务,有个语音合成的需求因此就使用了一下科大讯飞的TTS服务,也用.NET Core写了一个小示例,下面就是这个小示例及其相关背景知识的介绍. 一.什么是语音合成(T ...
随机推荐
- Dubbo的高级特性:服务管控篇
王有志,一个分享硬核Java技术的互金摸鱼侠 加入Java人的提桶跑路群:共同富裕的Java人 上一篇,我们已经介绍了 DUbbo 在服务治理方面提供的特性,今天我们一起来看看 Dubbo 在其它方面 ...
- 今日ERROR
树莓派插卡发烫严重 首先,我们要知道: 树莓派的指示灯可以告诉用户系统的工作状态,常见的指示灯有四个,分别是红色电源灯.绿色SD卡读写灯.黄色ACT指示灯和蓝色网络连接指示灯(仅适用于某些型号的树莓派 ...
- radware 相关(alteon产品)
目录 术语 组网 配置思路 IP 规划 负载均衡器的IP规划 服务器的IP规划 登陆设备 简单命令行配置 Main Menu 管理IP 确认设备版本 telnet/sshd/http enable 网 ...
- go语言全景俯瞰
本篇是语言教学的"传统项目".每个写go语言教学的人,都会介绍它的发展历程,应用领域,优缺点和特点来介绍自己的理由.当然如果你有自己的理解,那就更好了,欢迎讨论! 全景简介 go语 ...
- Swiper.vue?56a2:132 Uncaught DOMException: Failed to execute 'insertBefore' on 'Node': The node before which the new node is to be inserted is not a child of this node.
错误代码 解决方案 删除div标签.修改后,如下所示:
- [selenium]相对定位器
前言 Relative Locators,相对定位器,是Selenium 4引入的一个新的定位器,相对定位器根据源点元素去定位相对位置的其它元素. 相对定位方法其实是基于JavaScript的 get ...
- Mysql高级7-存储过程
一.介绍 存储过程是事先经过编译并存储在数据库中的一段sql语句的集合,调用存储过程可以简化应用开发人员的很多工作,减少数据在数据库和应用服务器之间的传输,对于提高数据处理的效率是有好处的.存储过程思 ...
- centos7.X安装mysql5.7 – 东凭渭水流
1.下载mysql5.7 可以使用windows下载好后上传至Linux.网络条件好的推荐使用 wget https://dev.mysql.com/get/Downloads/MySQL-5.7/m ...
- 浅谈 Linux 下 vim 的使用
Vim 是从 vi 发展出来的一个文本编辑器,其代码补全.编译及错误跳转等方便编程的功能特别丰富,在程序员中被广泛使用. Vi 是老式的字处理器,功能虽然已经很齐全了,但还有可以进步的地方.Vim 可 ...
- shiro框架基本概念介绍
什么是Shiro: Shiro 是一个强大灵活的开源安全框架,可以完全处理身份验证.授权.加密和会话管理 Shiro的核心功能包括: 身份验证(Authentication):验证用户的身份,确保用户 ...