数据库实践丨MySQL多表join分析
摘要:在数据库查询中,往往会需要查询多个表的数据,比如查询会员信息同时查询关于这个会员的订单信息,如果分语句查询的话,效率会很低,就需要用到join关键字来连表查询了。
Join并行
Join并行1. 多表join介绍2. 多表Join的方式不使用Join buffer使用Join buffer3. Join执行流程(老执行器)
1. 多表join介绍
JOIN子句用于根据两个或多个表之间的相关列来组合它们。 例如:
Orders:

Customers:

SELECT Orders.OrderID, Customers.CustomerName, Orders.OrderDate
FROM Orders
INNER JOIN Customers ON Orders.CustomerID=Customers.CustomerID;

2. 多表Join的方式
Hash join使用新执行器实现,在这里不做讨论
MySQL支持的都是Nested-Loop Join,以及它的变种。
不使用Join buffer
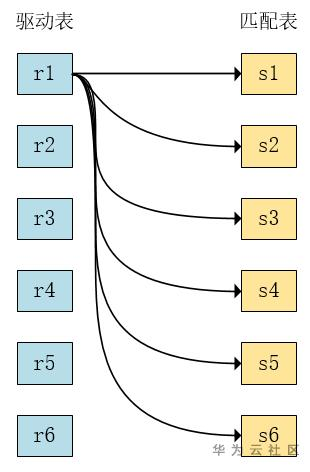
a) Simple Nested-Loop
对r表的每一行,完整扫描s表,根据r[i]-s[i]组成的行去判断是否满足条件,并返回满足条件的结果给客户端。
mysql> show create table t1;
+-------+----------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+-------+----------------------------------------------------------------------------------------------------------------+
| t1 | CREATE TABLE `t1` (
`id` int(11) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci |
+-------+----------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec) mysql> show create table t3;
+-------+--------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+-------+--------------------------------------------------------------------------------------------------------------------+
| t3 | CREATE TABLE `t3` (
`id` int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci |
+-------+--------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec) mysql> explain select /*+ NO_BNL() */ * from t1, t3 where t1.id = t3.id;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | t1 | NULL | ALL | NULL | NULL | NULL | NULL | 2 | 100.00 | NULL |
| 1 | SIMPLE | t3 | NULL | ALL | NULL | NULL | NULL | NULL | 2 | 50.00 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
2 rows in set, 1 warning (0.00 sec)
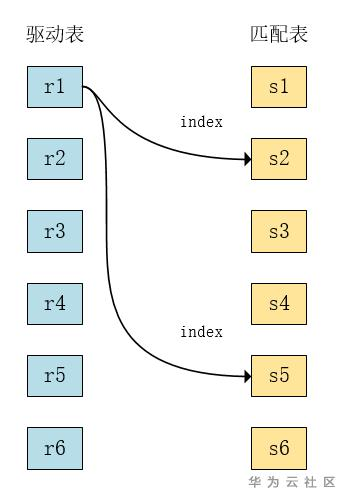
b) Index Nested-Loop
对r表的每一行,先根据连接条件去查询s表索引,然后回表查到匹配的数据,并返回满足条件的结果给客户端。
mysql> show create table t2;
+-------+---------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+-------+---------------------------------------------------------------------------------------------------------------------------------------+
| t2 | CREATE TABLE `t2` (
`id` int(11) NOT NULL,
KEY `index1` (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci |
+-------+---------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec) mysql> explain select * from t1, t2 where t1.id = t2.id;
+----+-------------+-------+------------+------+---------------+--------+---------+------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+--------+---------+------------+------+----------+-------------+
| 1 | SIMPLE | t1 | NULL | ALL | NULL | NULL | NULL | NULL | 2 | 100.00 | NULL |
| 1 | SIMPLE | t2 | NULL | ref | index1 | index1 | 4 | test.t1.id | 1 | 100.00 | Using index |
+----+-------------+-------+------------+------+---------------+--------+---------+------------+------+----------+-------------+
2 rows in set, 1 warning (0.00 sec)
使用Join buffer
a) Block Nested Loop
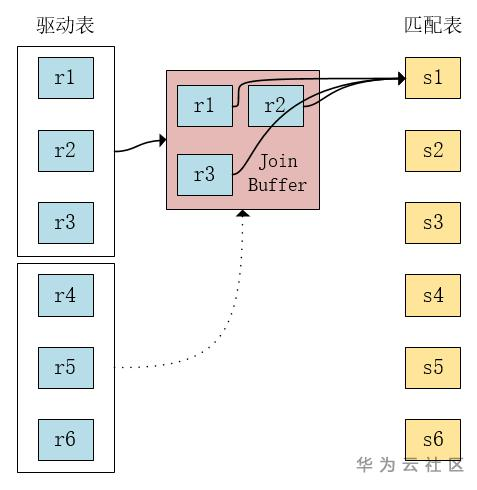
从r表读取一部分数据到join cache中,当r表数据读完或者join cache满后,做join操作。
JOIN_CACHE_BNL::join_matching_records(){
do {
//读取s表的每一行
qep_tab->table()->file->position(qep_tab->table()->record[0]);
//针对s的每一行,遍历join buffer
for(each record in join buffer) {
get_record();
rc = generate_full_extensions(get_curr_rec());
//如果不符合条件,直接返回
if (rc != NESTED_LOOP_OK) return rc;
}
} while(!(error = iterator->Read()))
}
mysql> explain select * from t1, t3 where t1.id = t3.id;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
| 1 | SIMPLE | t1 | NULL | ALL | NULL | NULL | NULL | NULL | 2 | 100.00 | NULL |
| 1 | SIMPLE | t3 | NULL | ALL | NULL | NULL | NULL | NULL | 2 | 50.00 | Using where; Using join buffer (Block Nested Loop) |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
2 rows in set, 1 warning (0.00 sec)
b) Batched Key Access
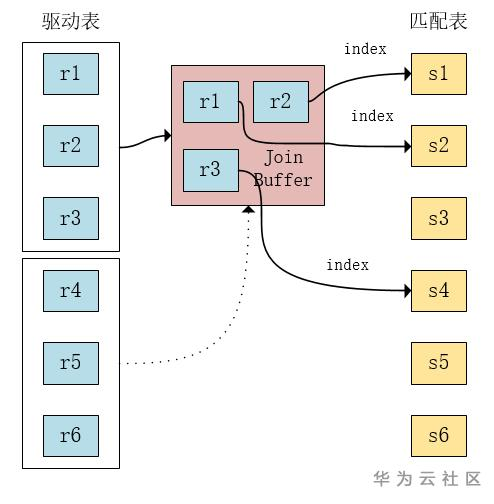
从r表读取一部分数据到join cache中,s表中记录r表被连接的列的值作为索引,查询所有符合条件的索引,然后将这些符合条件的索引排序,然后统一回表查询记录。
其中,对于每一个cached record,都会有一个key,通过这个key去s表扫描所需的数据。
dsmrr_fill_buffer(){
while((rowids_buf_cur < rowids_buf_end) &&
!(res = h2->handler::multi_range_read_next(&range_info))){
//下压的index条件
if (h2->mrr_funcs.skip_index_tuple &&
h2->mrr_funcs.skip_index_tuple(h2->mrr_iter, curr_range->ptr))
continue;
memcpy(rowids_buf_cur, h2->ref, h2->ref_length);
}
varlen_sort(
rowids_buf, rowids_buf_cur, elem_size,
[this](const uchar *a, const uchar *b) { return h->cmp_ref(a, b) < 0; });
}
dsmrr_next(){
do{
if (rowids_buf_cur == rowids_buf_last) {
dsmrr_fill_buffer();
}
// first match
if (h2->mrr_funcs.skip_record &&
h2->mrr_funcs.skip_record(h2->mrr_iter, (char *)cur_range_info, rowid))
continue;
res = h->ha_rnd_pos(table->record[0], rowid);
break;
} while(true);
}
JOIN_CACHE_BKA::join_matching_records(){
while (!(error = file->ha_multi_range_read_next((char **)&rec_ptr))) {
get_record_by_pos(rec_ptr);
rc = generate_full_extensions(rec_ptr);
if (rc != NESTED_LOOP_OK) return rc;
}
}
mysql> show create table t1;
+-------+-------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+-------+-------------------------------------------------------------------------------------------------------------------------------------------------+
| t1 | CREATE TABLE `t1` (
`f1` int(11) DEFAULT NULL,
`f2` int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci |
+-------+-------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec) mysql> show create table t2;
+-------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+-------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| t2 | CREATE TABLE `t2` (
`f1` int(11) NOT NULL,
`f2` int(11) NOT NULL,
`f3` char(200) DEFAULT NULL,
KEY `f1` (`f1`,`f2`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci |
+-------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec) mysql> explain SELECT /*+ BKA() */ t2.f1, t2.f2, t2.f3 FROM t1,t2 WHERE t1.f1=t2.f1 AND t2.f2 BETWEEN t1.f1 and t1.f2 and t2.f2 + 1 >= t1.f1 + 1;
+----+-------------+-------+------------+------+---------------+------+---------+-------------+------+----------+---------------------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+-------------+------+----------+---------------------------------------------------------------+
| 1 | SIMPLE | t1 | NULL | ALL | NULL | NULL | NULL | NULL | 3 | 100.00 | Using where |
| 1 | SIMPLE | t2 | NULL | ref | f1 | f1 | 4 | test1.t1.f1 | 7 | 11.11 | Using index condition; Using join buffer (Batched Key Access) |
+----+-------------+-------+------------+------+---------------+------+---------+-------------+------+----------+---------------------------------------------------------------+
2 rows in set, 1 warning (0.00 sec)
c) Batched Key Access(unique)
与Batched Key Access不同的是,r中的列是s的唯一索引,在r记录写入join cache的时候,会记录一个key的hash table,仅针对不同的key去s表中查询。(疑问,为什么只有unique的时候才能用这种方式?不是unique的话,s表中可能会扫描出多条数据,也可以用这种方式去处理,减少s表的重复扫描)。
JOIN_CACHE_BKA_UNIQUE::join_matching_records(){
while (!(error = file->ha_multi_range_read_next((char **)&key_chain_ptr))) {
do(each record in chain){
get_record_by_pos(rec_ptr);
rc = generate_full_extensions(rec_ptr);
if (rc != NESTED_LOOP_OK) return rc;
}
}
}
与Batched Key Access不同的是,r中的列是s的唯一索引,在r记录写入join cache的时候,会记录一个key的hash table,仅针对不同的key去s表中查询。(疑问,为什么只有unique的时候才能用这种方式?不是unique的话,s表中可能会扫描出多条数据,也可以用这种方式去处理,减少s表的重复扫描)。
JOIN_CACHE_BKA_UNIQUE::join_matching_records(){
while (!(error = file->ha_multi_range_read_next((char **)&key_chain_ptr))) {
do(each record in chain){
get_record_by_pos(rec_ptr);
rc = generate_full_extensions(rec_ptr);
if (rc != NESTED_LOOP_OK) return rc;
}
}
}
3. Join执行流程(老执行器)
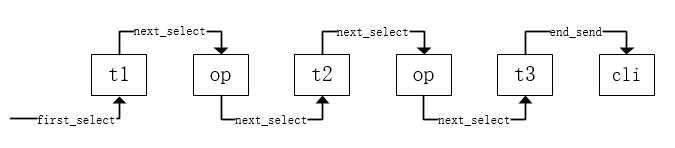
sub_select <--------------------------------------------+
| -> iterator::read() // 读一行数据 |
| -> evaluate_join_record() //检查这行数据是否符合条件 |
| -> next_select() ---+ |
| |
sub_select_op <--------+ |
| -> op->put_record() // 前表数据写入join cache |
| -> put_record_in_cache() |
| -> join->record() |
| -> join_matching_records() |
| -> (qep_tab->next_select)(join, qep_tab + 1, 0) // 继续调用next_select
| -> end_send()
数据库实践丨MySQL多表join分析的更多相关文章
- 数据库实践丨使用MTK迁移Mysql源库后主键自增列导致数据无法插入问题
摘要:用户使用Mogdb 2.0.1版本进行业务上线测试,发现在插入数据时,应用日志中提示primary key冲突,用户自查业务SQL没有问题,接到通知后,招手处理故障. 本文分享自华为云社区< ...
- mysql分表场景分析与简单分表操作
为什么要分表 首先要知道什么情况下,才需要分表个人觉得单表记录条数达到百万到千万级别时就要使用分表了,分表的目的就在于此,减小数据库的负担,缩短查询时间. 表分割有两种方式: 1水平分割:根据一列或多 ...
- MySQL数据库学习笔记----MySQL多表查询之外键、表连接、子查询、索引
本章主要内容: 一.外键 二.表连接 三.子查询 四.索引 一.外键: 1.什么是外键 2.外键语法 3.外键的条件 4.添加外键 5.删除外键 1.什么是外键: 主键:是唯一标识一条记录,不能有重复 ...
- mysql 多表join
两个表可以简单地写为 select a.,b. from a left join b on a.id =b.id; 三个以上 select a.,b. from a left join b on a. ...
- 【数据库_Mysql】MySQL—修改表时给表添加联合主键约束
添加语法如下: “ALTER TABLE table_name ADD CONSTRAINT pk_table_name PRIMARY KEY(列名1,列名2):” [示例1]假设订房信息表(O ...
- mysql锁表机制分析
http://blog.csdn.net/u010942020/article/details/51925653
- mysql merge表介绍
在Mysql数据库中,Mysql Merge表有点类似于视图.下面就让我们来一起了解一下Mysql Merge表都有哪些优点,希望对您能有所帮助. Mysql Merge表的优点: A: 分离静态的和 ...
- [转]数据库中间件 MyCAT源码分析——跨库两表Join
1. 概述 2. 主流程 3. ShareJoin 3.1 JoinParser 3.2 ShareJoin.processSQL(...) 3.3 BatchSQLJob 3.4 ShareDBJo ...
- [转]两表join的multi update语句在MySQL中的执行流程分析
出自:http://hedengcheng.com/?p=209 两表join的multi update语句,执行结果与预计不一致的分析过程 — multi update结论在实际应用中,不要轻易使用 ...
- 重新学习MySQL数据库5:根据MySQL索引原理进行分析与优化
重新学习MySQL数据库5:根据MySQL索引原理进行分析与优化 一:Mysql原理与慢查询 MySQL凭借着出色的性能.低廉的成本.丰富的资源,已经成为绝大多数互联网公司的首选关系型数据库.虽然性能 ...
随机推荐
- UVA10054 The Necklace 题解
好可恶一道题,怎么没人告诉我输出之间有空行( 思路是先抽象成图,然后跑一边dfs记录边的前后顺序. 对于不能成环的情况,只需要再开个数组记录度数判断奇点即可. 若存在奇点则break掉,剩下的跑dfs ...
- 云图说|初识API中心APIHub
阅识风云是华为云信息大咖,擅长将复杂信息多元化呈现,其出品的一张图(云图说).深入浅出的博文(云小课)或短视频(云视厅)总有一款能让您快速上手华为云.更多精彩内容请单击此处. 摘要:API中心是为AP ...
- js数据结构--数组
<!DOCTYPE html> <html> <head> <title></title> </head> <body&g ...
- 【实践篇】一次Paas化热部署实践分享
前言 本文是早些年,Paas化刚刚提出不久时,基于部门内第一次Paas化热部署落地经验所写,主要内容是如何构建一些热部署代码以及一些避雷经验. 一.设计-领域模型设计 1.首先,确定领域服务所属的领域 ...
- rt-thread Env 预处理配置方法
简介 rt-thread 是我非常喜欢的一款RTOS,近期在使用Env更新工程的时候发现,keil MDK 中的预处理型号和器件型号不符. 这就导致我每次更新工程后都需要进入keil MDK手动修改一 ...
- node 实现上传 和 下载 文件接口 简易版
var express = require('express');var fs = require('fs');var path = require('path');var multipart = r ...
- GPTs破冰硅基文明社会
GPTs破冰硅基文明社会 渐进是技术革命的常态 技术革命看似一夕之间就颠覆了世界,但实际上每项重大技术进步的背后,都经历了漫长的渐进积累.以蒸汽机为例,最初动力微弱.效率低下,需要大量工程师跟车维护, ...
- Mysql不同数据库之间表结构同步
开发环境的Mysql表结构做了修改,要同步到其他环境数据库中使用数据库管理工具JookDB的表结构同步功能就很方便.虽然Navicat也有这个功能但是有免费的当然是用免费的. 用JookDB添加数据库 ...
- Linux下^m符号删除
Linux下^m符号删除 从Windows上复制的代码到Linux尾会有M字符,通过下命令可以删除. :%s/\r//
- Logistics Regression (对数几率回归)及numpy实现
Logistics Regression 我们知道线性回归模型可以处理回归问题,但是如何处理分类问题? 对于一个二分类问题,或许我们可以认为w*x+b > 0为正类,其他情况为负类. 那么模型不 ...