数仓性能调优:row_number() over(p)-rn=1性能瓶颈发现和改写套路
本文分享自华为云社区《GaussDB(DWS)性能调优:row_number() over(p)-rn=1性能瓶颈发现和改写套路》,作者:Zawami 。
1、改写场景
本套路应用于子查询中含有row_number() over(partition by order by) rn,并仅把rn列用于分类排序后筛选最大值的场景。
2、性能分析
GaussDB中SQL语句的执行很多时候是流式的,即对每一条数据进行流水加工,各层算子同时在执行,缩短执行耗时。
但是在一些场景下,需要先取得前一个算子的全部结果集,然后才能够进行下一步的加工;窗口函数就是其中的一种。
观察执行计划可以看到,SQL会在计算得到rn列后,再同本层查询其它列进行关联。由于存在窗口函数,必须先把51号算子先执行完,然后才能进行关联,造成性能瓶颈。
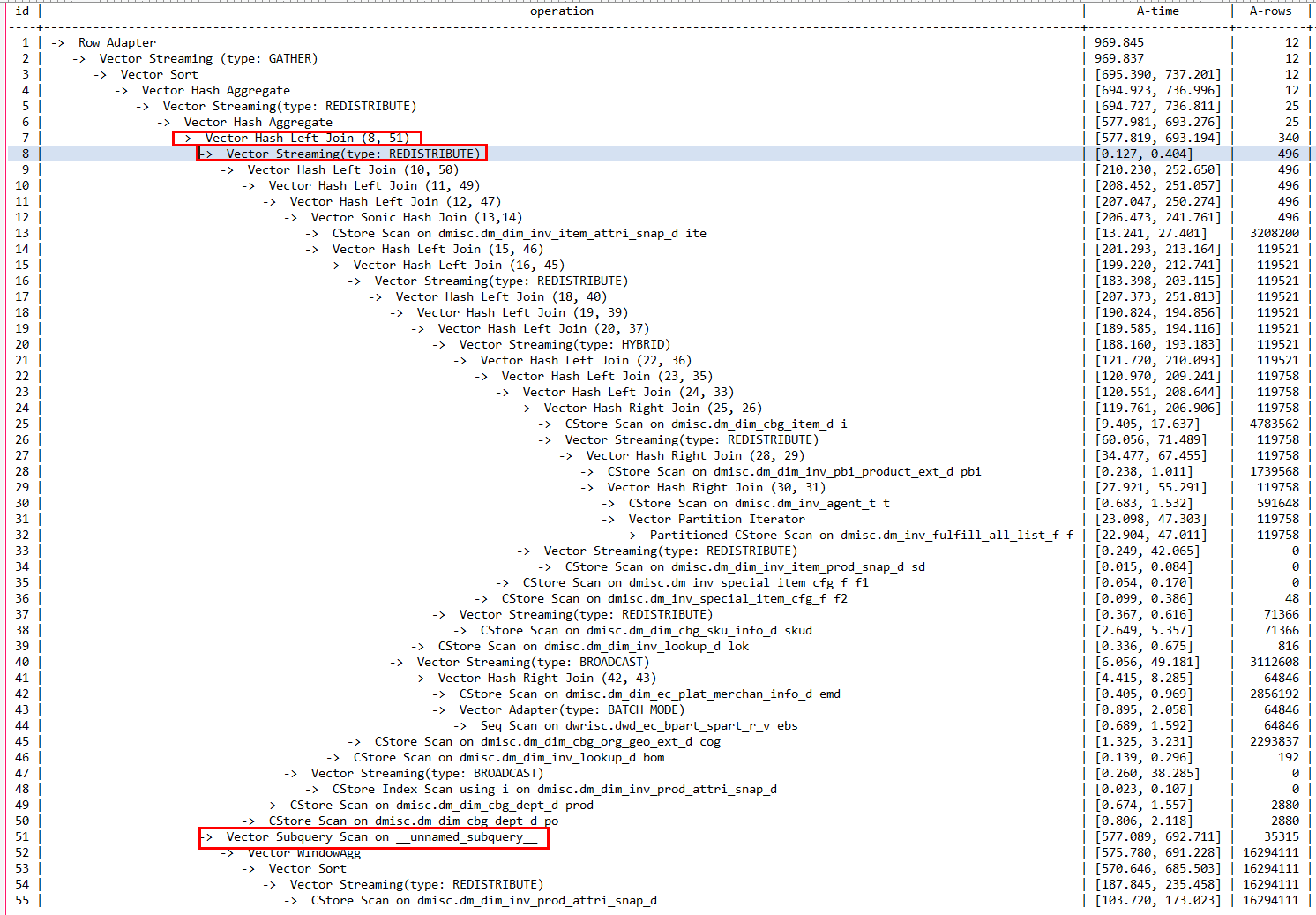
通过去窗口函数改写,我们可以使得分类汇总同明细数据之间的关联流水执行。
改写前局部SQL
SELECT PROD_EN_NAME, PROD_LIFE_CYCLE_STATUS FROM ( SELECT PROD_EN_NAME, LIFE_CYCLE AS PROD_LIFE_CYCLE_STATUS, DEL_FLAG, ROW_NUMBER ( ) OVER ( PARTITION BY PROD_EN_NAME ORDER BY RUN_DATE DESC ) RN FROM DMISC.DM_DIM_INV_PROD_ATTRI_SNAP_D WHERE DATA_TYPE = 1 AND DEL_FLAG = 'N' AND RUN_DATE <= CAST ( '2023-06-11' || ' 00:00:00' AS TIMESTAMP ) ) WHERE RN = 1
改写后局部SQL
WITH T AS ( SELECT PROD_EN_NAME, MAX ( LIFE_CYCLE ) AS PROD_LIFE_CYCLE_STATUS, RUN_DATE FROM DMISC.DM_DIM_INV_PROD_ATTRI_SNAP_D WHERE DATA_TYPE = 1 AND DEL_FLAG = 'N' AND RUN_DATE <= CAST ( '2023-06-11' || ' 00:00:00' AS TIMESTAMP ) GROUP BY PROD_EN_NAME, RUN_DATE ) SELECT PROD_EN_NAME, PROD_LIFE_CYCLE_STATUS FROM T WHERE (PROD_EN_NAME, RUN_DATE) IN (SELECT PROD_EN_NAME, MAX(RUN_DATE) FROM T GROUP BY PROD_EN_NAME)
改写解析:这里先把数据根据原SQL中row_number() over()的partition列和order列进行去重,由于原SQL未定义LIFE_CYCLE的排序方式,改写既可以使用MAX也可以使用MIN函数来进行聚合。然后再对去重后的数据进行过滤,过滤条件显然。
使用这种修改方法,修改前后的全量执行计划已在附件中给出。
这种改写方式解决了上层算子等窗口函数的问题。我们发现,一些业务场景下对不涉及聚合的其它列,比如上面例子中的LIFE_CYCLE并不敏感,且还需要进行进一步聚合的,那么对本层子查询中的去重其实没有硬性需求。可以进一步去除这层去重。
WITH T AS ( SELECT PROD_EN_NAME, LIFE_CYCLE AS PROD_LIFE_CYCLE_STATUS, RUN_DATE FROM DMISC.DM_DIM_INV_PROD_ATTRI_SNAP_D WHERE DATA_TYPE = 1 AND DEL_FLAG = 'N' AND RUN_DATE <= CAST ( '2023-06-11' || ' 00:00:00' AS TIMESTAMP ) ) SELECT PROD_EN_NAME, PROD_LIFE_CYCLE_STATUS FROM T WHERE (PROD_EN_NAME, RUN_DATE) IN (SELECT PROD_EN_NAME, MAX(RUN_DATE) FROM T GROUP BY PROD_EN_NAME)
改写后执行计划如下:
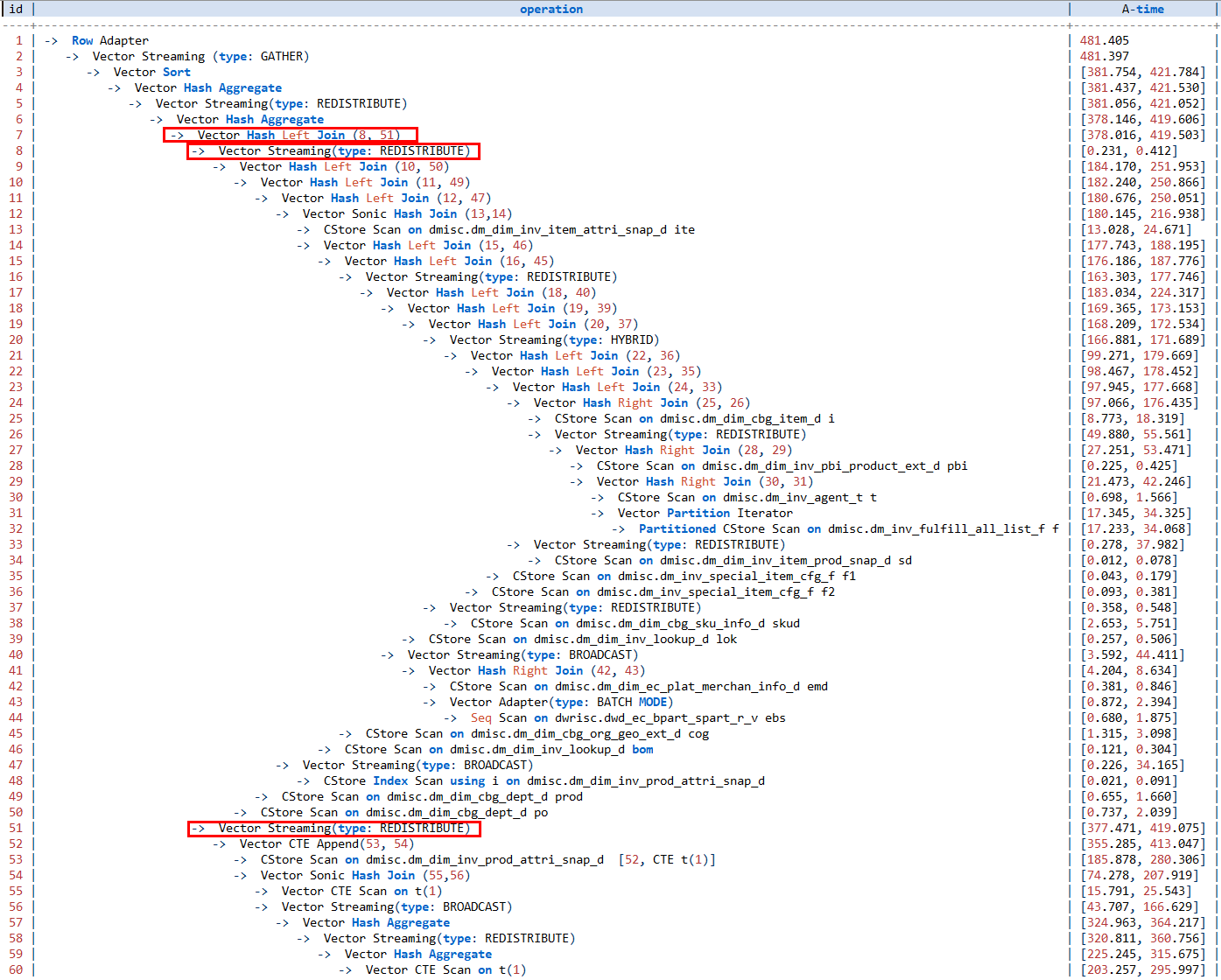
可以看到,执行计划中虽然51层算子只快了200ms,但由于减少阻塞,1~7层算子的执行时间缩短了,总体比原先快了约480ms。
数仓性能调优:row_number() over(p)-rn=1性能瓶颈发现和改写套路的更多相关文章
- 十八般武艺玩转GaussDB(DWS)性能调优:SQL改写
摘要:本文将系统介绍在GaussDB(DWS)系统中影响性能的坏味道SQL及SQL模式,帮助大家能够从原理层面尽快识别这些坏味道SQL,在调优过程中及时发现问题,进行整改. 数据库的应用中,充斥着坏味 ...
- Java性能调优(一):调优的流程和程序性能分析
https://blog.csdn.net/Oeljeklaus/article/details/80656732 Java性能调优 随着应用的数据量不断的增加,系统的反应一般会越来越慢,这个时候我 ...
- Hadoop作业性能指标及參数调优实例 (二)Hadoop作业性能调优7个建议
作者:Shu, Alison Hadoop作业性能调优的两种场景: 一.用户观察到作业性能差,主动寻求帮助. (一)eBayEagle作业性能分析器 1. Hadoop作业性能异常指标 2. Hado ...
- Apache Pulsar 在 BIGO 的性能调优实战(上)
背景 在人工智能技术的支持下,BIGO 基于视频的产品和服务受到广泛欢迎,在 150 多个国家/地区拥有用户,其中包括 Bigo Live(直播)和 Likee(短视频).Bigo Live 在 15 ...
- [网站性能2]Asp.net平台下网站性能调优的实战方案
文章来源:http://www.cnblogs.com/dingjie08/archive/2009/11/10/1599929.html 前言 最近帮朋友运营的平台进行了性能调优,效果还不错, ...
- Asp.net平台下网站性能调优的实战方案(转)
转载地址:http://www.cnblogs.com/chenkai/archive/2009/11/07/1597795.html 前言 最近帮朋友运营的平台进行了性能调优,效果还不错,所以写出来 ...
- hadoop 性能调优与运维
hadoop 性能调优与运维 . 硬件选择 . 操作系统调优与jvm调优 . hadoop运维 硬件选择 1) hadoop运行环境 2) 原则一: 主节点可靠性要好于从节点 原则二:多路多核,高频 ...
- JVM性能调优监控工具jps、jstack、jmap、jhat、jstat、hprof使用详解
摘要: JDK本身提供了很多方便的JVM性能调优监控工具,除了集成式的VisualVM和jConsole外,还有jps.jstack.jmap.jhat.jstat.hprof等小巧的工具,本博客希望 ...
- Java性能调优
一.JVM内存模型及垃圾收集算法 1.根据Java虚拟机规范,JVM将内存划分为: New(年轻代) Tenured(年老代) 永久代(Perm) 其中New和Tenured属于堆内存,堆内存会从JV ...
- JVM内存模型与性能调优
堆内存(Heap) 堆是由Java虚拟机(JVM,下文提到的JVM特指Sun hotspot JVM)用来存放Java类.对象和静态成员的内存空间,Java程序中创建的所有对象都在堆中分配空间,堆只用 ...
随机推荐
- 软件开发人员 Kubernetes 入门指南|Part 1
Kubernetes 是一个用于部署和管理容器的编排系统.使用 Kubernetes,用户可以通过自动执行管理任务(例如在跨节点间扩展容器并在容器停止时重新启动任务),在不同环境中可靠地运行容器. K ...
- docker入门加实战—Docker镜像和Dockerfile语法
docker入门加实战-Docker镜像和Dockerfile语法 镜像 镜像就是包含了应用程序.程序运行的系统函数库.运行配置等文件的文件包.构建镜像的过程其实就是把上述文件打包的过程. 镜像结构 ...
- Vue源码学习(十二):列队处理(防抖优化,多次调用,只处理一次)
好家伙, 本篇讲的是数据更新请求列队处理 1.一些性能问题 数据更新的核心方法是watcher.updata方法 实际上也就是vm._updata()方法, vm._updata()方法中的patch ...
- 栩栩如生,音色克隆,Bert-vits2文字转语音打造鬼畜视频实践(Python3.10)
诸公可知目前最牛逼的TTS免费开源项目是哪一个?没错,是Bert-vits2,没有之一.它是在本来已经极其强大的Vits项目中融入了Bert大模型,基本上解决了VITS的语气韵律问题,在效果非常出色的 ...
- HExcel,一个简单通用的导入导出Excel工具类
前言 日常开发中,Excel的导出.导入可以说是最常见的功能模块之一,一个通用的.健壮的的工具类可以节省大量开发时间,让我们把更多精力放在业务处理上中 之前我们也写了一个Excel的简单导出,甚至可以 ...
- 花了三年时间开发的开源项目,终于500 个 Star 了!
waynboot-mall 商城项目从疫情开始初期着手准备,到现在已经经过了 3 年多的时间,从项目初期到现在,一个人持续迭代,修复漏洞,添加功能,经历了前端开发工具从 vue2.vue-cli 切换 ...
- Welcome to YARP - 5.身份验证和授权
目录 Welcome to YARP - 1.认识YARP并搭建反向代理服务 Welcome to YARP - 2.配置功能 2.1 - 配置文件(Configuration Files) 2.2 ...
- deepin解决文件管理器打不开和桌面黑屏的问题
总结 deepin 的优点是上手非常容易, 但截止当前(2021-6-24)的使用来说稳定性还不是非常好. 今天就遇到了无法显示桌面的问题,可以参照如下解决办法.只需使用红色框中的命令即可. 图片转载 ...
- Qt+FFmpeg播放mp4文件视频
关键词:Qt FFmpeg C++ MP4 视频 源码下载在系列原文地址. 先看效果. 这是一个很简单的mp4文件播放demo,为了简化,没有加入音频数据解析,即只有图像没有声音. 音视频源的播放可以 ...
- Spring5学习随笔-Spring5的第一个程序(环境搭建、日志框架整合)
第二章.第一个Spring程序 1.软件版本 1.JDK1.8+ 2.Maven3.5+ 3.IDEA2018+ 4.SpringFramework 5.1.4 官网:www.spring.io 2. ...