[转帖]讨论在 Linux Control Groups 中运行 Java 应用程序的暂停问题原创
https://heapdump.cn/article/1930426
说明
本篇原文来自 LinkedIn 的 Zhenyun Zhuang,原文:Application Pauses When Running JVM Inside Linux Control Groups[1],在容器化的进程中,或多或少会给现有应用程序带来一些问题,这篇文章讲的是 LinkedIn 在使用 cgroups 构建容器化产品过程中,发现资源限制策略对 Java 应用程序性能会产生一些影响,文章深入分析问题根本原因,并给出解决方案。笔者看过后,觉得非常赞,因此翻译后献给大家,希望对大家有帮助。
前言
基于 Linux cgroups[2]的解决方案(例如,Docker[3],CoreOS[4])越来越多地用于在同一主机上托管多个应用程序。我们一直在 LinkedIn 上使用 cgroups 来构建我们自己的容器化[5]产品 LPS[6](LinkedIn 平台即服务),并研究资源限制策略对应用程序性能的影响。这篇文章介绍了我们关于 CPU 调度如何影响 cgroups 中 Java 应用程序性能的一些发现。我们发现,在将 CFS[7](完全公平调度程序)与 CFS 带宽控制的配额结合使用时,Java 应用程序可能会有越来越长的暂停。在这些暂停期间,应用程序不能响应用户请求,因此,这是我们需要分析和解决这个严重性能问题。
这些增多的暂停是由 JVM 的 GC(垃圾收集)机制和 CFS 调度之间的交互引起的。在 CFS 中,为 cgroup 分配了一定的 CPU 配额(即 cfs_quota),这会被 JVM GC 的多线程活动快速耗尽,从而导致应用程序受到限制。例如,可能会发生以下情况:
如果一个应用程序在一个调度期间积极地使用其 CPU 配额,那么该应用程序就会受到限制(不再使用 CPU),并在调度期间的剩余持续时间内停止响应。
多线程的 JVM GC 会使问题更加严重,因为应用程序的所有线程都计算了cfs_quota(配额)。因此,CPU 配额可能会更快地用完。JVM GC 有许多非 STW(stop the world)的并发阶段。但是,它们的运行也会导致更快的使用完 CPU 配额,因此,实际上将整个应用程序设置为 STW(stop the world)。
在本文中,我们将分享我们研究这个问题之后的发现,以及我们关于 CFS/JVM 调优以减轻负面影响的建议。具体而言:
应该将足够的 CPU 配额分配给承载 Java 应用程序的 CGROUP;
应该适当地调低 JVM GC 线程,以缓解暂停。
Linux cgroups 背景
Linux cgroups(控制组)用于限制应用程序的各种类型资源的使用。对于 CPU 资源,CPU 子系统调度 CPU 的 cgroup 任务访问,CFS 是两个受支持的调度程序之一。 CFS 是一个比例共享调度程序,它根据 cgroup 的权重为 cgroup 分配 CPU 访问权限。
对于我们使用的 RHEL7[8](Red Hat Enterprise Linux)机器,有多个可调参数。用于限制 CPU 执行的有两个 CFS 参数,这两个参数可以用于限制 cgroup 使用的 CPU 资源:cpu.cfsperiodus 和 cpu.cfsquotaus,均以微秒为单位。 cpu.cfsperiodus 指定应用配额的 CFS 周期或强制执行间隔,cpu.cfsquotaus指定 cgroup 在每个 CFS 周期中可以使用的配额。 cpu.cfsquotaus 实质上设置了 CPU 资源的硬限制(即上限)。 cgroup(及其进程)仅允许在 cpu.cfsquotaus 中指定的持续时间内占用 CPU 核心资源。因此,为了给出 cgroup N 核,cpu.cfsquotaus 设置为 cpu.cfsperiodus 的 N 倍。
工作负载和配置情况
为了进行分析,我们创建了一个用于测试 CFS 行为的 Java 应用程序。这个 Java 应用程序简单地在 Java 堆上分配对象。当分配的对象数量达到某个阈值后,将释放其中的一部分。有两个应用程序线程,每个线程独立地执行对象分配和对象释放。每个对象分配所花费的时间记录为分配延迟。这个测试 Java 应用程序的源代码位于 GitHub[9] 上。
我们考虑的性能指标包括:
(1)应用程序吞吐量(对象分配率);
(2)对象分配延迟;
(3)cgroup 的统计信息,包括 cgroup 的 CPU 使用率,nrthrottled(受限制的 CFS 周期数)和 throttledtime(总限制时间)。
我们使用的机器是 RHEL7,内核为 3.10.0-327,它有 24 个 HT(超线程)内核。使用 CFS 上限强制限制 CPU 资源。默认情况下,托管 Java 应用程序的 cgroup 被分配了三个 CPU 共享核心,考虑到有两个应用程序线程和 GC 活动。在以后的测试中,我们还改变了分配的核心数量,以获得更多的信息。默认情况下,cfsperiod 为 100 毫秒。每次运行工作需要 20 分钟(1200 秒)。因此,当 cfsperiod 为 100ms 时,每次运行中有 12,000 个 CFS 周期。
排查应用长时间暂停
我们将从对特定应用程序暂停的详细分析开始,以便了解暂停背后的原因。
应用暂停
在 22:57:34 时,两个应用程序线程都停止大约三秒钟(即 2,917 毫秒和 2,916 毫秒)。
// Thread id, time stamp, application freezing time (ms)
Thread 1: 2016-10-07 22:57:34.00974,2917
Thread 2: 2016-10-07 22:57:34.00975,2916
JVM GC STW
为了理解导致三秒钟应用程序冻结的原因,我们首先检查了 JVM GC 日志。我们发现在 22:57:37.771 时,STW(停止世界)GC 暂停发生。请注意,暂停持续约 0.12 秒。
2016-10-07T22:57:33.985+0000: 30.856: [GC concurrent-root-region-scan-start]
2016-10-07T22:57:33.991+0000: 30.863: [GC concurrent-root-region-scan-end, 0.0064502 secs]
2016-10-07T22:57:33.991+0000: 30.863: [GC concurrent-mark-start]
2016-10-07T22:57:37.771+0000: 34.642: [GC pause (G1 Evacuation Pause) (young), 0.1194989 secs]
[Parallel Time: 118.0 ms, GC Workers: 18]
[GC Worker Start (ms): Min: 34642.7, Avg: 34642.9, Max: 34643.1, Diff: 0.4]
[Ext Root Scanning (ms): Min: 0.0, Avg: 0.1, Max: 0.3, Diff: 0.3, Sum: 1.3]
[SATB Filtering (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
[Update RS (ms): Min: 8.5, Avg: 10.8, Max: 13.7, Diff: 5.2, Sum: 194.8]
[Processed Buffers: Min: 3, Avg: 3.6, Max: 4, Diff: 1, Sum: 65]
[Scan RS (ms): Min: 0.0, Avg: 1.3, Max: 4.0, Diff: 4.0, Sum: 23.2]
[Code Root Scanning (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
[Object Copy (ms): Min: 103.8, Avg: 105.4, Max: 105.9, Diff: 2.2, Sum: 1896.6]
[Termination (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.5]
[GC Worker Other (ms): Min: 0.0, Avg: 0.0, Max: 0.1, Diff: 0.1, Sum: 0.6]
[GC Worker Total (ms): Min: 117.4, Avg: 117.6, Max: 117.9, Diff: 0.4, Sum: 2117.1]
[GC Worker End (ms): Min: 34760.5, Avg: 34760.6, Max: 34760.6, Diff: 0.1]
[Code Root Fixup: 0.0 ms]
[Code Root Purge: 0.0 ms]
[Clear CT: 0.5 ms]
[Other: 1.0 ms]
[Choose CSet: 0.0 ms]
[Ref Proc: 0.2 ms]
[Ref Enq: 0.0 ms]
[Redirty Cards: 0.2 ms]
[Humongous Reclaim: 0.0 ms]
[Free CSet: 0.1 ms]
[Eden: 1120.0M(1120.0M)->0.0B(1120.0M) Survivors: 160.0M->160.0M Heap: 16.6G(25.0G)->15.9G(25.0G)]
[Times: user=1.27 sys=0.09, real=0.12 secs]
2016-10-07T22:57:37.891+0000: 34.762: Total time for which application threads were stopped: 0.1197007 seconds, Stopping threads took: 0.0000314 seconds
与 3 秒钟的应用停止相比,0.12 秒的 GC 暂停不足以解释 2.88 秒(即 3 - 0.12)的时间差距;因此,暂停必然有其他原因。
CFS 限制
我们怀疑应用程序除了 GC 外的暂停是由 cgroups 的 CFS 调度程序引起的。我们通过收集应用程序运行的每一秒的各种类型的报告 cgroups 统计信息来检查 cgroups 的统计信息。我们发现“throttledtime”的指标很有意义。 “throttledtime”报告该组实体已被限制的累计总持续时间(以纳秒为单位)。
我们注意到,当应用程序被冻结时,“throttledtime”发生在 22:57:33。当应用程序处于冻结期时,“throttledtime”的增加(即差异)约为 5.28 秒。因此,我们认为“throttled_time”导致应用冻结。
// time stamp, throttled_time in ns, delta in seconds (difference from last report)
2016-10-07 22:57:32.01789 throttled_time 72284616704759 //
2016-10-07 22:57:33.02097 throttled_time 72288113805728 // delta = 3.497 seconds
2016-10-07 22:57:34.02403 throttled_time 72288643653704 // delta = 0.529 seconds
2016-10-07 22:57:35.02707 throttled_time 72289899729523 // delta = 1.256 seconds
2016-10-07 22:57:36.03015 throttled_time 72289899729523 // delta = 0 seconds
2016-10-07 22:57:37.03311 throttled_time 72289899729523 // delta = 0 seconds
JVM GC 线程
我们发现一些 CFS 调度周期暴露了大量的“throttled_time”,我们认为这是由(多个)JVM GC 线程引起的。简而言之,当 GC 启动时,JVM 会调用多个 GC 线程来完成工作。 JVM 使用内部公式来决定 GC 线程的数量。具体来说,对于具有 24 个内核的计算机,并行 GC 线程的数量为 18,并发 GC 线程的数量为 5。由于这些大量线程,cgroup 的 CPU 配额很快用完,导致所有应用程序线程(包括 GC 线程)暂停。
// Flag: -XX:+PrintFlagsFinal
// The machine has 24 cpu cores
// GC output
uintx ParallelGCThreads = 18 {product}
uintx ConcGCThreads := 5
CFS 调度程序如何导致应用程序暂停?
CFS 调度程序可能导致应用程序长时间的暂停。有些情况下,cgroup(以及在cgroup 中运行的应用程序)受到限制,导致应用程序暂停很长时间。虽然“GC 线程更快速地使用 CFS 配额(cpu.cfsquotaus)”的简要回答很容易给出,但我们想更全面地了解这个问题,以便提出解决方案。
关于使用 CFS 调度程序时应用程序暂停有三种问题场景,我们将逐一解释。为了更好地说明问题,我们使用具体配置的示例(例如,cfsperiod 和 cfsquota)。
理想场景(预期场景)
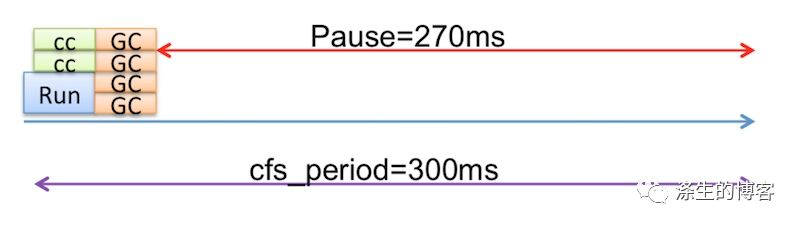
假设 cfsperiod 为 300ms,cgroup(仅含有单个应用程序)的 cfsquota 为 90ms。我们还假设应用程序只有一个活动线程来简化表示。
理想情况下,CPU 调度程序会调度应用程序在每个 CFS 周期内稀疏运行,以便应用程序不会长时间暂停。如下图所示,应用程序计划在 300ms CFS 期间运行 3 次。计划运行之间存在应用程序暂停,预期的应用程序暂停时间为 70 毫秒(假设应用程序完全使用 90 毫秒 CPU 配额)。

Java 和非 Java 应用程序的问题场景
第一个问题发生在应用程序耗尽 90ms 的所有 CPU 配额时,例如在某些 CFS 时段的前 90ms 内。然后,由于配额被占用,在剩余的 210ms 期间,应用程序暂停,用户经历 210ms 延迟。请注意,多线程应用程序的问题更严重,因为 CPU 配额可以更快地用完。

Java 应用程序的问题场景(GC 期间的 STW 阶段)
在 STW(stop the world)GC 暂停期间,Java 应用程序更严重,因为 JVM 可以使用多个 GC 线程并行收集垃圾。
假设在某些 CFS 期间,在应用程序运行 30ms 后,需要完成 STW GC。我们假设 GC 工作需要 60ms 的 CPU,而 JVM 有 4 个 GC 线程。然后在 45ms 内,可以完全消耗 90ms 的整个 CPU 配额(即,在“运行”期间的 CPU 时间是(60ms “GC”/ 4个线程 = 15ms)GC 实际时间 + 30ms 应用运行)。剩余的 255ms 将是应用程序暂停时间。
显然,使用更多 GC 线程,可以更快地耗尽 CPU 配额。请注意,在现代计算机上,GC 线程的数量可能会大得多,因为在 cgroup 中运行的每个 JVM 仍会根据整个物理主机的 CPU 核心数设置其 GC 并行化级别。例如,在 12 核机器上,默认情况下 JVM 使用 9 个 GC 线程。 24 核机器将使JVM使用 18 个 GC 线程。

Java 应用程序的问题场景(GC 期间的并发阶段)
对于流行的 JVM 垃圾收集器,如 CMS 和 G1,GC 有多个阶段;某些阶段是 STW,其他阶段是并发(非 STW)。虽然并发 GC 阶段(使用并发 GC 线程)旨在避免 JVM STW,但 cgroup 的使用完全违背了目的。在并发 GC 阶段,使用的 CPU 时间也会影响 cgroup 的 CPU 使用率,这实际上会导致应用程序遇到更大的“STW”暂停。
建议
我们已经看到,由于 JVM GC 和 CFS 调度之间的交互,在 Linux cgroup 中运行的 Java 应用程序可能会遇到更长的应用程序暂停。为缓解此问题,我们建议您使用以下调整:
充分配置 CPU 资源(即 CFS 配额)。显然,分配给 cgroup 的 CPU 配额越大,cgroup 被限制的可能性就越小。
适当调整 GC 线程。
充分配置 CPU 资源
对于我们使用的只有 2 个活动应用程序线程的工作负载,似乎 2 个 CPU 核心可以满足 CPU 需求。但是,我们发现由于 GC 活动,应用程序受益于更大的 CPU 配额(即,更多的 CPU 核心)。
应用程序性能(吞吐量和延迟)
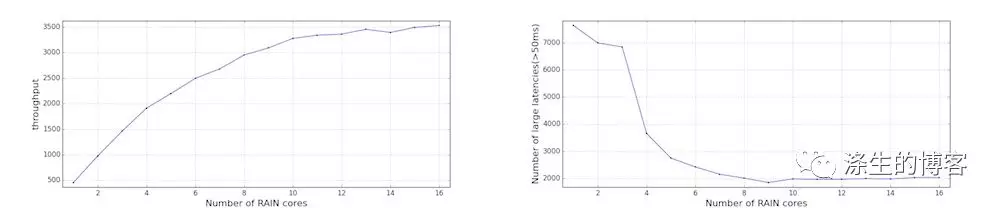
为了了解特定 JVM 工作负载需要多少 CPU 核心,我们改变了分配给每个主机 cgroup 的 CPU 份额(以 CPU 核心为单位,其中配额的 CPU 核心等于 CFS 周期的单位)。我们发现,分配了更多内核后,应用程序吞吐量不断增加,直到大约 12 个内核。与 2 个应用程序线程相比,这种差异(即 12 对 2)显示了将CPU 份额充分提供给 Java 应用程序的重要性。
我们还计算了大的分配延迟(即超过 50 毫秒)的数量,并发现随着更多内核,大延迟的数量持续下降,直到大约 8 个内核。
Cgroup 的 CPU 使用率
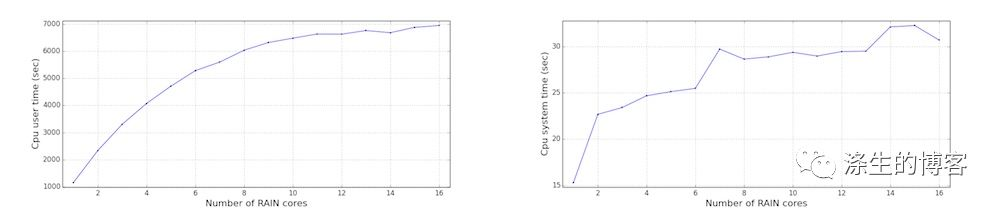
cgroup 的 CPU 使用率(用户时间和系统时间)也随着分配的内核数量的增加而增加,如下图所示。请注意,值是来自所有核心的聚合值。运行时间为 1,200 秒,CPU 使用率为 6,000 秒表示整体 5 核 CPU 使用率。
这些结果表明,对于具有 2 个活动应用程序线程的此特定 Java 应用程序,需要将更多内核分配给主机 cgroup。
调整 GC 线程(ParallelGCThreads)
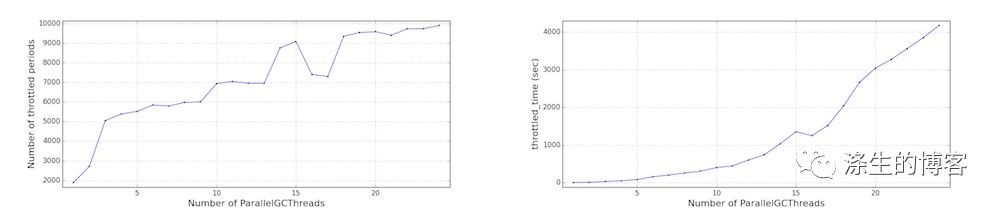
我们还将 ParallelGCThreads 从 1 改为 24,以了解性能影响。请注意,是通过 JVM 参数来调整 ParallelGCThreads,ConcGCThreads 的值。
更多 GC 线程倾向于更快地耗尽 CFS 配额,如 Cgroup 性能(受限制的 CFS 周期数和受限制时间)所示。结果,观察到更大的延迟。应用程序吞吐量没有太大变化,但对于此特定工作负载,它实际上会下降。
这些结果表明调低 GC 线程可能有利于应用程序性能。但是,应用程序在许多方面有所不同(例如,GC 频率,堆大小,应用程序线程的特征),因此需要针对每个应用程序评估这些调整的影响。由于空间问题和进一步调查的复杂性,我们不会深入研究这方面。
Cgroup 性能(受限制的 CFS 周期数和受限制时间)
应用程序性能(延迟和吞吐量)
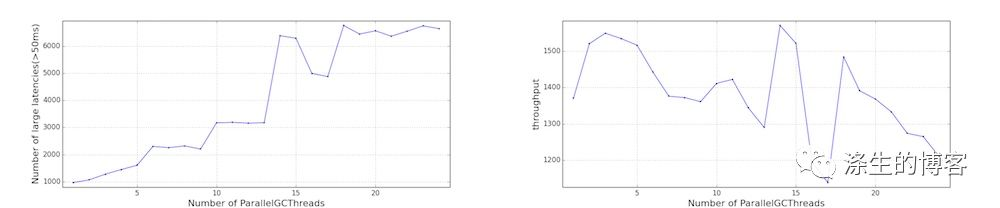
讨论
CFS 上限限制或相对共享
CFS 调度支持上限限制(即硬限制)和相对共享。 CFS 相对共享使用cpu.shares 可调参数来控制 cgroups 可以使用的 CPU 资源的权重。虽然它允许 cgroup 使用其他空闲的 CPU 资源,但由于依赖于其他 cgroup,相对共享具有性能可预测性差的限制。应用程序将根据 CPU 内核的可用性看到不同的性能,这使得容量规划和性能监视难以实现。
在只有一个 cgroup 主动使用 CPU 的机器上,相对共享允许“忙” cgroup “窃取” CPU 资源超出其逻辑份额(由其 cpu.shares 部分表示),因此 JVM GC 的影响不太明显。然而,当机器满负载(即,所有 CPU 核心都忙),相对共享的有效性与上限强制执行相当,因为每个 cgroup 仅被允许消耗相应的 CPU 资源部分。因此,由多线程 JVM GC 引起的性能问题 - 以及严重的应用程序暂停 - 将显示出来。
调整 GC 线程依赖工作负载
减少 GC 线程的数量有助于降低 CFS 共享过早耗尽的可能性,从而有助于减少由 CFS 限制导致的长应用程序暂停。但是,较少的 GC 线程也可能导致更长的 GC STW 暂停,因为 GC 工作需要更多时间才能完成。因此,需要在这两个问题之间进行权衡,并且适当数量的 GC 线程取决于工作负载特征和延迟 SLA(服务级别协议),因此应谨慎选择。
结论
在 Linux cgroup 中运行 Java 应用程序需要彻底了解 JVM GC 如何与 cgroup 的 CPU 调度交互。我们发现由于密集的 GC 活动,应用程序可能会遇到更长的暂停。为确保满意的应用程序性能,必须配置足够的 CPU 配额,并且根据情况,应调整 GC 线程。
[转帖]讨论在 Linux Control Groups 中运行 Java 应用程序的暂停问题原创的更多相关文章
- 在Linux中运行Nancy应用程序
最近在研究如何将.NET应用程序移植到非Windows操作系统中运行,逐渐会写一些文章出来.目前还没有太深的研究,所以这些文章大多主要是记录我的一些实验. 这篇文章记录了我如何利用NancyFx编写一 ...
- 在Docker中监控Java应用程序的5个方法
译者注:Docker是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的Linux机器上,也可以实现虚拟化.通常情况下,监控的主要目的在于:减少宕机 ...
- 在Eclipse中运行JAVA代码远程操作HBase的示例
在Eclipse中运行JAVA代码远程操作HBase的示例 分类: 大数据 2014-03-04 13:47 3762人阅读 评论(2) 收藏 举报 下面是一个在Windows的Eclipse中通过J ...
- (转)在Docker中运行Java:为了防止失败,你需要知道这些
转自:https://mp.weixin.qq.com/s?__biz=MzA5OTAyNzQ2OA==&mid=2649693848&idx=1&sn=4e9ef7e2a9d ...
- 在dos中运行java程序,若出现Exception in thread “main" java.lang.NoClassDefFoundError
在dos中运行java程序,若出现Exception in thread “main" java.lang.NoClassDefFoundError,可以检查一下几项: 环境变量配置: 注意 ...
- vc++ 在程序中运行另一个程序的方法
在vc++ 程序中运行另一个程序的方法有三个: WinExec(),ShellExcute()和CreateProcess() 三个SDK函数: WinExec,ShellExecute ,Creat ...
- cmd 窗口中运行 Java 程序
1.CMD 命令提示符(Command Processor)(CMD) CMD命令:开始->运行->键入 cmd(在命令行里可以看到系统版本.文件系统版本) 2.对文件夹操作的部分命令 启 ...
- eclipse中运行java程序
1 package ttt; public class Testttt { public static void main() { Person p =new Person(); p.name=&qu ...
- call_usermodehelper内核中运行用户应用程序
init是用户空间第一个程序,在调用init前程序都运行在内核态,之后运行init时程序运行到用户态. 操作系统上,一些内核线程在内核态运行,它们永远不会进入用户态.它们也根本没有用户态的内存空间.它 ...
- Linux下启动和停止Java应用程序的Shell脚本
转自:http://blog.csdn.net/jadyer/article/details/7960802 资料参考来源自兔大侠,并略作修改:http://www.tudaxia.com/archi ...
随机推荐
- 训练千亿参数模型的法宝,昇腾CANN异构计算架构来了~
摘要:盘古的训练以「昇腾AI处理器」为基座,同时借助了「CANN 异构计算架构」,让硬件算力得以充分释放,大大缩短了训练时间! 2021年4月,"华为云盘古大模型"一炮走红AI人工 ...
- CANN AICPU算子耗时分析及优化探索
摘要:本文以GreaterEqual作为测试算子,该算子计算逻辑较为简单(output = input1 >= input2),旨在尽可能降低计算耗时,使得算子耗时尽可能以数据操作和算子调度作为 ...
- XEngine:深度学习模型推理优化
摘要:从显存优化,计算优化两个方面来分析一下如何进行深度学习模型推理优化. 本文分享自华为云社区<XEngine-深度学习推理优化>,作者: ross.xw. 前言 深度学习模型的开发周期 ...
- GIS常用npm包:GeoJSON文件合并与元素过滤\属性过滤\图形合并
GeoJSON文件合并 普通的geoJSON文件合并,只需geojson-merge插件就够了,https://www.npmjs.com/package/@mapbox/geojson-merge ...
- CentOS 硬盘扩容
首先在虚机内将硬盘空间扩大,Hyper-V 需要将检查点删除 查看物理卷和卷组,并将物理卷加入到卷组 lvextend -l +100%FREE /dev/centos/root #将剩余空间添 ...
- Flutter如何有效地退出程序
今天博主来谈一个开发Flutter App的小技巧--怎样有效地退出程序. 这种方法典型的应用场景就是用户许可协议的同意与否.从用户的角度讲,虽然大部分人都会无脑点击"同意",但我 ...
- L2-007 家庭房产 (25 分) (并查集)
给定每个人的家庭成员和其自己名下的房产,请你统计出每个家庭的人口数.人均房产面积及房产套数. 输入格式: 输入第一行给出一个正整数N(≤1000),随后N行,每行按下列格式给出一个人的房产: 编号 父 ...
- @Constraint注解,做特殊的入参校验
// @Constraint 是 Java 中的注解之一,用于标记自定义的约束注解.约束注解通常用于数据验证,用来限制字段的取值或格式,确保数据的合法性. @Constraint(validatedB ...
- ==和equals的区别和联系,StringBuffer和StringBuilder,clone方法
==和equals的区别和联系? ( 1)对于==,比较的是值是否相等 如果作用于基本数据类型的变量,则直接比较其存储的 "值"是否相等: 如果作用于引用类型的变量,则比较的是所指 ...
- vue tabBar导航栏设计实现2-抽取tab-bar
系列导航 一.vue tabBar导航栏设计实现1-初步设计 二.vue tabBar导航栏设计实现2-抽取tab-bar 三.vue tabBar导航栏设计实现3-进一步抽取tab-item 四.v ...