王树森Attention与Self-Attention学习笔记
Seq2Seq + Attention
Seq2Seq模型,有一个Encoder和一个Decoder,默认认为Encoder的输出状态h_m包含整个句子的信息,作为Decoder的输入状态s_0完成整个文本生成过程。这有一个严重的问题就是,最后的状态不能记住长序列,也就是会遗忘信息,那么Decoder也就无法获得此信息。
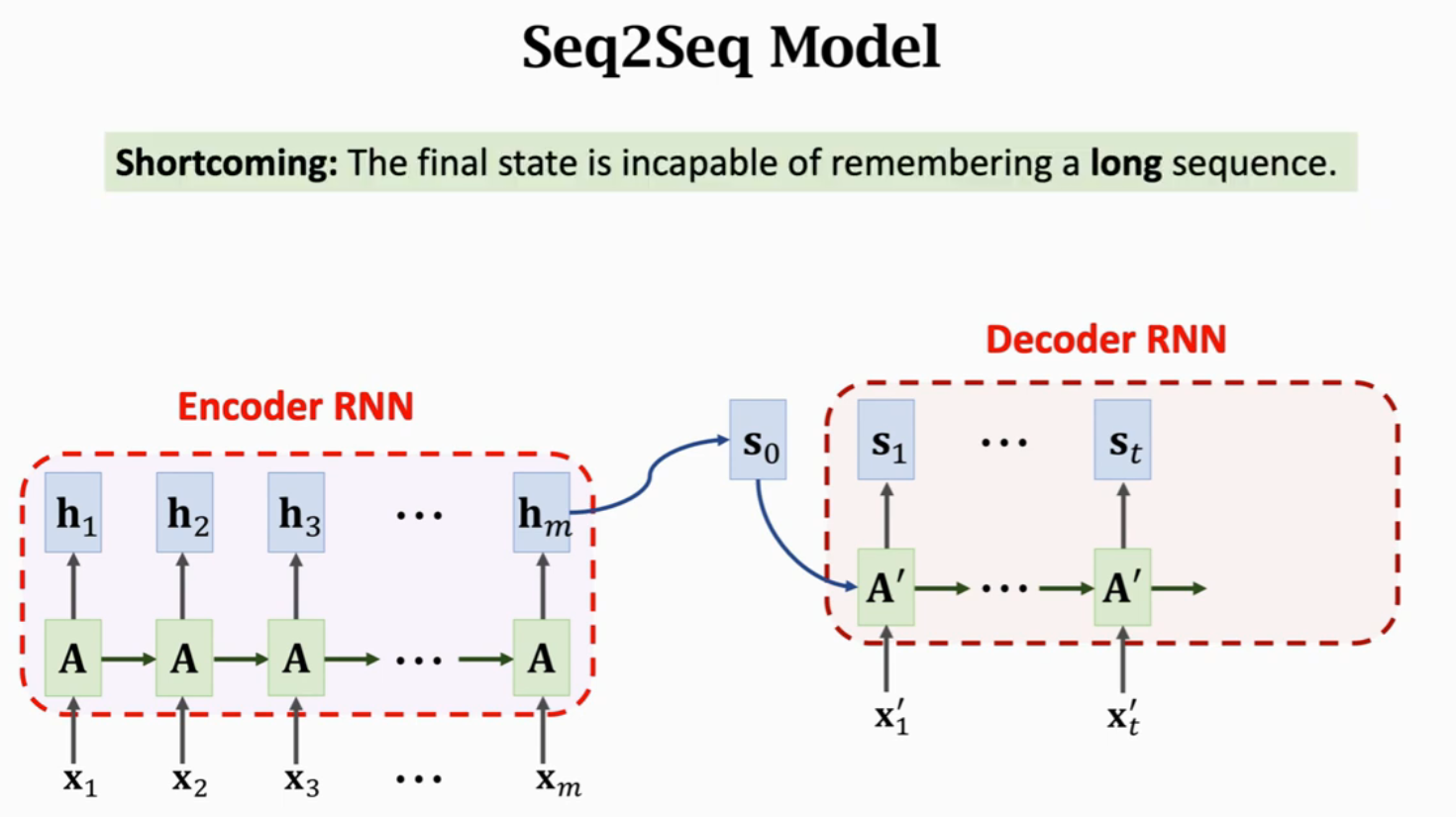
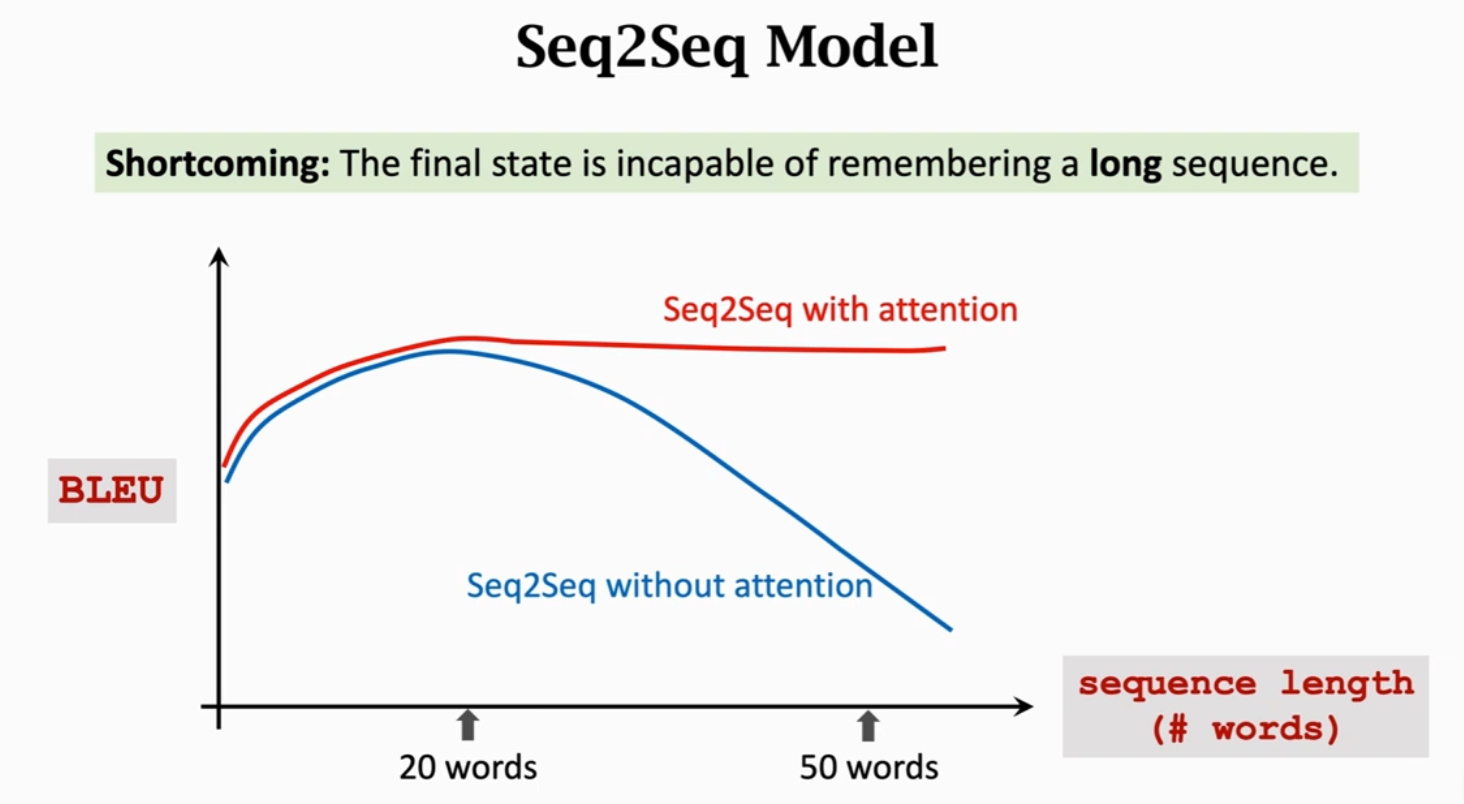
用传统的Seq2Seq模型,当句子长度超过20个单词是,BLEU Score(机器翻译评价指标)就会下降;但是如果用上Attention,就会如下图红色曲线一样,即使输入序列很长也能保持较高的准确率。
使用Attention解决机器翻译的原文为:Bahdanau, Cho, & Bengio, Neural machine translation by jointly learning to align and translate. In ICLR, 2015.
Attention能够极大提升Seq2Seq模型的准确率;用了Attention,Decoder每次更新状态的时候都会看一下Encoder的所有状态,这样子就不会遗忘了;Attention还可以告诉Decoder应该关注Encoder的哪个状态,这就是Attention名字的由来。Attention有一个极大的缺点是,计算量很大。
- Attention tremendously improves Seq2Seq model
- With attention, Seq2Seq model does not forget source input
- With attention, the decoder knows where to focus
- Downside: much more computation
Attention的原理
Attention使用\(c_i\)整合\(h_1, h_2, ..., h_m\)的信息,因此Attention机制可以解决LSTM遗忘的问题。
\(c_0 = \alpha_1h_1 + \alpha_2h_2 + ... + \alpha_mh_m\),其中,\(\alpha_i\)表示\(h_i\)和\(s_0\)的相关性,称为权重。

相关性的计算方法有两种:
方法一(Used in the original paper)
求\(h_i\)和\(s_0\)的相关性,将\(h_i\)和\(s_0\)进行Concatenate,然后乘一个参数矩阵\(W\),结果进行\(tanh\)约束到(-1, 1)之间,然后再乘以一个\(v^T\),并对得到的结果进行Softmax处理。
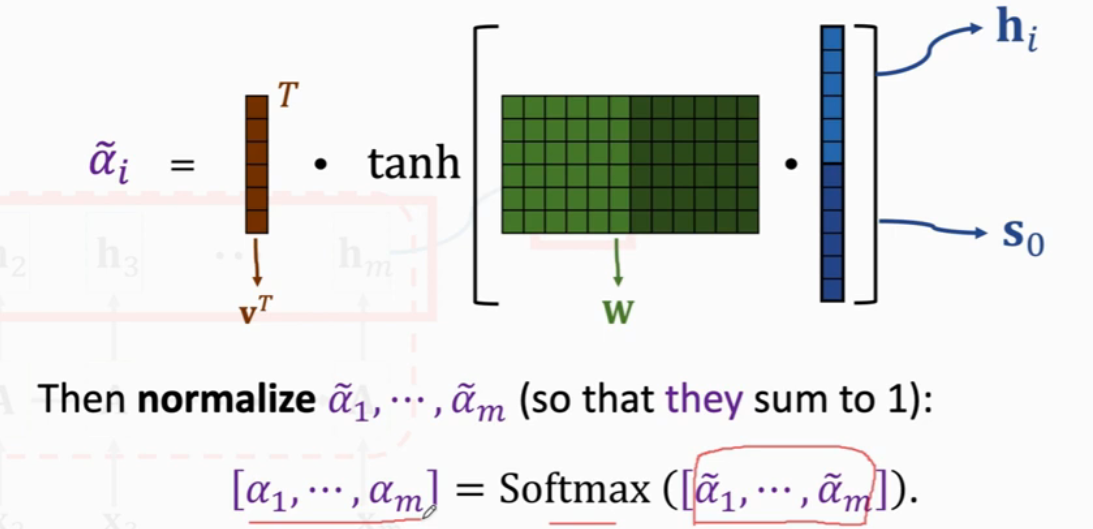
方法二(more popular,the same to Transformer)
求\(h_i\)和\(s_0\)的相关性,分为三步进行计算:
- Linear maps
- \(k_i = W_K · h_i\)
- \(q_0 = W_Q · s_0\)
- Inner product
- \(\widetilde{\alpha_i} = k^T_{i}q_0\)
- Normalization
- \([\alpha_1, ..., \alpha_m] = Softmax([\widetilde{\alpha_1}, ... \widetilde{\alpha_m}])\)
计算得到\(c_0\)后,将\(A'\)的三个输入进行concatenate,作为输入得到状态\(s_1\)。每一个状态\(s_i\)对应一个Context向量\(c_i\)来表示\(s_i\)与\(H\)的相关性。
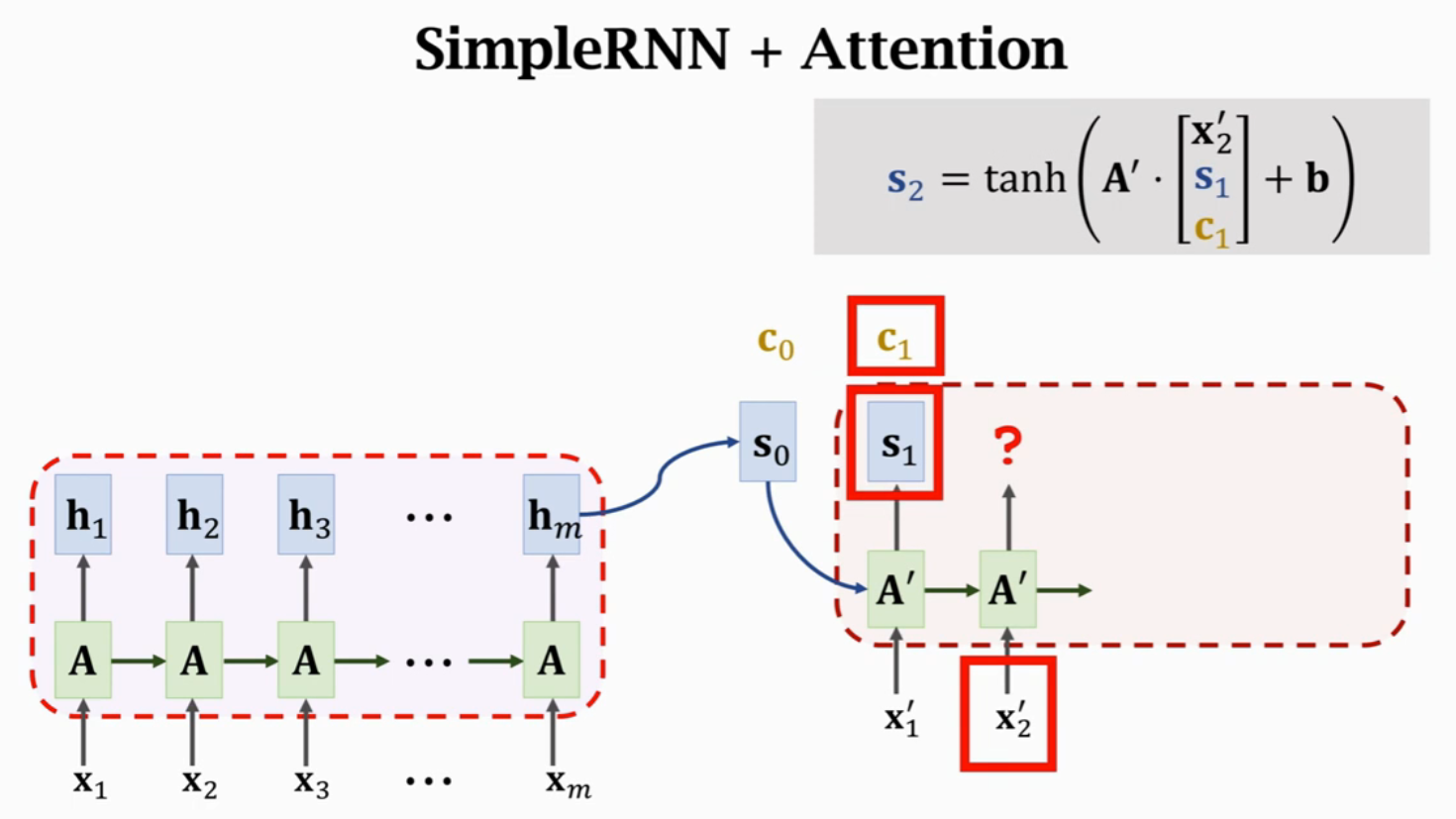
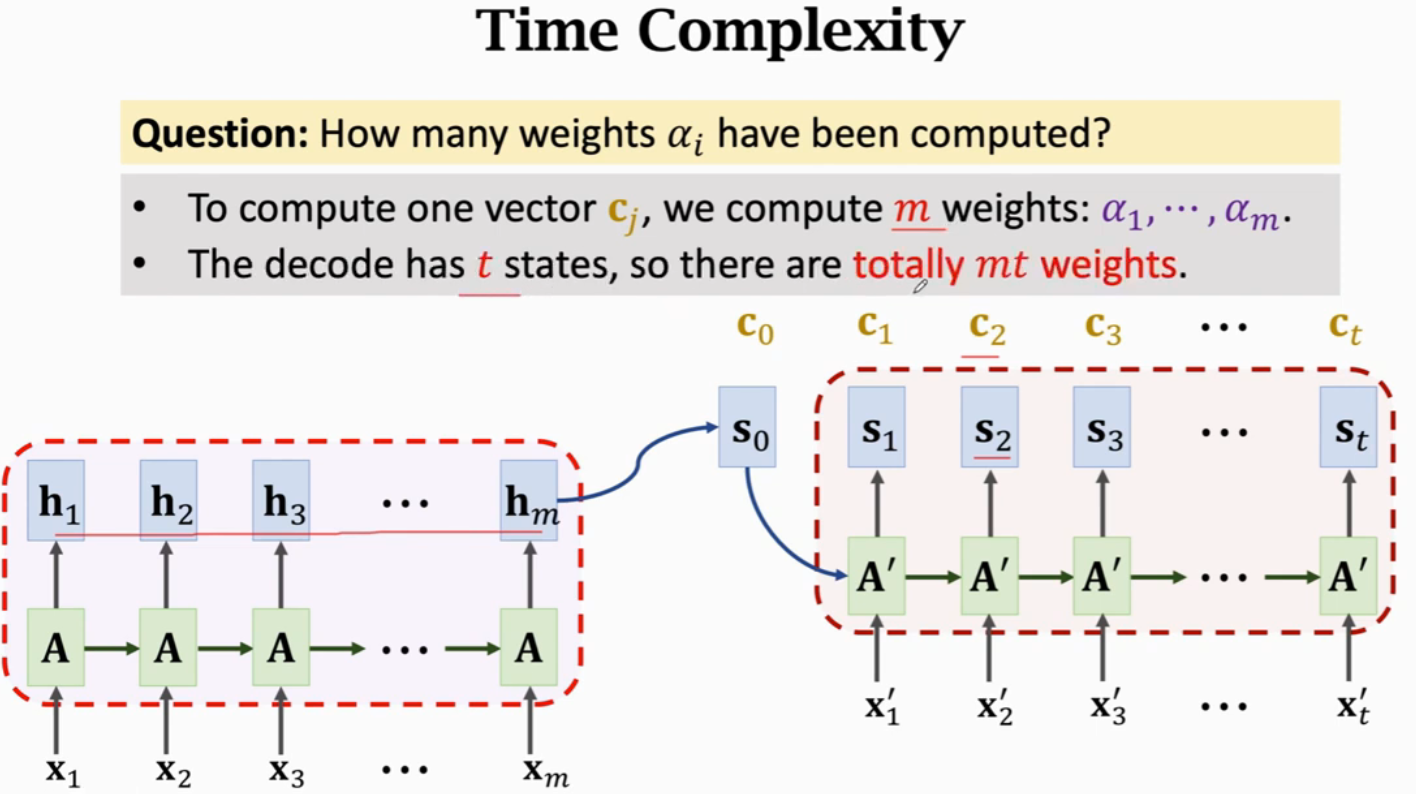
假设Encoder有m步,Decoder有t步,就需要计算mt次权重,每次权重计算都要计算m个\(\alpha\)的值。所以,Attention的时间复杂度是mt,也就是Encoder和Decoder状态数量的乘积。
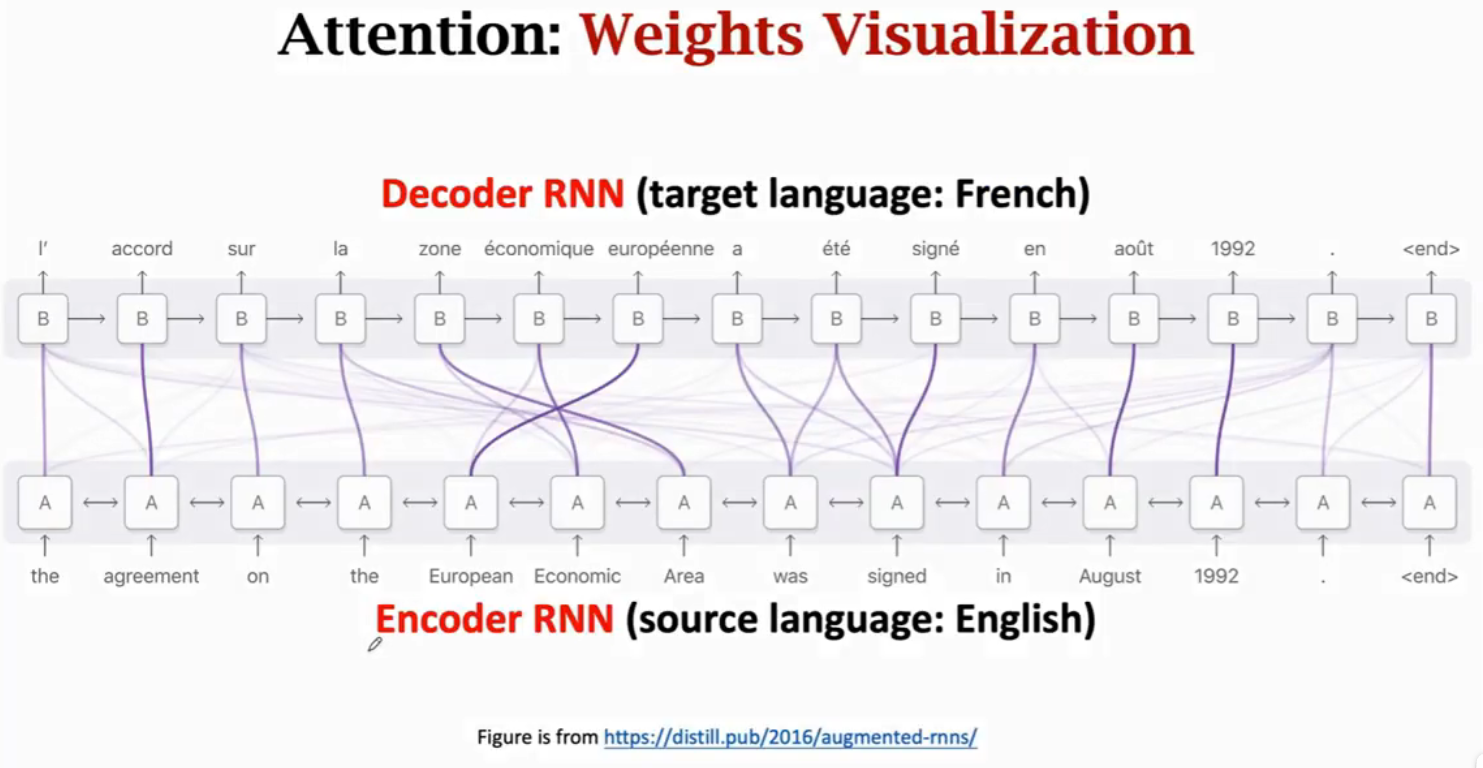
Attention在机器翻译任务的可视化,可以看到Decoder与Encoder的每个状态都相关,但是会重点关注某个或某些状态。
Summary
优点:
- Standard Seq2Seq model:decoder只关注其当前状态
- Attention:decoder还会关注encoders的所有状态解决遗忘问题并且告诉decoder哪里需要重点关注
缺点:高时间复杂度(假设源序列的长度为m,目标序列的长度是t)
- Standard Seq2Seq:\(O(m + t)\)
- Seq2Seq + attention:\(O(mt)\)
Self Attention
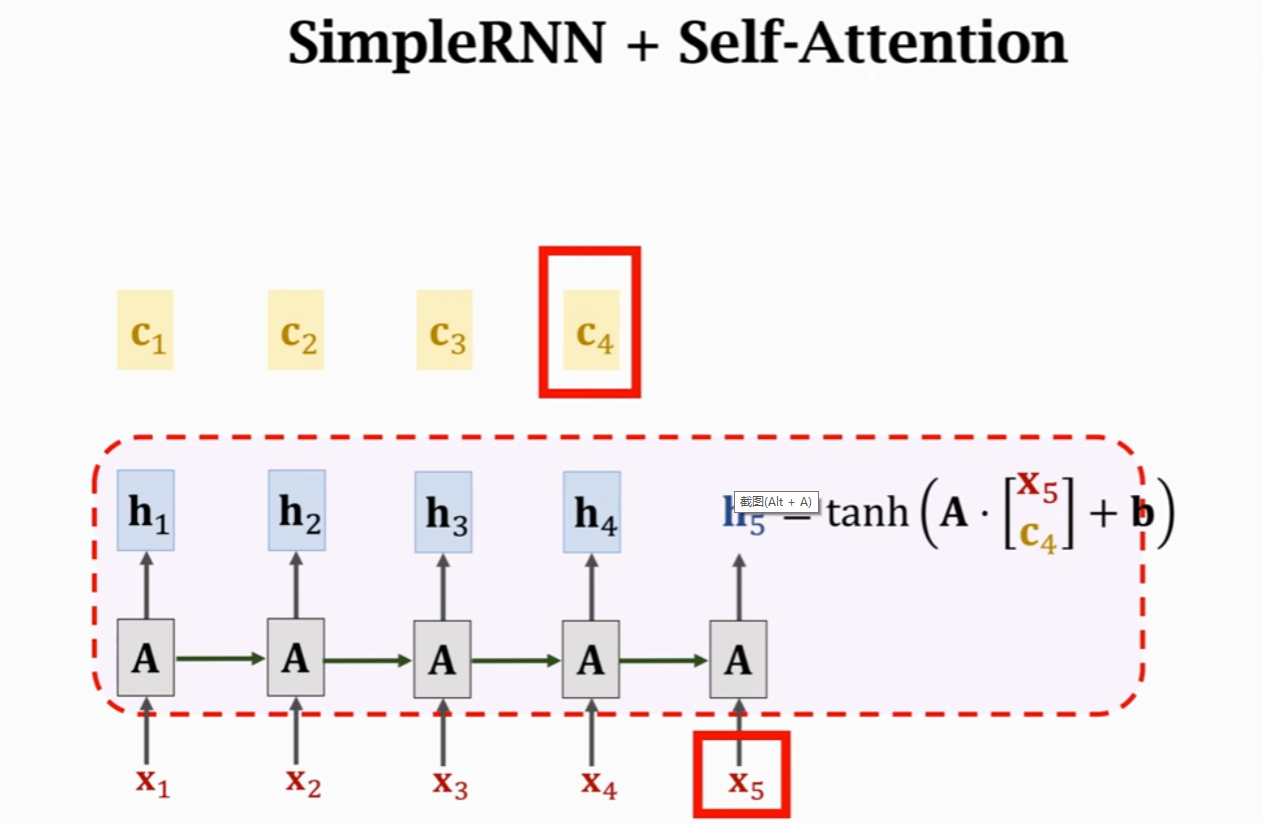
之前RNN里面,使用\(h_4\)和\(x_5\)计算得到\(h_5\),使用self-attention机制,当前状态\(h_5\)的计算依赖由\(h_4\)变为\(c_4\)。\(c_4 = \alpha_1h_1 + \alpha_2h_2 + \alpha_3h_3 + \alpha_4h_4\),其中,\(\alpha_i\)计算的是\(h_4\)与\(h_i\)之间的相关性,计算方式前面已经讲过。因为这里会计算自己与自己的相关性,因此称为self-attention。
SimpleRNN与Attention当前状态计算对比
SimpleRNN状态\(h_5\)的计算:
\(h_5 = tanh(A·{x_5\brack h_4} + b)\)
Self-Attention状态\(h_5\)的计算:
\(h_5 = tanh(A·{x_5\brack c_4} + b)\)
Reference
王树森Attention与Self-Attention学习笔记的更多相关文章
- 王树森Transformer学习笔记
目录 Transformer Attention结构 Self-Attention结构 Multi-head Self-Attention BERT:Bidirectional Encoder Rep ...
- SQL反模式学习笔记3 单纯的树
2014-10-11 在树形结构中,实例被称为节点.每个节点都有多个子节点与一个父节点. 最上层的节点叫做根(root)节点,它没有父节点. 最底层的没有子节点的节点叫做叶(leaf). 中间的节点简 ...
- SQL反模式学习笔记9 元数据分裂
目标:支持可扩展性.优化数据库的结构来提升查询的性能以及支持表的平滑扩展. 反模式:克隆表与克隆列 1.将一张很长的表拆分成多张较小的表,使用表中某一个特定的数据字段来给这些拆分出来的表命名. 2.将 ...
- SQL反模式学习笔记1 开篇
什么是“反模式” 反模式是一种试图解决问题的方法,但通常会同时引发别的问题. 反模式分类 (1)逻辑数据库设计反模式 在开始编码之前,需要决定数据库中存储什么信息以及最佳的数据组织方式和内在关联方式. ...
- SQL反模式学习笔记5 外键约束【不用钥匙的入口】
目标:简化数据库架构 一些开发人员不推荐使用引用完整性约束,可能不使用外键的原因有一下几点: 1.数据更新有可能和约束冲突: 2.当前的数据库设计如此灵活,以至于不支持引用完整性约束: 3.数据库为外 ...
- SQL反模式学习笔记2 乱穿马路
程序员通常使用逗号分隔的列表来避免在多对多的关系中创建交叉表, 将这种设计方式定义为一种反模式,称为“乱穿马路”. 目标: 存储多属性值,即多对一 反模式:将多个值以格式化的逗号分隔存储在一个字段中 ...
- SQL反模式学习笔记4 建立主键规范【需要ID】
目标:建立主键规范 反模式:每个数据库中的表都需要一个伪主键Id 在表中,需要引入一个对于表的域模型无意义的新列来存储一个伪值,这一列被用作这张表的主键, 从而通过它来确定表中的一条记录,即便其他的列 ...
- SQL反模式学习笔记6 支持可变属性【实体-属性-值】
目标:支持可变属性 反模式:使用泛型属性表.这种设计成为实体-属性-值(EAV),也可叫做开放架构.名-值对. 优点:通过增加一张额外的表,可以有以下好处 (1)表中的列很少: (2)新增属性时,不需 ...
- SQL反模式学习笔记7 多态关联
目标:引用多个父表 反模式:使用多用途外键.这种设计也叫做多态关联,或者杂乱关联. 多态关联和EAV有着相似的特征:元数据对象的名字是存储在字符串中的. 在多态关联中,父表的名字是存储在Issue_T ...
- SQL反模式学习笔记8 多列属性
目标:存储多值属性 反模式:创建多个列.比如一个人具有多个电话号码.座机号码.手机号码等. 1.查询:多个列的话,查询时可能不得不用IN,或者多个OR: 2.添加.删除时确保唯一性.判断是否有值:这些 ...
随机推荐
- 【MySQL】Tinyint 类型问题
下发字段: `DISTRIBUTION_STATUS` tinyint(1) DEFAULT '0' COMMENT '下发状态,0未下发,1已下发,2已作废', Mybatis封装之后日志打印也确实 ...
- 【转载】 Linux Hang Task 简介
原文地址: https://gohalo.me/post/linux-kernel-hang-task-panic-introduce.html --------------------------- ...
- python 中 ctypes 的使用尝试
最近在看Python的性能优化方面的文章,突然想起ctypes这个模块,对于这个模块一直不是很理解,不过再次看完相关资料有了些新的观点. ctypes 这个模块个人观点就是提供一个Python类型与C ...
- 讲师招募 | Apache SeaTunnel Meetup等你来秀!
2024年第三季度已经悄然开启,猛回头才发现今年的时日竟然已经过半!这半年又是在忙忙碌碌中度过,好在看着社区发展年中汇总的一串串数字,似乎都在预示着社区将在一条正确的轨道上,朝着好的方向继续发展.但又 ...
- 万字长文带你了解Java日志框架使用Java日志框架
大家好,我是晓凡 一.日志概念 日志的重要性不用我多说了,日志,简单来说就是记录. 用来记录程序运行时发生的事情.比如,程序启动了.执行了某个操作.遇到了问题等等,这些都可以通过日志记录下来. 想象一 ...
- CC2530系列课程 | IAR新建一个工程
之前录制了无线传感网综合项目实战课程,这个课程非常适合应届毕业生和想转行Linux的朋友,用来增加项目经验. 其中一部分内容是关于CC2530+zigbee的知识,后面会更新几篇关于cc2530的文章 ...
- [学习笔记]在不同项目中切换Node.js版本
@ 目录 使用 Node Version Manager (NVM) 安装 NVM 使用 NVM 安装和切换 Node.js 版本 为项目指定 Node.js 版本 使用环境变量指定 Node.js ...
- wiz 为知笔记服务器 docker 跨服务器迁移爬坑指北
本文主要是介绍 wiz 为知笔记服务器 docker 从旧服务器迁移到新服务器的步骤以及问题排查. 旧服务器升级 wiz docker 目的:保持和新服务器拉取的镜像版本一致. 官方只留了 wiz d ...
- Playwright 浏览器窗口最大化
实现方式 浏览器启动时,加参数 args=['--start-maximized']: 创建上下文时,加参数 no_viewport=True. from playwright.sync_api im ...
- 深度解析HarmonyOS SDK实况窗服务源码,Get不同场景下的多种模板
HarmonyOS SDK实况窗服务(Live View Kit)作为一个实时呈现应用服务信息变化的小窗口,遍布于设备的各个使用界面,它的魅力在于将复杂的应用场景信息简洁提炼并实时刷新,在不影响当前其 ...