线上问题排查--进程重启失败,最后发现是忘了cd
背景
我前面写了几篇文章,讲c3p0数据库连接池发生了连接泄露,但是随机出现,难以确定根因,最终呢,为了快速解决问题,我是先写了个shell脚本,脚本主要是检测服务的接口访问日志,看看过去的30s内是不是接口几乎都超时了,如果是的话,咱们就重启服务。然后把这个shell加入到了crontab里,每30s调度一次。

crontab如下(cron最小调度时间为分钟,所以搞了两条,以支持30s执行一次):
* * * * * /bin/sh /xxx/xxx/check_service_block_gbk.sh
* * * * * sleep 30; /xxx/xxx/check_service_block_gbk.sh
脚本的内容大概如下,:
计算过去n秒内异常请求的次数
...
如果异常请求超过某个阈值,重启服务
if [ "${error_req_count_sum}" -gt ${THRESHOLD_FOR_ERROR_REQ_IN_LAST_N_SECONDS} ];then
log "trigger restart, start restart"
"${SERVICE_ROOT_PATH}"/run.sh stopall
"${SERVICE_ROOT_PATH}"/run.sh startall
log "finish restart,finish current check"
else
log "no need restart,finish current check"
fi
这个脚本上线有半个多月了,这期间问题一直没复现,结果,昨天下午,运维同事和我说,用户反馈app出问题了,也就是问题复现了,但是,我那个脚本吧,好像有问题,现象就是,异常进程是结束了,但是,却没有启动起来,导致这期间服务完全宕了,最后还是他手动启动起来的。
现场排查
由于事情是事后他和我说的,我过去后也就是一起看了下日志,发现服务的访问日志确实是中断了2分钟(就是服务被脚本干掉后,没启动起来的真空期)。而shell脚本呢,在如下几行中:
function log()
{
now=$(date "+%Y-%m-%d %H:%M:%S")
echo -e "$now : $*"
echo "$now : $*" >> "${SERVICE_ROOT_PATH}"/check_service_block_gbk.log
}
log "trigger restart, start restart"
"${SERVICE_ROOT_PATH}"/run.sh stopall
"${SERVICE_ROOT_PATH}"/run.sh startall
log "finish restart,finish current check"
当时脚本写得不算很完备,只有log的那两行有日志,真正执行停止服务和启动服务的run.sh的执行,日志都打到console去了,日志文件里完全没有:
"trigger restart, start restart"
"finish restart,finish current check"
所以啊,毕竟还是不够专业,应该把脚本的标准输出重定向到日志文件的。
另外,根据脚本和现象,确定是执行了/run.sh stopall的,毕竟服务都没了嘛。
我们这个服务的框架很老,但也还比较稳定,框架自带的脚本就是上面看到的那个run.sh,这个run.sh呢,执行run.sh startall,会启动3个服务。
- 一个是服务本身
- 再一个是一个定时重启脚本,脚本里是一个死循环,每次循环就是检测是否到指定时间了,如果到了,就重启服务;没到,就sleep 1s;
- 另一个也是一个watchdog脚本,脚本里是一个死循环,每次循环就是检测服务还在不在,不在了就把服务拉起来
这几个服务一启动后,就会在当前目录下,生成几个pid文件:
- 服务本身,不生成pid文件,停止时就靠服务名去ps -ef|grep来查找
- 定时重启脚本,生成pid到reset.pid这个文件
- watchdog脚本,生成pid到watchdog.pid这个文件
而停止的时候run.sh stopall,就会根据上面的几种方法去找到对应的pid来kill。然后这几个服务的框架是支持kill -9这种暴力杀服务的,所以,几个服务被stop了,日志里是一点信息没有;然后呢,既然你说服务没启动起来,难道启动日志也没有嘛?问题是,还真的没有,空空如也,正常的话,自然是有的。但是我们可能就是执行run.sh startall时,报错可能都写到标准输出了,自然就没记录到日志里。
当时看到的东西,差不多就是这些。
本地复现
有的人会说,感觉这脚本没测试,直接就上线了,我可以这么说,测试,肯定是测了的,本地运行shell,都能把服务重启起来;但是,把脚本放到crontab里面后,倒是没有测试过这个分支。
这两个脚本是在同一目录下:
[root@xxxx]# ll check_service_block_gbk.sh run.sh
-rwxr-xr-x 1 root root 3498 Aug 1 08:50 check_service_block_gbk.sh
-rwxr-xr-x 1 root root 11425 Aug 1 10:51 run.sh
我当时测试的时候,在本地测是通过如下命令,一点问题没有:
./check_service_block_gbk.sh
结果这次上线又出了这个,我就想着在本地复现下,弄到cron里去触发,没想到,还真的和线上一样,服务被stop了,但是并没有重启起来。
我先是crontab -e加了日志,把脚本的标准输出重定向到文件/root/cron.log:
* * * * * /bin/sh -x /foo/bar/check_service_block_gbk.sh >> /root/cron.log 2>&1
然后触发了一次后,去查看shell执行日志/root/cron.log,发现,在执行startall时,nohup启动服务的地方,看着有点怪:
+ nohup /foo/bar/TBAServer
这个TBAServer是个二进制,就是我们的后台服务。我当时,为啥感觉有点怪呢,因为run.sh中,nohup那一行如下:
nohup $SERVER_PATH >> ${SERVER_DIR}/stdout.txt 2>&1 &
我们脚本里,后面还有>> xxx/stdout.txt 2>&1 &这些,为啥在shell -x的执行log里没有呢?
当时以为找到了问题,结果后来,我正常在shell中如下执行:
sh -x check_service_block_gbk.sh
发现执行日志也是一样的,看起来不是这个的问题。
然后左查右查,搞了好久,反正昨晚没弄出来,然后早上上班的时候,在互联网上关键字找了下,好像也没有类似的问题,只看到说,在cron执行的话,环境变量和在shell中执行不一样,不过我还没来得及测试环境变量这块,就有了新发现。
换机测试,柳暗花明
由于昨晚那台本地拿来复现的机器,白天用的人较多,为了不影响别人,我就换了台机器,没想到,换到新机器后测试时,在shell的执行日志中看到了关键日志:
+ nohup /foo/bar/TBAServer
...
启动路径不是进程所在路径,系统无法正常运行
看到这个,我大概就知道是啥原因了,为啥这个关键日志,在昨晚的机器没有呢,是因为二进制文件的版本不同,我今天这台机器上的二进制,版本更新。
看到这个错误,我大概猜测是进程的current working directory的问题,于是我修改了下run.sh,打印pwd。
echo cwd: "$PWD" ---增加的一行
nohup $SERVER_PATH >> ${SERVER_DIR}/stdout.txt 2>&1 &
然后,分别测试在shell下正常运行和通过crontab运行:
crontab时,
cwd: /root
shell正常运行时:
cwd: /foo/bar
虽然已基本确认问题,我还是进一步检验了一下,为啥二进制文件里会报那个错误,我用IDA对那个二进制反编译了一下,(只能看懂一点,非常勉强)。
问题根源
里面有如下代码:
if ( !IsStartFromPFPath() )
{
OUT(byte_4AB1C0);
exit(1);
}
这里调用了一个函数,大意是是否从xxx路径启动,不是的话,就会输出一个信息,然后exit。
这个输出的信息,我找了下,确实就是日志里那句。

接下来,我们进函数一览,现在看c++已经非常吃力了,只能看个大概:
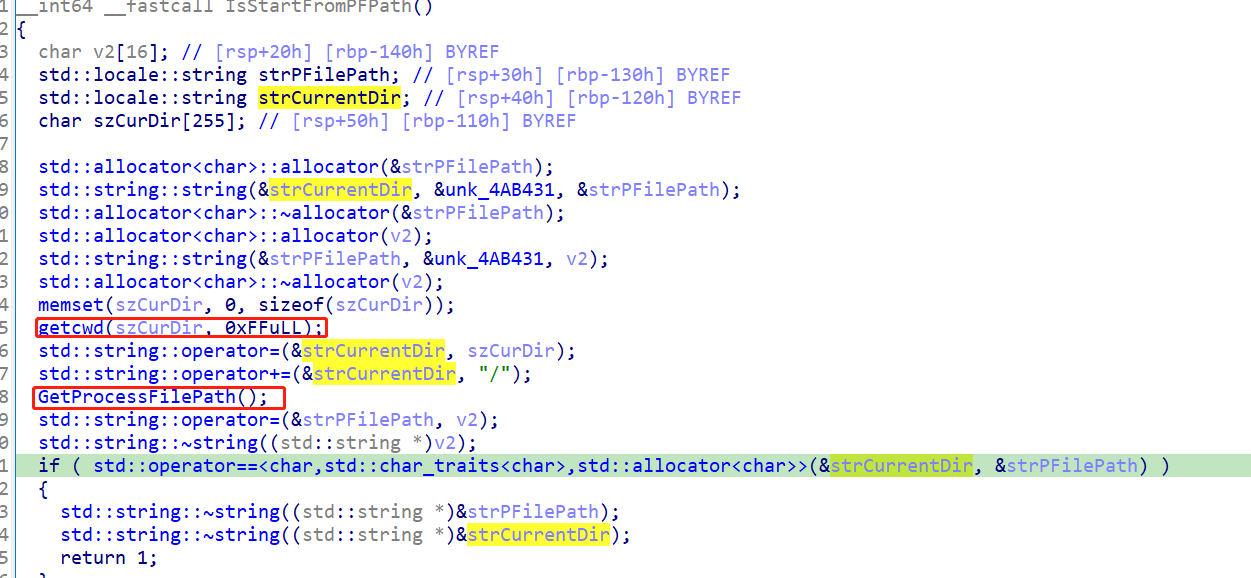
这里面调用了另外两个函数,一个是获取进程的cwd(当前工作目录),一个是获取进程文件的路径,然后做比较,看看是否一致。
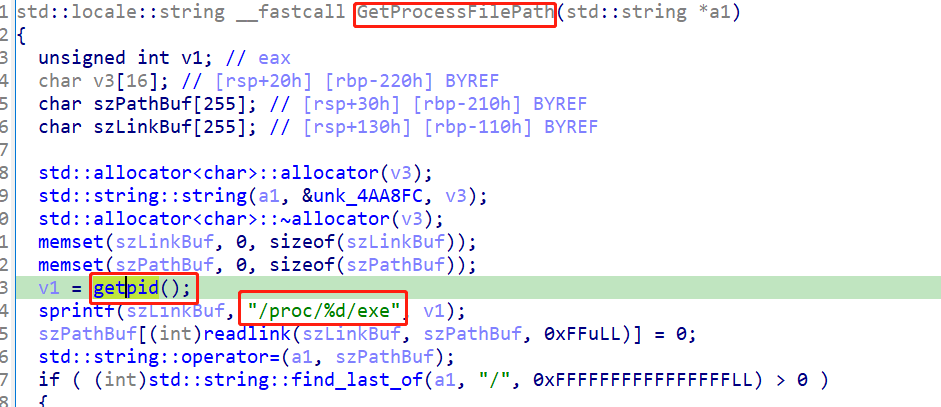
这个获取进程文件路径的函数,如上,我们结合猜测,应该就是获取二进制文件TBAServer的位置。
而,我们在cron执行时,cwd为/root,而TBAServer的位置为/foo/bar/TBAServer,这两个路径,明显不一致,所以,最终报了那个错误,导致启动失败。
为了进一步确认以上猜想,我准备使用strace命令,来看看启动这个TBAServer时,到底进行了哪些系统调用?
我改了run.sh,如下:
echo cwd: "$PWD"
nohup strace -q -f -s 200 $SERVER_PATH 2>&1 & >> ${SERVER_DIR}/stdout.txt
strace命令的强大毋庸置疑,可以跟踪系统调用,很多难题都能迎刃而解。下图也确认了我们的代码分析的结论。

问题解决
知道是cwd的问题了,那就解决吧,解决的办法就是要将工作目录切换到正确的目录,我采用的方法是直接在crontab这里修改。
* * * * * cd /foo/bar; /bin/sh -x /foo/bar/check_service_block_gbk.sh
有一个小问题是,这里我就没再将执行日志重定向了,也就是去掉了下面这部分。因为我发现服务运行时的日志也会打印进去,到时候日志就打了两份了。暂时还没去想怎么解决。
>> /root/cron.log 2>&1
下午的时候,到运维同事那边试了试,运行很平稳,检测到异常就可以自动重启了,终于可以了了这个事了。
参考文章
关于cron环境变量问题的文章:
https://mp.weixin.qq.com/s/Qafz20Mum51yY7OjfRpywA
https://mp.weixin.qq.com/s/9dWlgS4YslC6MnXbF2E8rw
线上问题排查--进程重启失败,最后发现是忘了cd的更多相关文章
- 线上服务Java进程假死快速排查、分析
引用 https://zhuanlan.zhihu.com/p/529350757 最近我们有一台服务器上的Java进程总是在运行个两三天后就无法响应请求了,具体现象如下: 请求业务返回状态码502, ...
- Java线上问题排查神器Arthas实战分析
概述 背景 是不是在实际开发工作当中经常碰到自己写的代码在开发.测试环境行云流水稳得一笔,可一到线上就经常不是缺这个就是少那个反正就是一顿报错抽风似的,线上调试代码又很麻烦,让人头疼得抓狂:而且deb ...
- Java架构师线上问题排查,这些命令程序员一定用得到!
Java架构师线上问题排查,这些命令程序员一定用得到! 线上问题排查,以下场景,你遇到过吗? 一.了解机器连接数情况 问题:1.2.3.4的sshd的监听端口是22,如何统计1.2.3.4的sshd服 ...
- Arthas常用功能及一次线上问题排查
一.Arthas简介 Arthas是Alibaba开源的Java诊断工具,功能很强大,它是通过Agent方式来连接运行的Java进程.主要通过交互式来完成功能. https://arthas.aliy ...
- Java线上问题排查思路及Linux常用问题分析命令学习
前言 之前线上有过一两次OOM的问题,但是每次定位问题都有点手足无措的感觉,刚好利用星期天,以测试环境为模版来学习一下Linux常用的几个排查问题的命令. 也可以帮助自己在以后的工作中快速的排查线上问 ...
- 线上问题排查神器 Arthas
线上问题排查神器 Arthas 之前介绍过 BTrace,线上问题排查神器 BTrace 的使用,也说它是线上问题排查神器.都是神器,但今天这个也很厉害,是不是更厉害不好说,但是使用起来非常简单.如果 ...
- JVM 线上故障排查基本操作--CPU飙高
JVM 线上故障排查基本操作 CPU 飚高 线上 CPU 飚高问题大家应该都遇到过,那么如何定位问题呢? 思路:首先找到 CPU 飚高的那个 Java 进程,因为你的服务器会有多个 JVM 进程.然后 ...
- JVM 线上故障排查
JVM 线上故障排查 Linux 1.1 CPU 1.2 内存 1.3 存储 1.4 网络 一.CPU 飚高 寻找原因 二.内存问题排查 三.一般排查问题的方法 四.应用场景举例 4.1 怎么查看某个 ...
- BTrace:线上问题排查工具
BTrace简介 GitHub地址:BTrace 下载地址:v1.3.11.3 官方使用教程:Btrace使用教程 使用场景 BTrace 是一个事后工具,所谓事后工具就是在服务已经上线了,但是发现存 ...
- 记一次线上bug排查-quartz线程调度相关
记一次线上bug排查,与各位共同探讨. 概述:使用quartz做的定时任务,正式生产环境有个任务延迟了1小时之久才触发.在这一小时里各种排查找不出问题,直到延迟时间结束了,该任务才珊珊触发.原因主要就 ...
随机推荐
- Unity中实现字段/枚举编辑器中显示中文(中文枚举、中文标签)
在unity开发编辑器相关经常会碰到定义的字段显示在Inspector是中文,枚举也经常碰到显示的是字段定义时候的英文,程序还好,但是如果编辑器交给策划编辑,策划的英文水平不可保证,会很头大,所以还是 ...
- 【Python基础】字符串的基本使用
b6f9d807-edb2-4e0a-b554-fae322343bee 字符串是Python中最基本的数据类型之一.它是由一系列字符组成的不可变序列.这意味着一旦创建了一个字符串,就不能直接修改它的 ...
- 【Vue3】引入组件Failed to resolve component: MyButton If this is a native custom element
引入组件时页面上并没有出现组件的影子,其他元素正常,初步确定是组件引入部分语法出了问题,打开开发者工具看到控制台报出错误代码: Failed to resolve component: MyButto ...
- python中的一些解码和编码
开头 最近爬取百度贴吧搜索页的时候遇到一个url的编码问题,颇为头疼,记录下来防止下次忘记 工具网站 解码编码的工具网站推荐 http://tool.chinaz.com/tools/urlencod ...
- 2020-12-13:用最少数量的线程,每个线程执行for的空循环,把cpu打满了。如果在for的空循环里添加打印输出函数,会把cpu打满吗?为什么?
福哥答案2020-12-13:不会.输出会进行io操作,相对于CPU的速度,这是一个非常缓慢的过程,所以CPU会有机会空闲下来.***[评论](https://user.qzone.qq.com/31 ...
- Simple Date Format类到底为啥不是线程安全的?
摘要:我们就一起看下在高并发下Simple Date Format类为何会出现安全问题,以及如何解决Simple Date Format类的安全问题. 本文分享自华为云社区<[高并发]Simpl ...
- Galaxy 生信平台(三):xlsx 上传与识别
我在<Firefox Quantum 向左,Google Chrome 向右>中,曾经吐槽过在 Firefox 中使用 Galaxy 上传本地的 Excel 文件时,会出现 xlsx 无法 ...
- 10.5. 版本控制(如Git)
版本控制系统(Version Control System,VCS)是软件开发过程中用于管理源代码的工具.它可以帮助你跟踪代码的变更历史,方便回滚到之前的版本,以及协同多人共同开发.Git是当前最流行 ...
- KeyChrone-K8使用体验
盛名之下,其实难副.我是这应该是我对K8的初上手体验.抛开Mac的使用者,我想其他人应该很难对这款键盘爱得起来.一直以来对手头的Filco的有线比较介意,想换个无线键盘.因为平时调程序比较多,所以F功 ...
- 数据库中的可视化和探索性:MongoDB的数据可视化和探索性工具
目录 1. 引言 2. 技术原理及概念 2.1 基本概念解释 2.2 技术原理介绍 2.3 相关技术比较 3. 实现步骤与流程 3.1 准备工作:环境配置与依赖安装 3.2 核心模块实现 3.3 集成 ...