汽车之家:基于 Flink + Iceberg 的湖仓一体架构实践
简介: 由汽车之家实时计算平台负责人邸星星在 4 月 17 日上海站 Meetup 分享的,基于 Flink + Iceberg 的湖仓一体架构实践。
内容简要:
一、数据仓库架构升级的背景
二、基于 Iceberg 的湖仓一体架构实践
三、总结与收益
四、后续规划
一、数据仓库架构升级的背景
1. 基于 Hive 的数据仓库的痛点
原有的数据仓库完全基于 Hive 建造而成,主要存在三大痛点:
痛点一:不支持 ACID
1)不支持 Upsert 场景;
2)不支持 Row-level delete,数据修正成本高。
痛点二:时效性难以提升
1)数据难以做到准实时可见;
2)无法增量读取,无法实现存储层面的流批统一;
3)无法支持分钟级延迟的数据分析场景。
痛点三:Table Evolution
1)写入型 Schema,对 Schema 变更支持不好;
2)Partition Spec 变更支持不友好。
2. Iceberg 关键特性
Iceberg 主要有四大关键特性:支持 ACID 语义、增量快照机制、开放的表格式和流批接口支持。
支持 ACID 语义
- 不会读到不完整的 Commit;
- 基于乐观锁支持并发 Commit;
- Row-level delete,支持 Upsert。
增量快照机制
- Commit 后数据即可见(分钟级);
- 可回溯历史快照。
开放的表格式
- 数据格式:parquet、orc、avro
- 计算引擎:Spark、Flink、Hive、Trino/Presto
流批接口支持
- 支持流、批写入;
- 支持流、批读取。
二、基于 Iceberg 的湖仓一体架构实践
湖仓一体的意义就是说我不需要看见湖和仓,数据有着打通的元数据的格式,它可以自由的流动,也可以对接上层多样化的计算生态。
——贾扬清(阿里云计算平台高级研究员)
1. Append 流入湖的链路
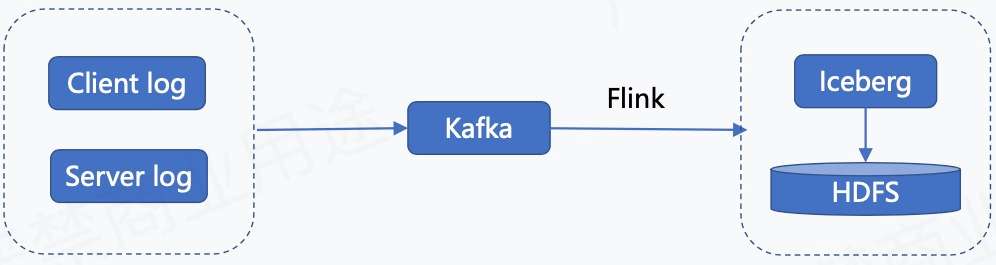
上图为日志类数据入湖的链路,日志类数据包含客户端日志、用户端日志以及服务端日志。这些日志数据会实时录入到 Kafka,然后通过 Flink 任务写到 Iceberg 里面,最终存储到 HDFS。
2. Flink SQL 入湖链路打通
我们的 Flink SQL 入湖链路打通是基于 “Flink 1.11 + Iceberg 0.11” 完成的,对接 Iceberg Catalog 我们主要做了以下内容:
1)Meta Server 增加对 Iceberg Catalog 的支持;
2)SQL SDK 增加 Iceberg Catalog 支持。
然后在这基础上,平台开放 Iceberg 表的管理功能,使得用户可以自己在平台上建 SQL 的表。
3. 入湖 - 支持代理用户
第二步是内部的实践,对接现有预算体系、权限体系。
因为之前平台做实时作业的时候,平台都是默认为 Flink 用户去运行的,之前存储不涉及 HDFS 存储,因此可能没有什么问题,也就没有思考预算划分方面的问题。
但是现在写 Iceberg 的话,可能就会涉及一些问题。比如数仓团队有自己的集市,数据就应该写到他们的目录下面,预算也是划到他们的预算下,同时权限和离线团队账号的体系打通。

如上所示,这块主要是在平台上做了代理用户的功能,用户可以去指定用哪个账号去把这个数据写到 Iceberg 里面,实现过程主要有以下三个。
- 增加 Table 级别配置:'iceberg.user.proxy' = 'targetUser’
1)启用 Superuser
2)团队账号鉴权

- 访问 HDFS 时启用代理用户:
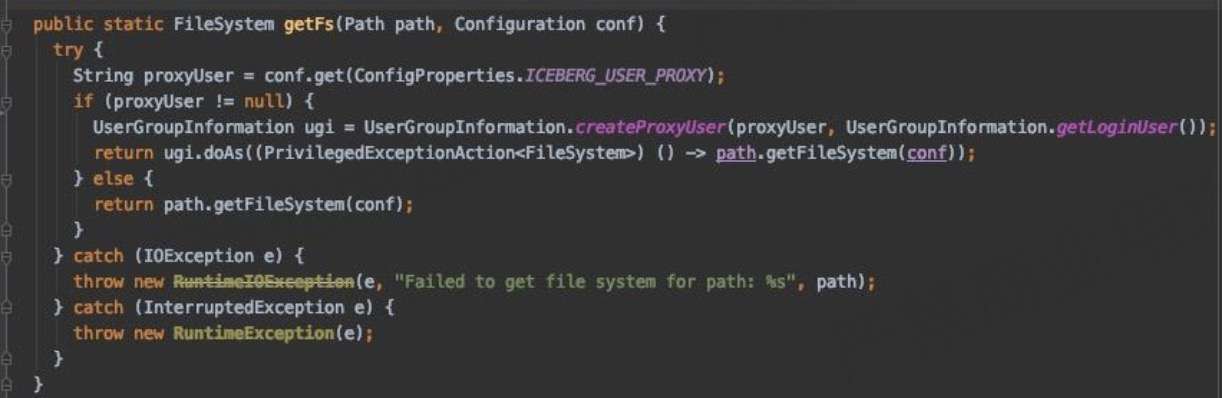
- 访问 Hive Metastore 时指定代理用户
1)参考 Spark 的相关实现:
org.apache.spark.deploy.security.HiveDelegationTokenProvider
2)动态代理 HiveMetaStoreClient,使用代理用户访问 Hive metastore
4. Flink SQL 入湖示例
DDL + DML

5. CDC 数据入湖链路
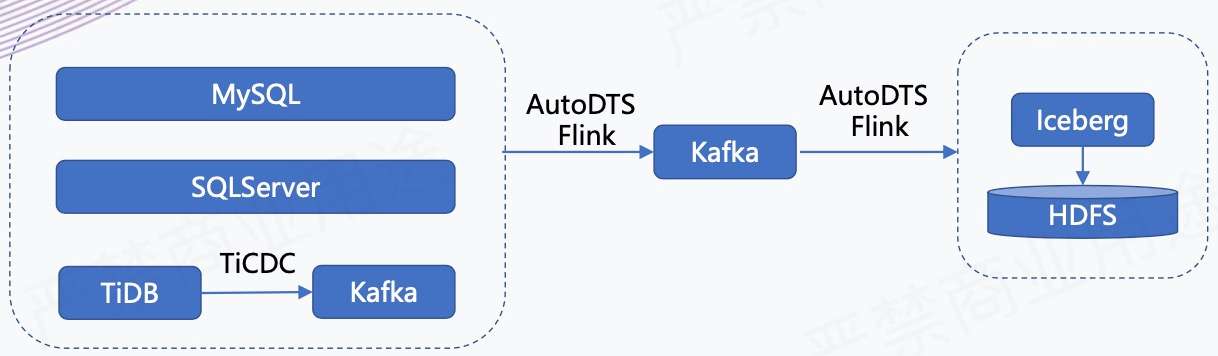
如上所示,我们有一个 AutoDTS 平台,负责业务库数据的实时接入。我们会把这些业务库的数据接入到 Kafka 里面,同时它还支持在平台上配置分发任务,相当于把进 Kafka 的数据分发到不同的存储引擎里,在这个场景下是分发到 Iceberg 里。
6. Flink SQL CDC 入湖链路打通
下面是我们基于 “Flink1.11 + Iceberg 0.11” 支持 CDC 入湖所做的改动:
- 改进 Iceberg Sink:
Flink 1.11 版本为 AppendStreamTableSink,无法处理 CDC 流,修改并适配。
- 表管理
1)支持 Primary key(PR1978)
2)开启 V2 版本:'iceberg.format.version' = '2'
7. CDC 数据入湖
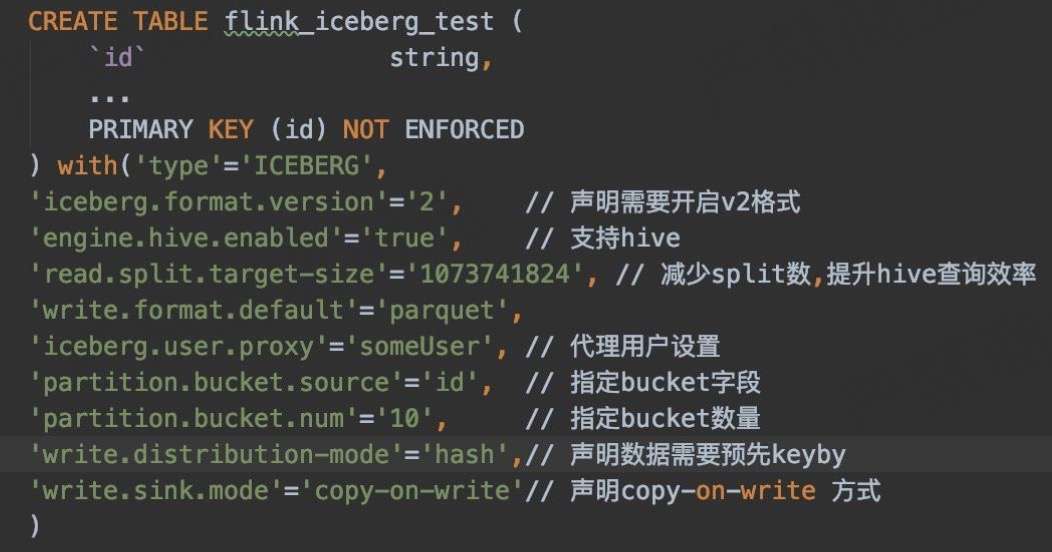
1. 支持 Bucket
Upsert 场景下,需要确保同一条数据写入到同一 Bucket 下,这又如何实现?
目前 Flink SQL 语法不支持声明 bucket 分区,通过配置的方式声明 Bucket:
'partition.bucket.source'='id', // 指定 bucket 字段
'partition.bucket.num'='10', // 指定 bucket 数量
2. Copy-on-write sink
做 Copy-on-Write 的原因是原本社区的 Merge-on-Read 不支持合并小文件,所以我们临时去做了 Copy-on-write sink 的实现。目前业务一直在测试使用,效果良好。
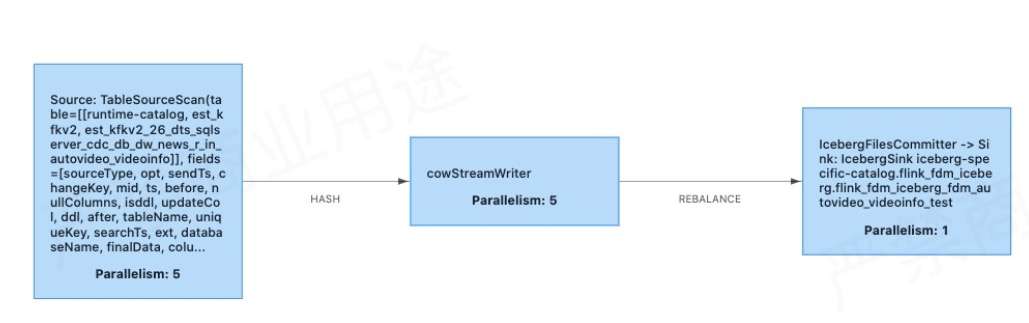
上方为 Copy-on-Write 的实现,其实跟原来的 Merge-on-Read 比较类似,也是有 StreamWriter 多并行度写入和 FileCommitter 单并行度顺序提交。
在 Copy-on-Write 里面,需要根据表的数据量合理设置 Bucket 数,无需额外做小文件合并。
- StreamWriter 在 snapshotState 阶段多并行度写入
1)增加 Buffer;
2)写入前需要判断上次 checkpoint 已经 commit 成功;
3)按 bucket 分组、合并,逐个 Bucket 写入。
- FileCommitter 单并行度顺序提交
1)table.newOverwrite()
2)Flink.last.committed.checkpoint.id
8. 示例 - CDC 数据配置入湖

如上图所示,在实际使用中,业务方可以在 DTS 平台上创建或配置分发任务即可。
实例类型选择 Iceberg 表,然后选择目标库,表明要把哪个表的数据同步到 Iceberg 里,然后可以选原表和目标表的字段的映射关系是什么样的,配置之后就可以启动分发任务。启动之后,会在实时计算平台 Flink 里面提交一个实时任务,接着用 Copy-on-write sink 去实时地把数据写到 Iceberg 表里面。
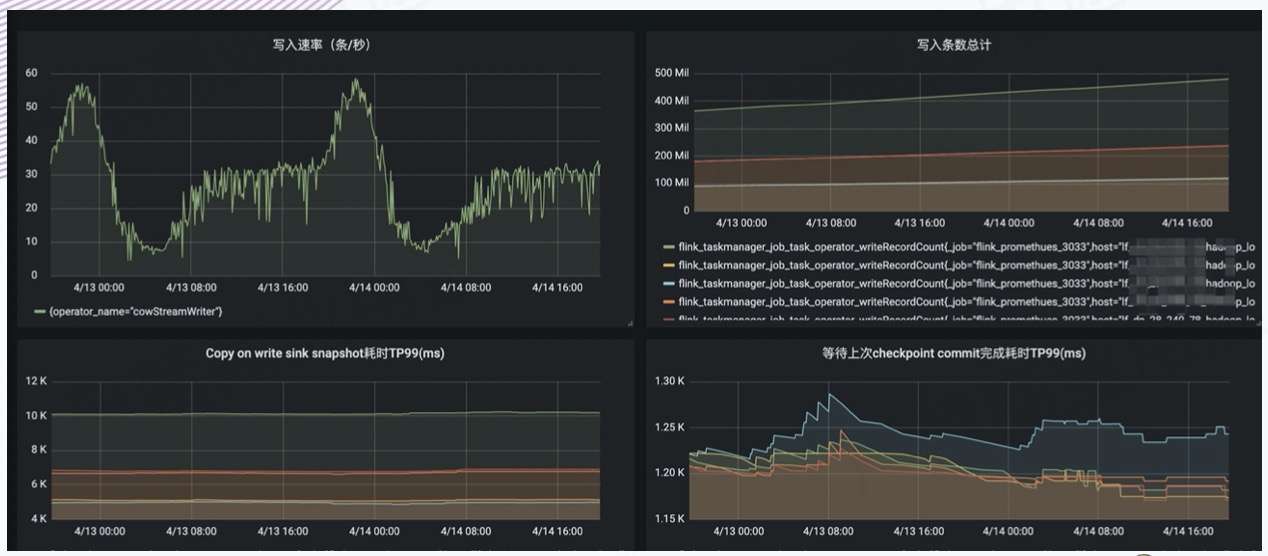
9. 入湖其他实践
实践一:减少 empty commit
- 问题描述:
在上游 Kafka 长期没有数据的情况下,每次 Checkpoint 依旧会生成新的 Snapshot,导致大量的空文件和不必要的 Snapshot。
- 解决方案(PR - 2042):
增加配置 Flink.max-continuousempty-commits,在连续指定次数 Checkpoint 都没有数据后才真正触发 Commit,生成 Snapshot。
实践二:记录 watermark
- 问题描述:
目前 Iceberg 表本身无法直接反映数据写入的进度,离线调度难以精准触发下游任务。
- 解决方案( PR - 2109 ):
在 Commit 阶段将 Flink 的 Watermark 记录到 Iceberg 表的 Properties 中,可直观的反映端到端的延迟情况,同时可以用来判断分区数据完整性,用于调度触发下游任务。
实践三:删表优化
- 问题描述:
删除 Iceberg 可能会很慢,导致平台接口相应超时。因为 Iceberg 是面向对象存储来抽象 IO 层的,没有快速清除目录的方法。
- 解决方案:
扩展 FileIO,增加 deleteDir 方法,在 HDFS 上快速删除表数据。
10. 小文件合并及数据清理
定期为每个表执行批处理任务(spark 3),分为以下三个步骤:
1. 定期合并新增分区的小文件:
rewriteDataFilesAction.execute(); 仅合并小文件,不会删除旧文件。
2. 删除过期的 snapshot,清理元数据及数据文件:
table.expireSnapshots().expireOld erThan(timestamp).commit();
3. 清理 orphan 文件,默认清理 3 天前,且无法触及的文件:
removeOrphanFilesAction.older Than(timestamp).execute();
11. 计算引擎 – Flink
Flink 是实时平台的核心计算引擎,目前主要支持数据入湖场景,主要有以下几个方面的特点。
- 数据准实时入湖:
Flink 和 Iceberg 在数据入湖方面集成度最高,Flink 社区主动拥抱数据湖技术。
- 平台集成:
AutoStream 引入 IcebergCatalog,支持通过 SQL 建表、入湖 AutoDTS 支持将 MySQL、SQLServer、TiDB 表配置入湖。
- 流批一体:
在流批一体的理念下,Flink 的优势会逐渐体现出来。
12. 计算引擎 – Hive
Hive 在 SQL 批处理层面 Iceberg 和 Spark 3 集成度更高,主要提供以下三个方面的功能。
- 定期小文件合并及 meta 信息查询:
SELECT * FROM prod.db.table.history 还可查看 snapshots, files, manifests。
- 离线数据写入:
1)Insert into 2)Insert overwrite 3)Merge into
- 分析查询:
主要支持日常的准实时分析查询场景。
13. 计算引擎 – Trino/Presto
AutoBI 已经和 Presto 集成,用于报表、分析型查询场景。
- Trino
1)直接将 Iceberg 作为报表数据源
2)需要增加元数据缓存机制:https://github.com/trinodb/trino/issues/7551
- Presto
14. 踩过的坑
1. 访问 Hive Metastore 异常
问题描述:HiveConf 的构造方法的误用,导致 Hive 客户端中声明的配置被覆盖,导致访问 Hive metastore 时异常
解决方案(PR-2075):修复 HiveConf 的构造,显示调用 addResource 方法,确保配置不会被覆盖:hiveConf.addResource(conf);
2.Hive metastore 锁未释放
问题描述:“CommitFailedException: Timed out after 181138 ms waiting for lock xxx.” 原因是 hiveMetastoreClient.lock 方法,在未获得锁的情况下,也需要显示 unlock,否则会导致上面异常。
解决方案(PR-2263):优化 HiveTableOperations#acquireLock 方法,在获取锁失败的情况下显示调用 unlock 来释放锁。
3. 元数据文件丢失
问题描述:Iceberg 表无法访问,报 “NotFoundException Failed to open input stream for file : xxx.metadata.json”
解决方案(PR-2328):当调用 Hive metastore 更新 iceberg 表的 metadata_location 超时后,增加检查机制,确认元数据未保存成功后再删除元数据文件。
三、收益与总结
1. 总结
通过对湖仓一体、流批融合的探索,我们分别做了总结。
- 湖仓一体
1)Iceberg 支持 Hive Metastore;
2)总体使用上与 Hive 表类似:相同数据格式、相同的计算引擎。
- 流批融合
准实时场景下实现流批统一:同源、同计算、同存储。
2. 业务收益
- 数据时效性提升:
入仓延迟从 2 小时以上降低到 10 分钟以内;算法核心任务 SLA 提前 2 小时完成。
- 准实时的分析查询:
结合 Spark 3 和 Trino,支持准实时的多维分析查询。
- 特征工程提效:
提供准实时的样本数据,提高模型训练时效性。
- CDC 数据准实时入仓:
可以在数仓针对业务表做准实时分析查询。
3. 架构收益 - 准实时数仓

上方也提到了,我们支持准实时的入仓和分析,相当于是为后续的准实时数仓建设提供了基础的架构验证。准实时数仓的优势是一次开发、口径统一、统一存储,是真正的批流一体。劣势是实时性较差,原来可能是秒级、毫秒级的延迟,现在是分钟级的数据可见性。
但是在架构层面上,这个意义还是很大的,后续我们能看到一些希望,可以把整个原来 “T + 1” 的数仓,做成准实时的数仓,提升数仓整体的数据时效性,然后更好地支持上下游的业务。
四、后续规划
1. 跟进 Iceberg 版本
全面开放 V2 格式,支持 CDC 数据的 MOR 入湖。
2. 建设准实时数仓
基于 Flink 通过 Data pipeline 模式对数仓各层表全面提速。
3. 流批一体
随着 upsert 功能的逐步完善,持续探索存储层面流批一体。
4. 多维分析
基于 Presto/Spark3 输出准实时多维分析。
原文链接
本文为阿里云原创内容,未经允许不得转载。
汽车之家:基于 Flink + Iceberg 的湖仓一体架构实践的更多相关文章
- 触宝科技基于Apache Hudi的流批一体架构实践
1. 前言 当前公司的大数据实时链路如下图,数据源是MySQL数据库,然后通过Binlog Query的方式消费或者直接客户端采集到Kafka,最终通过基于Spark/Flink实现的批流一体计算引擎 ...
- OnZoom 基于Apache Hudi的流批一体架构实践
1. 背景 OnZoom是Zoom新产品,是基于Zoom Meeting的一个独一无二的在线活动平台和市场.作为Zoom统一通信平台的延伸,OnZoom是一个综合性解决方案,为付费的Zoom用户提供创 ...
- 李呈祥:bilibili在湖仓一体查询加速上的实践与探索
导读: 本文主要介绍哔哩哔哩在数据湖与数据仓库一体架构下,探索查询加速以及索引增强的一些实践.主要内容包括: 什么是湖仓一体架构 哔哩哔哩目前的湖仓一体架构 湖仓一体架构下,数据的排序组织优化 湖仓一 ...
- 基于 Flink 的实时数仓生产实践
数据仓库的建设是“数据智能”必不可少的一环,也是大规模数据应用中必然面临的挑战.在智能商业中,数据的结果代表了用户反馈.获取数据的及时性尤为重要.快速获取数据反馈能够帮助公司更快地做出决策,更好地进行 ...
- 华为云FusionInsight湖仓一体解决方案的前世今生
摘要:华为云发布新一代智能数据湖华为云FusionInsight时再次提到了湖仓一体理念,那我们就来看看湖仓一体的来世今生. 伴随5G.大数据.AI.IoT的飞速发展,数据呈现大规模.多样性的极速增长 ...
- 美团点评基于 Flink 的实时数仓建设实践
https://mp.weixin.qq.com/s?__biz=MjM5NjQ5MTI5OA==&mid=2651749037&idx=1&sn=4a448647b3dae5 ...
- 划重点!AWS的湖仓一体使用哪种数据湖格式进行衔接?
此前Apache Hudi社区一直有小伙伴询问能否使用Amazon Redshift查询Hudi表,现在它终于来了. 现在您可以使用Amazon Redshift查询Amazon S3 数据湖中Apa ...
- 华为云MRS支持lakeformation能力,打造一站式湖仓,释放数据价值
摘要:对云端用户而言,业务价值发现是最重要的,华为MRS支持LakeFormation后,成功降低了数据应用的成本,帮助客户落地"存"与"算"的管理,加快推进了 ...
- MRS+LakeFormation:打造一站式湖仓,释放数据价值
摘要:华为LakeFormation是企业级的一站式湖仓构建服务. 本文分享自华为云社区<华为云MRS支持LakeFormation能力,打造一站式湖仓,释放数据价值]>,作者:break ...
- 字节跳动流式数据集成基于Flink Checkpoint两阶段提交的实践和优化
背景 字节跳动开发套件数据集成团队(DTS ,Data Transmission Service)在字节跳动内基于 Flink 实现了流批一体的数据集成服务.其中一个典型场景是 Kafka/ByteM ...
随机推荐
- Java加密技术(二)——对称加密算法DES&AES
desdesedejavaaes 接下来我们介绍对称加密算法,最常用的莫过于DES数据加密算法. DES DES-Data Encryption Standard,即数据加密算法.是IBM公司 ...
- 5G+实时云渲染,让元宇宙应用触手可及
从2021年初被称为"元宇宙第一股"的罗布乐思(Roblox)正式在纽交所上市,到2021年10月Facebook更名为"Meta"宣布进军元宇宙,再到如今各大 ...
- CSS(复合选择器、显示模式、背景属性)
一.emmet语法 1.简介 Emmet语法的前身是Zen coding,它使用缩写,来提高html/css的编写速度, Vscode内部已经集成该语法. 快速生成HTML结构语法 快速生成CSS样式 ...
- python面向对象(多态)
# 1.什么是多态:同一事物有多种形态 class Animal: # 同一类事物:动物 def talk(self): pass class Cat(Animal): # 动物的形态之一:猫 def ...
- springboot 配置 OpenFeign 时报错:Servlet.service() for servlet [dispatcherServlet] in context with path [] threw exception [Request processing failed; Connection refused: no further information
报错内容如下: 2022-11-18 01:55:18.998 ERROR 22220 --- [nio-8086-exec-4] o.a.c.c.C.[.[.[/].[dispatcherServl ...
- 卷积神经网络学习笔记——ZFNet(Tensorflow实现)
完整代码及其数据,请移步小编的GitHub地址 传送门:请点击我 如果点击有误:https://github.com/LeBron-Jian/DeepLearningNote 这个网络应该是CNN的鼻 ...
- MySQL-ERROR 1701 (42000)
清空具有外键约束的表时报ERROR 1701(42000)的解决 mysql> truncate table events; ERROR 1701 (42000): Cannot truncat ...
- 无监督多视角行人检测 Unsupervised Multi-view Pedestrian Detection
无监督多视角行人检测 Unsupervised Multi-view Pedestrian Detection 论文url:https://arxiv.org/abs/2305.12457 论文简述 ...
- 痞子衡嵌入式:使能i.MXRT1050,1060 Hab签名或加密启动时App链接在片内SRAM的限制
大家好,我是痞子衡,是正经搞技术的痞子.今天痞子衡给大家介绍的是使能i.MXRT1050, 1060 Hab签名或加密启动时App链接在片内SRAM的限制. 最近有客户反馈,在 RT1060 上测试 ...
- HarmonyOS语言基础类库开发指南上线啦!
语言基础类库提供哪些功能?多线程并发如何实现?TaskPool(任务池)和Worker在实现和使用场景上有何不同? 针对开发者关注的并发等语言基础类库的相关能力,我们在新推出的语言基础类库开发指南 ...