pytorch中神经网络的多线程数设置:torch.set_num_threads(N)
实验室的同学一直都是在服务器上既用CPU训练神经网络也有使用GPU的,最近才发现原来在pytorch中可以通过设置 torch.set_num_threads(args.thread) 来限制CPU上进行深度学习训练的线程数。
torch.set_num_threads(args.thread) 在使用时的一个注意事项就是如果不设置则默认使用物理CPU核心数的线程进行训练,而往往默认设置是可以保证运算效率最高的,因此该设置线程数是需要小于物理CPU核心数的,否则会造成效率下降。
既然默认设置既可以保证最高的运算效率那么这个设置的意义在哪呢,这个设置的意义就是在多人使用计算资源时限制你个人的改应用的计算资源占用情况,否则很可能你一个进程跑起来开了太多的线程直接把CPU占用率搞到50%或者直接奔100%去了。
总的说,该设置是为了在多人共享计算资源的时候防止一个进程抢占过高CPU使用率的。
给一个自己的设置代码:(实现了pytorch的最大可能性的确定性可复现性,并设置训练、推理时最大的线程数)
# pytorch的运行设备
device = None def context_config(args):
global device seed = args.seed random.seed(seed)
np.random.seed(seed) torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed) torch.set_num_threads(args.thread) # 设置pytorch并行线程数
if torch.cuda.is_available() and args.gpu >= 0:
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True device = torch.device('cuda:' + str(args.gpu))
else:
device = torch.device('cpu')
================================
运行DQN2013算法,CPU运行,CPU为Intel 10700k, 8核心16线程:
默认设置:

设置20线程:
torch.set_num_threads(20)
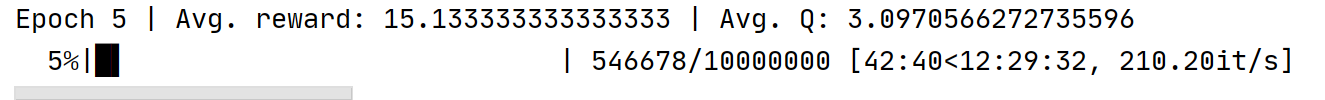
结果:
发现如果线程设置过多,超过CPU的物理线程数运行效率不仅没有提升反而下降,正常默认设置即可。
===================================
pytorch中神经网络的多线程数设置:torch.set_num_threads(N)的更多相关文章
- PyTorch中,关于model.eval()和torch.no_grad()
一直对于model.eval()和torch.no_grad()有些疑惑 之前看博客说,只用torch.no_grad()即可 但是今天查资料,发现不是这样,而是两者都用,因为两者有着不同的作用 引用 ...
- 【转载】 Pytorch中的学习率调整lr_scheduler,ReduceLROnPlateau
原文地址: https://blog.csdn.net/happyday_d/article/details/85267561 ------------------------------------ ...
- pytorch中torch.nn构建神经网络的不同层的含义
主要是参考这里,写的很好PyTorch 入门实战(四)--利用Torch.nn构建卷积神经网络 卷积层nn.Con2d() 常用参数 in_channels:输入通道数 out_channels:输出 ...
- pytorch中文文档-torch.nn常用函数-待添加-明天继续
https://pytorch.org/docs/stable/nn.html 1)卷积层 class torch.nn.Conv2d(in_channels, out_channels, kerne ...
- PyTorch 中 weight decay 的设置
先介绍一下 Caffe 和 TensorFlow 中 weight decay 的设置: 在 Caffe 中, SolverParameter.weight_decay 可以作用于所有的可训练参数, ...
- 如何设置活动监视器中的可见作业数能显示更长范围之内的作业(如何让bpdbjobs/Active Monitor显示更多作业信息)
一.问题: 如何设置可以使得活动监视器中的可见作业数能显示更长范围之内的作业(即NBU软件不要自动删除活动监视器中短时间内(如8天)内的作业记录)? 二.解决方法: 默认情况下在Ac ...
- Direcshow中视频捕捉和參数设置报告
Direcshow中视频捕捉和參数设置报告 1. 关于视频捕捉(About Video Capture in Dshow) 1视频捕捉Graph的构建 一个能够捕捉音频或者视频的graph图 ...
- PyTorch 中 torch.matmul() 函数的文档详解
官方文档 torch.matmul() 函数几乎可以用于所有矩阵/向量相乘的情况,其乘法规则视参与乘法的两个张量的维度而定. 关于 PyTorch 中的其他乘法函数可以看这篇博文,有助于下面各种乘法的 ...
- pytorch中的激励函数(详细版)
初学神经网络和pytorch,这里参考大佬资料来总结一下有哪些激活函数和损失函数(pytorch表示) 首先pytorch初始化: import torch import t ...
- 第五章——Pytorch中常用的工具
2018年07月07日 17:30:40 __矮油不错哟 阅读数:221 1. 数据处理 数据加载 ImageFolder DataLoader加载数据 sampler:采样模块 1. 数据处理 ...
随机推荐
- C#中路径说明
路径中一个点和两个点的区别 ./ 表示当前目录,如"./jquery-1.3.2.min.js",也可以去掉"./",如"jquery-1.3. ...
- Scrapy框架(三)--全站数据爬取
scrapy基于Spider类的全站数据爬取 大部分的网站展示的数据都进行了分页操作,那么将所有页码对应的页面数据进行爬取就是爬虫中的全站数据爬取.基于scrapy如何进行全站数据爬取呢?1.将每一个 ...
- cdn静态资源加速
阿里云cdn产品 https://www.aliyun.com/product/cdn CDN通过广泛的网络节点分布,提供快速.稳定.安全.可编程的全球内容分发加速服务,支持将网站.音视频.下载等内容 ...
- LLM应用实战:当图谱问答(KBQA)集成大模型(三)
1. 背景 最近比较忙(也有点茫),本qiang~想切入多模态大模型领域,所以一直在潜心研读中... 本次的更新内容主要是响应图谱问答集成LLM项目中反馈问题的优化总结,对KBQA集成LLM不熟悉的客 ...
- 微信支付or支付宝支付调用流程图
微信支付or支付宝支付调用流程图 支付宝小程序支付调用流程https://opendocs.alipay.com/mini/03l735 微信H5支付调用流程https://pay.weixin.qq ...
- cdh版本 livy部署
1.livy部署主要就是依赖spark_home的环境变量 如何找到spark_home在哪 locate spark-shell locate是个linux找文件的命令,直接找到该目录
- PackageScanner
package com.cmb.cox.utils;import com.alibaba.fastjson.JSON;import com.alibaba.fastjson.JSONObject;im ...
- POJ2247,hdu1058(Humble Numbers)
Problem Description A number whose only prime factors are 2,3,5 or 7 is called a humble number. The ...
- Spring之webMvc异常处理
异常处理可以前端处理,也可以后端处理. 从稳妥的角度出发,两边都应该进行处理. 本文专门阐述如何在服务端进行http请求异常处理. 一.常见的异常类型 当我们做http请求的时候,会有各种各样的可能错 ...
- echo输出带颜色的字
文章目录 格式 所有颜色 字体样式 示例 格式 \033[A;F;Bm #放在文本的左边,可以影响后面所有字体的样式 解释: F代表字体颜色值(Font),颜色编号30~37. B代表背景颜色值(Ba ...