强化学习:reward function shaping —— 着陆器(lander)游戏中的奖励函数的设计
lander 游戏是强化学习问题中常使用的一个游戏场景,不同人对该问题都设置了不同的reward function,一直也没有对该游戏的各种reward function的设计做一个记录,正好看视频看到了一个该游戏的reward function的设计,这里mark下。
资料来源:
https://www.youtube.com/watch?v=0R3PnJEisqk
==============================================
给出了第一种 reward function 设计,该种设计为复杂设计:

第二种设计,简单设计的 reward function:
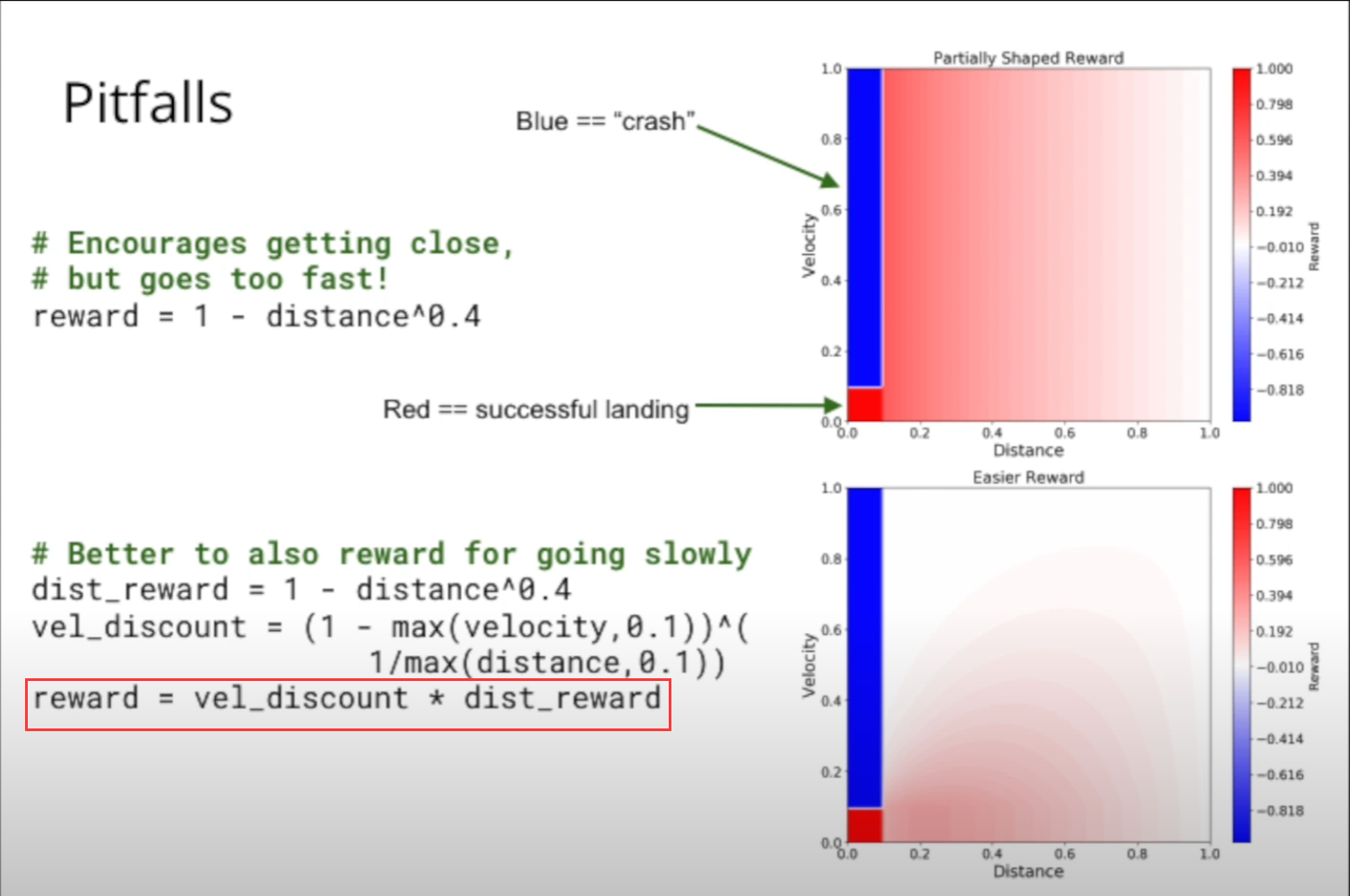
强化学习:reward function shaping —— 着陆器(lander)游戏中的奖励函数的设计的更多相关文章
- C语言写猜拳游戏中遇到的函数循环小问题
各位可能在初学C语言的时候都有写过猜拳游戏.但在写猜拳的函数时,避免不了会使用循环. 当函数被套在一个循环中的时候,你的计分变量可能就会被重置为函数体里的初始值.那么怎么解决这个问题? 其实很简单,你 ...
- 强化学习论文(Scalable agent alignment via reward modeling: a research direction)
原文地址: https://arxiv.org/pdf/1811.07871.pdf ======================================================== ...
- ICML论文|阿尔法狗CTO讲座: AI如何用新型强化学习玩转围棋扑克游戏
今年8月,Demis Hassabis等人工智能技术先驱们将来到雷锋网“人工智能与机器人创新大会”.在此,我们为大家分享David Silver的论文<不完美信息游戏中的深度强化学习自我对战&g ...
- 【整理】强化学习与MDP
[入门,来自wiki] 强化学习是机器学习中的一个领域,强调如何基于环境而行动,以取得最大化的预期利益.其灵感来源于心理学中的行为主义理论,即有机体如何在环境给予的奖励或惩罚的刺激下,逐步形成对刺激的 ...
- 深度强化学习(Deep Reinforcement Learning)入门:RL base & DQN-DDPG-A3C introduction
转自https://zhuanlan.zhihu.com/p/25239682 过去的一段时间在深度强化学习领域投入了不少精力,工作中也在应用DRL解决业务问题.子曰:温故而知新,在进一步深入研究和应 ...
- 【转载】 强化学习(十一) Prioritized Replay DQN
原文地址: https://www.cnblogs.com/pinard/p/9797695.html ------------------------------------------------ ...
- David Silver强化学习Lecture1:强化学习简介
课件:Lecture 1: Introduction to Reinforcement Learning 视频:David Silver深度强化学习第1课 - 简介 (中文字幕) 强化学习的特征 作为 ...
- 【转载】 准人工智能分享Deep Mind报告 ——AI“元强化学习”
原文地址: https://www.sohu.com/a/231895305_200424 ------------------------------------------------------ ...
- 深度强化学习:Deep Q-Learning
在前两篇文章强化学习基础:基本概念和动态规划和强化学习基础:蒙特卡罗和时序差分中介绍的强化学习的三种经典方法(动态规划.蒙特卡罗以及时序差分)适用于有限的状态集合$\mathcal{S}$,以时序差分 ...
- 强化学习(十五) A3C
在强化学习(十四) Actor-Critic中,我们讨论了Actor-Critic的算法流程,但是由于普通的Actor-Critic算法难以收敛,需要一些其他的优化.而Asynchronous Adv ...
随机推荐
- 微软新Edge浏览器 WIN7 无法登录
由于设备上的系统组件过期,不支持登录.请确保 Windows 为最新版本,然后重新尝试登录.访问 https://go.microsoft.com/fwlink/?linkid=2107246 了解详 ...
- redis高可用哨兵篇
https://redis.io/docs/manual/sentinel/#sentinels-and-replicas-auto-discovery 官网资料 在上文主从复制的基础上,如果注节点出 ...
- MyBatis 的在使用上的注意事项及其辨析
1. MyBatis 的在使用上的注意事项及其辨析 @ 目录 1. MyBatis 的在使用上的注意事项及其辨析 2. 准备工作 3. #{ } 与 ${ } 的区别和使用 {} 3.1 什么情况下必 ...
- 三月二十六日 安卓打卡app开发日志
今天上午 将打卡逻辑代码优化了一下 之后每天就只可以打卡一次了 public static String daka(String time_s, String time_e, String text, ...
- HDFS的特点和目标,不适合场景
HDFS的特点和目标: HDFS设计优点: (一)高可靠性:Hadoop按位存储和处理数据的能力值得人们信赖; (二)高扩展性:Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可 ...
- OpenBMB × Hugging Face × THUNLP,联袂献上经典大模型课
这个夏天,THUNLP 携手 Hugging Face 和 OpenBMB,推出 大模型公开课第二季.在大模型公开课第二季中,将有全球知名开源社区 OpenBMB X Hugging Face 梦幻联 ...
- 从Java开发者到.NET Core初级工程师学习路线:C#语言基础
1. C#语言基础 1.1 C#语法概览 欢迎来到C#的世界!对于刚从Java转过来的开发者来说,你会发现C#和Java有很多相似之处,但C#也有其独特的魅力和强大之处.让我们一起来探索C#的基本语法 ...
- 能说下 vue-router 中常用的 hash 和 history 路由模式实现原理吗?
这个router有两种模式:hash模式(默认).history模式(需配置mode: 'history') 然后,我们来研究下两者的原理: 我们先来认识下这位朋友#,这个#就是hash符号,中文名哈 ...
- PO、VO、BO、DTO、POJO、DAO、DO
DO: domain object持久对象就是从现实世界中抽象出来的有形或无形的业务实体. PO:persistant object持久对象最形象的理解就是一个PO就是数据库中的一条记录.好处是可以把 ...
- Pluto 轻松构建云应用:开发指南
开发者只需在代码中定义一些变量,Pluto 就能基于这些变量自动创建与管理必要的云资源组件,达到简化部署和管理云基础设施的目的,让开发者更容易使用云. 这里的云资源并非指 IaaS,而是指 BaaS. ...