[python]数据分析--数据清洗处理case1
数据预处理案例1
主要涉及pandas读取csv文件,缺失值和重复值处理,分组计数,字段类型转换 ,结果写入到Excel。
根据要求对CSV数据集进行处理要求如下:
保留数据关键信息:
time、latitude、longtitude、depth、mag、region- 注意其中的
region未直接提供,需要从数据集中的place中获取。 - 特别说明例如:
place中76km SSW of Kaktovik, Alaska,挑战要求只保留Alaska作为地区信息。如果place中存在二级地区信息(2 个逗号),例如,15km SSW of Estacion Coahuila, B.C., MX,则只保留最后一个逗号间隔的MX作为地区信息。特别地,如果不存在,分割,则保留全部数据即可。
- 注意其中的
对数据集中的缺失值(任意一项缺失)、重复值(全部字段重复)进行处理,要求直接删除相应行。异常值无需考虑。
对
mag字段进行分级:
| 震级 | 描述 |
|---|---|
| [0, 2) | micro |
| [2, 5) | light |
| [5, 7) | strong |
| [7, 9) | major |
| >=9 | great |
- 返回 mag分级不同级别对应
times对多的region及对应times(该字段需要为int类型)
数据集获取
http://labfile.oss.aliyuncs.com/courses/1176/earthquake.csv
复制上述连接然后在浏览器上打开,即可下载文件。
数据清洗
import pandas as pd
def clean()
# 读取文件
# Tips: 找到下载文件使用快捷键 Ctrl+Shift+C 可复制文件路径,然后粘贴替换引号部分内容
fn = r'D:\VSCode_Notebook\lanqiao\earthquake .csv'
df = pd.read_csv(fn)
# 对字段进行筛选
res = df[['time','latitude','longitude','depth','mag']]
place = df[['place']]
# 对place字段处理获取region
region = place['place'].str.split(',')
lst = []
for i in region:
lst.append(i[-1].strip())
region1 = pd.DataFrame(data=lst,columns=['region'])
# 合并Dataframe
res = res.join(region1)
# 去除重复值、空值
df_clean = res.drop_duplicates().dropna()
return df_clean
原过程是使用JupyterNoebook进行分步编写,主要能查看数据处理过程中数据的变化情况,将其封装成函数方便后续调用。
place = df[['place']]
# 对place字段处理获取region
region = place['place'].str.split(',')
lst = []
for i in region:
lst.append(i[-1].strip())
region1 = pd.DataFrame(data=lst,columns=['region'])
这里是对 place字段进行处理,通过 str.splt()方法进行分割,后续的 for循环主要是通过切片的方式获取所需内容,同时通过 strip()去除空格。
参考别人代码发现还有其它处理办法可改写如下:
place = df['place'].str.split(', ').tolist() # 分割字符串的时候就把空格带上,也能达到目的
region = []
for row in place:
region.append(row[-1])
region1 = pd.DataFrame(data=region,columns=['region'])
上面的合并 DataFrame 也可使用pd.concat([res,region1] ,axis=1)实现。
数据处理分析
def mag_region():
# 加载清洁后数据
df_clean = clean()
# 数据离散化,注意开闭区间
df_clean['mag'] = pd.cut(df_clean.mag, bins=[0, 2, 5, 7, 9, 15], right=False, labels=['micro', 'light', 'strong', 'major', 'great'])
print(df_clean)
# 多索引分组聚合并计数
df_group = df_clean.groupby(by=['mag', 'region']).count()
# 重置索引并去除缺失值
df_reindex = df_group.reset_index().dropna()
# 按计数从大到小排序,并使用去除重复值的方法保留下各地区最大值
df_sort = df_reindex.sort_values(
by='time', ascending=False).drop_duplicates(['mag'])
# 按要求整理并重命名
df_final = df_sort.set_index('mag')[['region', 'time']].rename(
columns={"time": "times"})
# 按题目要求将计数处理成 int 类型
df_final['times'] = df_final.times.astype('int')
return df_final
由于 csv文件中的一条条记录对应一次更新时间的地震情况统计,所以上述代码中使用分组计数完成统计要求。
结果输出
df_final = mag_region()
writer = pd.ExcelWriter('output1.xlsx')
df_final.to_excel(writer,sheet_name='out',index=True)
writer._save() # 较低版本python 使用writer.save()来保存
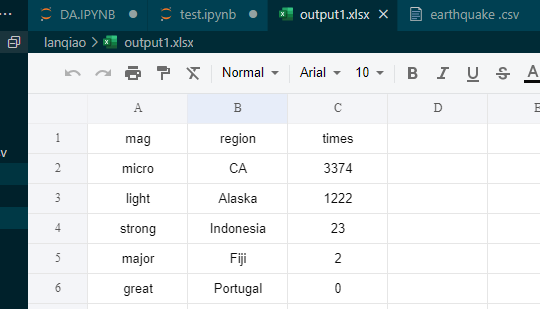
使用pandas进行Excel写入前,需要你的python环境中安装了openpyxl库。最后写入的结果如下:
知识小结
文末对案例中使用到的重要方法进行总结:
去重与去重复值:
df.drop_duplicates() 方法用于从 DataFrame 中删除重复的行。
该方法的用法如下:
df.drop_duplicates(subset=None, keep='first', inplace=False)
参数说明:
subset:可选参数,用于指定要考虑的列名列表。默认值为None,表示考虑所有列。keep:可选参数,用于指定保留哪一个重复行的方式。可选值为'first','last'或False。默认值为'first',表示保留第一次出现的重复行。inplace:可选参数,表示是否在原始 DataFrame 上进行修改。默认值为False,表示返回处理后的新 DataFrame。
下面是一些示例,以便更好地理解 df.drop_duplicates() 的用法:
- 删除所有列中的重复行,并返回处理后的新 DataFrame:
df_new = df.drop_duplicates()
- 只考虑某些列的重复行,并返回处理后的新 DataFrame:
df_new = df.drop_duplicates(subset=['col1', 'col2'])
- 删除所有列中的重复行,并在原始 DataFrame 上进行修改:
df.drop_duplicates(inplace=True)
在 Pandas 中,df.dropna() 方法用于删除 DataFrame 中包含缺失值(NaN)的行或列。
该方法的用法如下:
df.dropna(axis=0, how='any', subset=None, inplace=False)
参数说明:
axis:可选参数,用于指定删除行还是删除列。可选值为0或'index'(默认值),表示删除行;可选值为1或'columns',表示删除列。how:可选参数,用于指定何时删除。可选值为'any'(默认值),表示当某一行或列中包含一个或多个缺失值时删除;可选值为'all',表示只有当一行或列中的所有值都是缺失值时才删除。subset:可选参数,用于指定要考虑的列名列表。默认值为None,表示考虑所有列。inplace:可选参数,表示是否在原始 DataFrame 上进行修改。默认值为False,表示返回处理后的新 DataFrame。
下面是一些示例,以便更好地理解 df.dropna() 的用法:
- 删除包含任何缺失值的行,并返回处理后的新 DataFrame:
df_new = df.dropna()
- 删除指定列中包含缺失值的行,并返回处理后的新 DataFrame:
df_new = df.dropna(subset=['col1', 'col2'])
- 删除包含全部缺失值的行,并在原始 DataFrame 上进行修改:
df.dropna(how='all', inplace=True)
数据离散化
当使用 pd.cut() 函数时,可以根据指定的条件将数据进行划分并创建一个新的分类变量。这个函数可以用于数据分析和数据可视化中的分组操作。
下面是 pd.cut() 的常用参数及用法详解:
pd.cut(x, bins, labels=None, right=True, include_lowest=False, duplicates='raise')
x:要划分的一维数据数组,可以是 Pandas Series、NumPy 数组或 Python 列表。bins:划分的边界值,可以按照以下方式指定:- 整数:表示要划分的区间数量,
pd.cut()函数将自动确定最小和最大值,并根据该数量均匀划分区间。 - 列表或数组:表示各个区间的边界值。例如,[0, 10, 20, 30] 表示将数据划分为小于0、10-20、20-30和大于30四个区间。
- 具有标签的元组列表:表示自定义的区间标签和边界值。例如,[(0, 'A'), (10, 'B'), (20, 'C')] 表示将数据划分为 A、B、C 三个区间。
- 整数:表示要划分的区间数量,
labels:可选参数,用于指定划分后的每个区间的标签。如果不提供,将默认使用整数标签。right:可选参数,表示是否将区间的右边界包含在内。默认为True,即右闭区间。include_lowest:可选参数,表示是否将最小值包含在第一个区间中。默认为False,即不包含最小值。duplicates:可选参数,表示对于边界值是否允许重复。默认为 'raise',表示如果有重复的边界值,则会引发异常。如果设置为 'drop',则会将重复的边界值合并。
pd.cut() 返回的结果是一个 Categorical 类型的数据对象,它代表划分后的区间,包含区间信息和标签。可以将这个对象作为新的一列添加到 DataFrame 中,也可以用于分析和可视化操作。
下面是几个示例,以展示 pd.cut() 函数的用法:
- 根据区间数量划分数据:
import pandas as pd
data = [2, 5, 7, 12, 15, 18, 20, 25, 30]
bins = 3
result = pd.cut(data, bins)
print(result)
输出:
[(1.976, 10.0], (1.976, 10.0], (1.976, 10.0], (10.0, 18.0], (10.0, 18.0], (10.0, 18.0], (18.0, 25.0], (18.0, 25.0], (25.0, 32.0]]
Categories (3, interval[float64]): [(1.976, 10.0] < (10.0, 18.0] < (18.0, 25.0]]
- 根据自定义的区间边界划分数据,指定标签:
import pandas as pd
data = [2, 5, 7, 12, 15, 18, 20, 25, 30]
bins = [0, 10, 20, 30]
labels = ['Low', 'Medium', 'High']
result = pd.cut(data, bins, labels=labels)
print(result)
输出:
[Low, Low, Low, Medium, Medium, Medium, High, High, High]
Categories (3, object): [Low < Medium < High]
- 使用
right=False参数包含左边界:
import pandas as pd
data = [2, 5, 7, 12, 15, 18, 20, 25, 30]
bins = [0, 10, 20, 30]
labels = ['Low', 'Medium', 'High']
result = pd.cut(data, bins, labels=labels, right=False)
print(result)
输出:
[Low, Low, Medium, Medium, Medium, High, High, High]
Categories (3, object): [Low < Medium < High]
[python]数据分析--数据清洗处理case1的更多相关文章
- 小象学院Python数据分析第二期【升级版】
点击了解更多Python课程>>> 小象学院Python数据分析第二期[升级版] 主讲老师: 梁斌 资深算法工程师 查尔斯特大学(Charles Sturt University)计 ...
- Python数据分析【炼数成金15周完整课程】
点击了解更多Python课程>>> Python数据分析[炼数成金15周完整课程] 课程简介: Python是一种面向对象.直译式计算机程序设计语言.也是一种功能强大而完善的通用型语 ...
- 学习推荐《从Excel到Python数据分析进阶指南》高清中文版PDF
Excel是数据分析中最常用的工具,本书通过Python与Excel的功能对比介绍如何使用Python通过函数式编程完成Excel中的数据处理及分析工作.在Python中pandas库用于数据处理,我 ...
- Python数据分析入门与实践 ✌✌
Python数据分析入门与实践 (一个人学习或许会很枯燥,但是寻找更多志同道合的朋友一起,学习将会变得更加有意义✌✌) 这是一个数据驱动的时代,想要从事机器学习.人工智能.数据挖掘等前沿技术,都离不开 ...
- 小白学 Python 数据分析(1):数据分析基础
各位同学好,小编接下来为大家分享一些有关 Python 数据分析方面的内容,希望大家能够喜欢. 人工植入广告: PS:小编最近两天偷了点懒,好久没有发原创了,最近是在 CSDN 开通了一个付费专栏,用 ...
- 小白学 Python 数据分析(11):Pandas (十)数据分组
人生苦短,我用 Python 前文传送门: 小白学 Python 数据分析(1):数据分析基础 小白学 Python 数据分析(2):Pandas (一)概述 小白学 Python 数据分析(3):P ...
- 《谁说菜鸟不会数据分析》高清PDF全彩版|百度网盘免费下载|Python数据分析
<谁说菜鸟不会数据分析>高清PDF全彩版|百度网盘免费下载|Python数据分析 提取码:p7uo 内容简介 <谁说菜鸟不会数据分析(全彩)>内容简介:很多人看到数据分析就望而 ...
- 万字长文,Python数据分析实战,使用Pandas进行数据分析
文章目录 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手.很多已经做案例的人,却不知道如何去学习更加高深的知识.那么针对这三类人,我给大家 ...
- python数据分析与可视化【思维导图】
python数据分析与可视化常用库 numpy+matplotlib+pandas 思维导图 图中难免有错误,后期随着学习与应用的深入,会不断修改更新. 当前版本号:1.0 numpy介绍 NumPy ...
- [Python数据分析]新股破板买入,赚钱几率如何?
这是本人一直比较好奇的问题,网上没搜到,最近在看python数据分析,正好自己动手做一下试试.作者对于python是零基础,需要从头学起. 在写本文时,作者也没有完成这个小分析目标,边学边做吧. == ...
随机推荐
- 玩转 PI 系列-看起来像服务器的 ARM 开发板矩阵-Firefly Cluster Server
前言 基于我个人的工作内容和兴趣,想要在家里搞一套服务器集群,用于容器/K8s 等方案的测试验证. 考虑过使用二手服务器,比如 Dell R730, 还搞了一套配置清单,如下: Dell R730 3 ...
- springboot打包与依赖包分离
前言: springboot项目部署时,需要本地打包成一个jar放到服务器进行部署(使用jenkins自动打包部署同理),部署包里包含了其它所有依赖包,整个包会比较大,小则几M,大则几十上百. 正文: ...
- 「openjudge / poj - 1057」Chessboard
link. 调起来真的呕吐,网上又没篇题解.大概是个不错的题. 首先行和列一定是独立的,所以我们把行列分开考虑.这样的问题就弱化为:在一个长度为 \(n\) 的格子带上,有 \(n\) 个物品,每个物 ...
- MySQL中的Statistics等待
[作者] 吴宙旭,携程数据库专家 [问题描述] 线上我们偶尔会碰到MySQL的状态是statistics. 但如果出现大量的statistics等待,会引起MySQL性能急剧下降.官方的文档对这个状态 ...
- c语言代码练习14
//设计一个猜数字游戏,需要提示猜大了还是小了,直到猜对为止 #define _CRT_SECURE_NO_WARNINGS 1 #include <stdio.h> #include & ...
- 成本阶问题:财务模块axcr004合计金额检核表第18行合计金额与明细差异过大问题处理?
财务模块axcr004合计金额检核表第18行合计金额与明细差异过大问题处理? 可能原因:生产开立工单时元件未建在生产料件BOM明细中,导致成本阶没有算到,需要手动更改成本阶. 公式: 处理办法:修改成 ...
- Linux 中如何安全地抹去磁盘数据?
哈喽大家好,我是咸鱼 离过职的小伙伴都知道,离职的时候需要上交公司电脑,但是电脑里面有许多我们的个人信息(聊天记录.浏览记录等等) 所以我们就需要先把这些信息都删除,确保无法恢复之后才上交 即有些情况 ...
- 环境搭建:在VSCode搭建Python环境
1.安装vscode 2.下载python解释器 安装python https://www.python.org/downloads/windows/ 下载可执行的安装文件: 安装完成 ...
- P1126 机器人搬重物 题解
Problem 题目概括 $n \times m $ 的网格,有些格子是障碍格.\(0\) 无障碍,\(1\) 有障碍.机器人有体积,总是在格点上. 有5种操作: 向前移动 \(1/2/3\) 步 左 ...
- 【2023年更新】git 常用口令
1.已关联远程 fatal: remote origin already exists. 先输入$ git remote rm origin(删除关联的origin的远程库) 2.关联新远程 ...