MySQL运维11-Mycat分库分表之应用指定分片
一、应用指定分片

说明1:子字符串分片有一个局限性,就是截取的子字符串必须是数字,而且要从截取的数字0:代表第一个数据节点,1:代表第二个数据节点,以此类推,因为数据节点的下标是从0开始的。
说明2:子字符串分片的规则是rule="sharding-by-substring"
说明3:function中的startIndex是截取子字符串的开始截取的索引位置,即从第一个位置开始截取。
说明4:function中的size是截取长度
说明5:partitionCount是分片数量,注意分片的索引从0开始,所以这里partitionCount=3,即第一个数据分片的值为0,第二个数据分片的值为1,第三个数据分片的值为2
说明6:defaultPartition是默认的数据保存的数据节点,即如果万一出现了不符合的截取数据,都会存放在这个默认数据节点上,例如现在有一个截取子字符串为5开头的数据,就会放在这个默认数据节点上。
二、准备工作
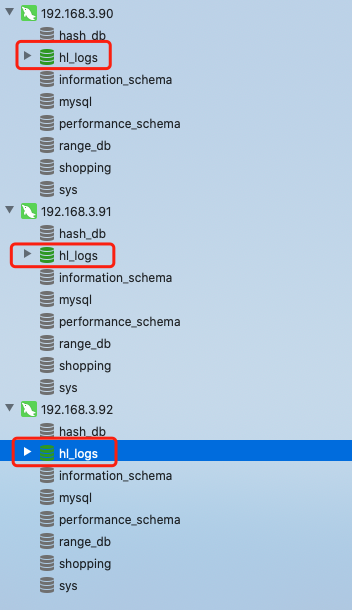
子字符串分片需求:基于逻辑库hl_logs,创建逻辑表tb_school,里面包括id,name,age等字段,其中小学部的学生id以1开头,中学部的学生id以2开头,高中部的学生id以3开头
三、配置rule.xml
<tableRule name="sharding-by-substring">
<rule>
<columns>id</columns>
<algorithm>sharding-by-substring</algorithm>
</rule>
</tableRule>
说明1:该分片方法没有在rule.xml示例中展示出来,所以需要我们手动在rule.xml文档中,添加上该规则。
<function name="sharding-by-substring" class="io.mycat.route.function.PartitionDirectBySubString">
<property name="startIndex">0</property>
<property name="size">1</property>
<property name="partitionCount">3</property>
<property name="defaultPartition">2</property>
</function>
说明2:该分片方法的function引用也没有在rule.xml的示例中展示出来,同样需要我们手动添加上function的实现
说明3:function中的startIndex是截取子字符串的开始截取的索引位置,即从第一个位置开始截取。
说明4:function中的size是截取长度
说明5:partitionCount是分片数量,注意分片的索引从0开始,所以这里partitionCount=3,即第一个数据分片的值为0,第二个数据分片的值为1,第三个数据分片的值为2
说明6:defaultPartition是默认的数据保存的数据节点,即如果万一出现了不符合的截取数据,都会存放在这个默认数据节点上,例如现在有一个截取子字符串为5开头的数据,就会放在这个默认数据节点上。
四、配置schema.xml
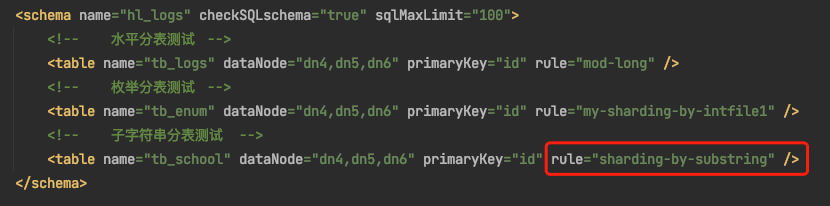
说明1:逻辑库为hl_logs
说明2:逻辑表为tb_school
说明3:分片规则我们改手动实现的"sharding-by-substring"
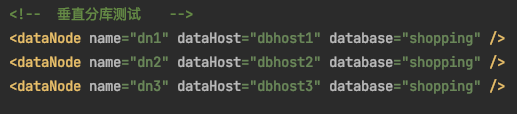

说明4:dn10对应的是dbhost1即192.168.3.90分片
说明5:dn11对应的是dbhost2即192.168.3.91分片
说明6:dn12对应的是dbhost3即192.168.3.92分片
五、配置server.xml
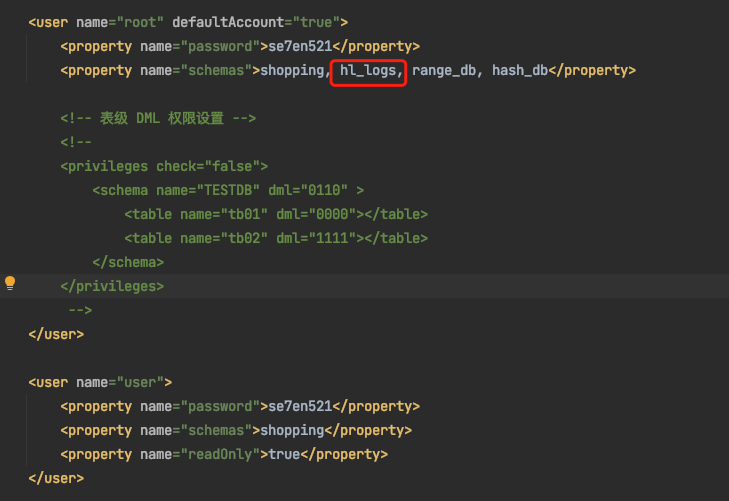
说明1:在之前的文章中已经将tb_logs表添加到root用户的权限中了,所以这里不需要更改即可。
六、应用指定分片测试
首先重启Mycat
登录Mycat

查看逻辑库和逻辑表
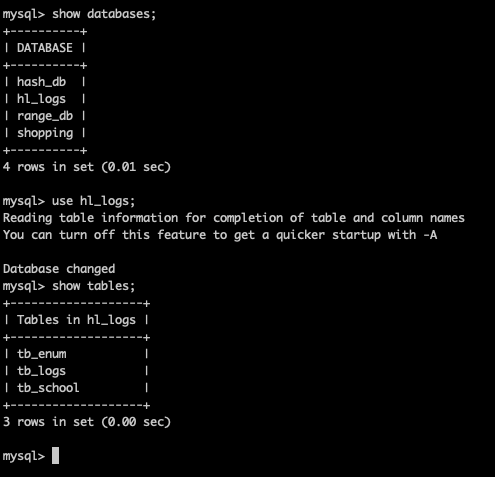
这里的tb_school只是逻辑库,而在MySQL中还并没有tb_school这个表,需要在Mycat中创建
create table tb_school(id varchar(5), name varchar(20), age int);

插入数据进行测试:这里插入一组数据进行测试:
insert into tb_school(id, name, age) values ("00001", "张三", 7);
insert into tb_school(id, name, age) values ("00002", "李四", 8);
insert into tb_school(id, name, age) values ("10001", "王五", 14);
insert into tb_school(id, name, age) values ("10002", "赵六", 15);
insert into tb_school(id, name, age) values ("20001", "侯七", 17);
insert into tb_school(id, name, age) values ("30003", "孙八", 18);
insert into tb_school(id, name, age) values ("40001", "周九", 17);

说明1:这里的id要求是字符串类型的
说明2:id虽然是字符串类型的,但是我们要截取的第一位还必须是数字,所以这中分片方式比较苛刻

说明3:第一个数据节点192.168.3.90里面保存的数据全部是id以0开头的数据

说明4:第二个数据节点192.168.3.91里面保存的数据全部是id以1开头的数据

说明5: 第三个数据节点的索引是2,所以第三个数据节点是默认数据阶段,这里面保存了id以2开头的数据,可其他不满足分片规则的数据,例如id截取第一个字符串3和4,就不满足数据分片下标0,1,2的规则,就只能进入到默认的这个数据节点中。也可以理解为默认的数据节点是兜底的分片
说明6:其实这个应用指定字符串截取的方式和枚举分片有同工异曲的效果,只是不用在单独创建一个枚举字段了。

说明7:在Mycat上进行查询的数据是,所有数据节点的全集。应用指定分片是水平分库分表的一种方式。
MySQL运维11-Mycat分库分表之应用指定分片的更多相关文章
- Mysql系列五:数据库分库分表中间件mycat的安装和mycat配置详解
一.mycat的安装 环境准备:准备一台虚拟机192.168.152.128 1. 下载mycat cd /softwarewget http:-linux.tar.gz 2. 解压mycat tar ...
- MySQL+MyCat分库分表 读写分离配置
一. MySQL+MyCat分库分表 1 MyCat简介 java编写的数据库中间件 Mycat运行环境需要JDK. Mycat是中间件.运行在代码应用和MySQL数据库之间的应用. 前身 : cor ...
- Mysql系列四:数据库分库分表基础理论
一.数据处理分类 1. 海量数据处理,按照使用场景主要分为两种类型: 联机事务处理(OLTP) 面向交易的处理系统,其基本特征是原始数据可以立即传送到计算机中心进行处理,并在很短的时间内给出处理结果. ...
- 《MyCat分库分表策略详解》
在我们的项目发展到一定阶段之后,随着数据量的增大,分库分表就变成了一件非常自然的事情.常见的分库分表方式有两种:客户端模式和服务器模式,这两种的典型代表有sharding-jdbc和MyCat.所谓的 ...
- 3.Mysql集群------Mycat分库分表
前言: 分库分表,在本节里是水平切分,就是多个数据库里包含的表是一模一样的. 只是把字段散列的分到不同的库中. 实践: 1.修改schema.xml 这里是在同一台服务器上建立了4个数据库db1,db ...
- mycat 分库分表
单库分表已经在上篇写过了,这次写个分库分表,不同在于配置文件上的一点点不同 <!DOCTYPE mycat:schema SYSTEM "schema.dtd"> &l ...
- MyCat分库分表入门
1.分区 对业务透明,分区只不过把存放数据的文件分成了许多小块,例如mysql中的一张表对应三个文件.MYD,MYI,frm. 根据一定的规则把数据文件(MYD)和索引文件(MYI)进行了分割,分区后 ...
- Mycat分库分表(一)
随着业务变得越来越复杂,用户越来越多,集中式的架构性能会出现巨大的问题,比如系统会越来越慢,而且时不时会宕机,所以必须要解决高性能和可用性的问题.这个时候数据库的优化就显得尤为重要,在说优化方案前,先 ...
- mycat分库分表 看这一篇就够了
之前我们已经讲解过了数据的切分,主要有两种方式,分别是垂直切分和水平切分,所谓的垂直切分就是将不同的表分布在不同的数据库实例中,而水平切分指的是将一张表的数据按照不同的切分规则切分在不同实例的相同 ...
- MyCat | 分库分表实践
引言 先给大家介绍2个概念:数据的切分(Sharding)根据其切分规则的类型,可以分为两种切分模式. 切分模式 一种是按照不同的表(或者Schema)来切分到不同的数据库(主机)之上,这种切可以称之 ...
随机推荐
- Adobe全家桶PS、PR、AU等2022正版永久有效,无需破解直接安装就能用
[Adobe全家桶]已经亲测绝对好用,下载地址: 关注我的wx公众号"奋斗在IT"回复1013获取下载地址.
- 每日一题:AJAX进度监控(附可运行源码)
1.什么是AJAX AJAX(Asynchronous JavaScript and XML)是一种用于在网页上进行异步通信的技术.它允许在不刷新整个页面的情况下,通过在后台与服务器进行数据交换来更新 ...
- 文心一言 VS 讯飞星火 VS chatgpt (98)-- 算法导论9.3 4题
四.用go语言,对一个包含n个元素的集合,假设一个算法只使用比较来确定第i小的元素,证明:无需额外的比较操作,它也能找到第 i-1 小的元素和第 n-i大的元素. 文心一言: 在这个问题中,我们要使用 ...
- cmake构建32位应用程序
1. 背景介绍 2. 工具介绍 3. 环境搭建 4. MinGW编译器版本 1. 背景介绍 最近需要使用第三方动态库文件G33DDCAPI.dll进行二次开发.由于这个动态库文件生成的时间比较早,且只 ...
- Android Orm框架(GreenDao)
Android Orm框架(GreenDao) 分类: android2014-04-10 14:29 723人阅读 评论(0) 收藏 举报 GreenDao与Ormlite对比 Ormlite:简单 ...
- CMP临时文件清理
■■ CMP临时文件 CMP - 指 Compression Advisor ,是 Oracle 数据库的压缩建议特性,在生成建议时产生的中间过程表,一般会自行删除.这个特性自 11.2.0.4 引入 ...
- umich cv-2-2
UMICH CV Linear Classifiers 在上一篇博文中,我们讨论了利用损失函数来判断一个权重矩阵的好坏,在这节中我们将讨论如何去找到最优的权重矩阵 想象我们要下到一个峡谷的底部,我们自 ...
- 一次考试的dp题
很明显是dp 看题目的时候我们先进行初步的思考,发现一个性质 一个点时不可能被重复覆盖三次的很显然,如果一个点被覆盖了3次,这3个覆盖他的区间一定是有一个区间被完全包含的,因为有贡献的左右端点只有两个 ...
- 当scroll-view水平滚动,内容溢出时,文本会自动竖向排列问题
当scroll-view水平滚动,内容溢出时,文本会自动竖向排列 解决方法:thite-space:nowrap:规定段落中的文本不进行换行
- calico网络异常,不健康
解决calico/node is not ready: BIRD is not ready: BGP not established withxxx calico有一个没有ready,查了一下是没有发 ...