如何对连续型数据进行离散化处理,并进行OneHot编码?
如何对连续型数据进行离散化处理,并进行OneHot编码,最终将OneHot编码作为特征因子输入模型?
什么是OneHot编码
One-Hot编码是分类变量作为二进制向量的表示。这首先要求将分类值映射到整数值。然后,每个整数值被表示为二进制向量,除了整数的索引之外,它都是零值,它被标记为1。
通过这个简单的例子,比如这个特征是指的学生的一个性别,那么这个性别只有男女两类?那么我们通过这个 one hold 编码出来,就是男用 1,0 表示,女用 0,1 表示。年纪按照小学、初中、高中来进行一个编码,那么小学就可以用100,那么初中用 010 ,高中用 001 。如果说这个特征,它有几类的话,那么得有几列数字,然后其中每一列如果那个值为 1 的话,就表示其中的一个分类。那么从这种分类的就是类别型的一个特征。没有用 one hode 之前就是那种简单的一个分类,比如12345 这种就直接拿去训练了。

代码示例
df = m11.data.read()
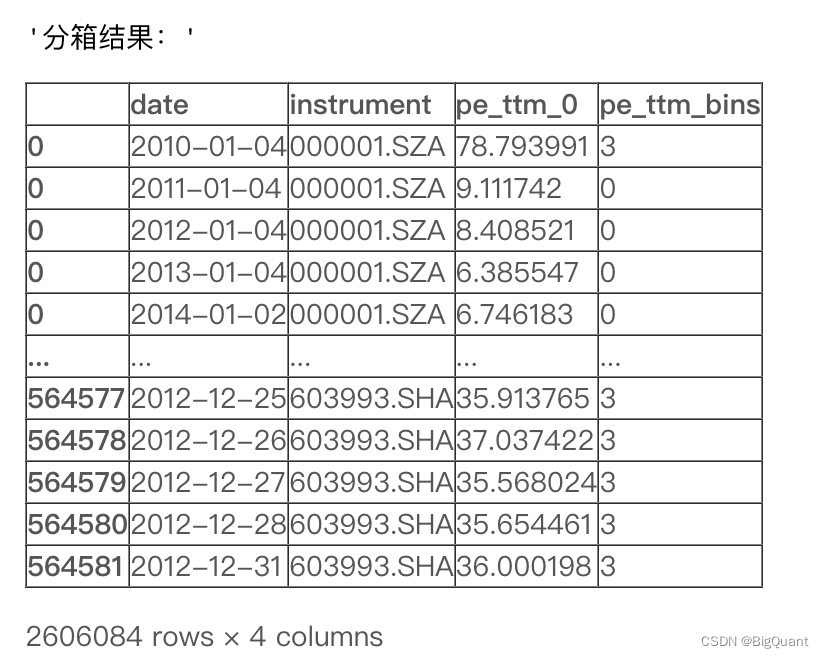
#分箱
col_name = 'pe_ttm_bins'
def cal_bins(df):
bins=5
df[col_name] = np.array(pd.qcut(df.pe_ttm_0, bins, labels=range(0, bins)))
return df
df = df.groupby('date').apply(cal_bins)
display("分箱结果:",df[['date','instrument','pe_ttm_0','pe_ttm_bins']])
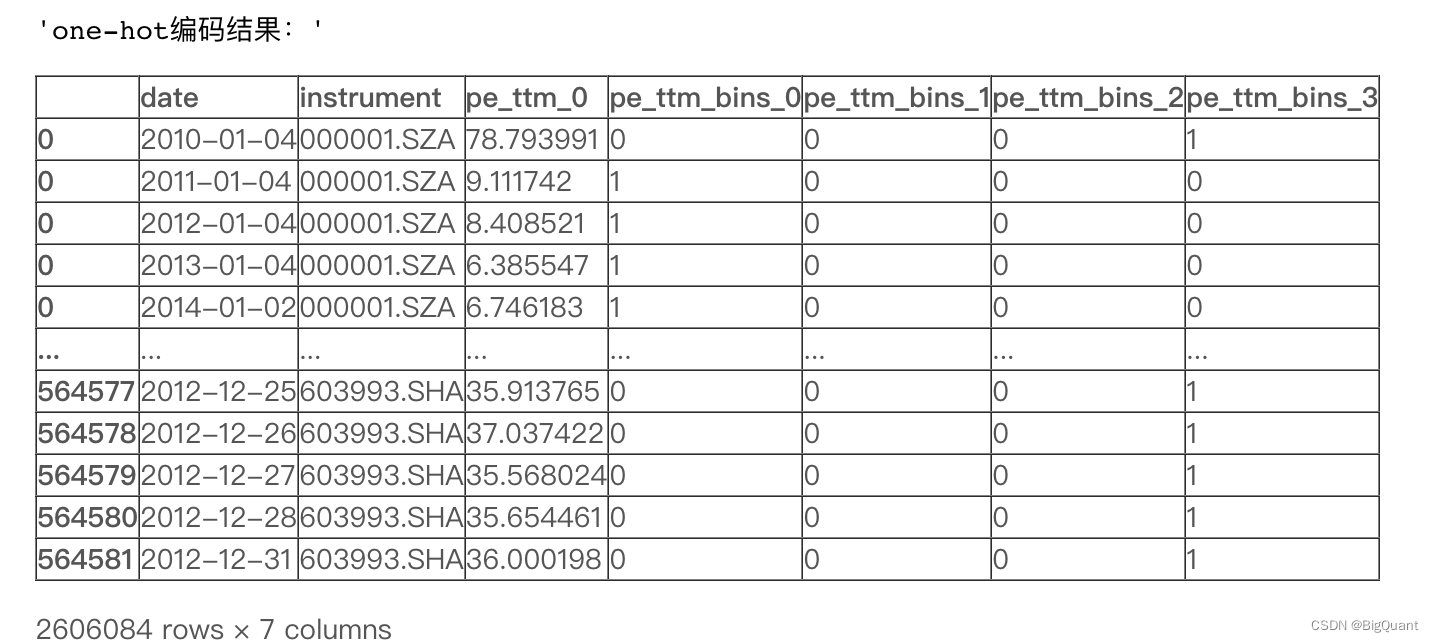
#换成one-hot编码
df = pd.get_dummies(df,columns=[col_name])
display("one-hot编码结果:",df[['date','instrument','pe_ttm_0','pe_ttm_bins_0','pe_ttm_bins_1','pe_ttm_bins_2','pe_ttm_bins_3']])
输出结果
源码克隆
讲解视频
可以详细看工程师的视频讲解:
如何对连续性数据进行离散化处理
如何对连续型数据进行离散化处理,并进行OneHot编码?的更多相关文章
- 处理离散型特征和连续型特征共存的情况 归一化 论述了对离散特征进行one-hot编码的意义
转发:https://blog.csdn.net/lujiandong1/article/details/49448051 处理离散型特征和连续型特征并存的情况,如何做归一化.参考博客进行了总结:ht ...
- 【书签】连续型特征的归一化和离散特征的one-hot编码
1. 连续型特征的常用的归一化方法.离散型特征one-hot编码的意义 2. 度量特征之间的相关性:余弦相似度和皮尔逊相关系数
- sklearn连续型数据离散化
二值化 设置一个condition,把连续型的数据分类两类.比如Age,大于30,和小于30. from sklearn.preprocessing import Binerize as Ber x ...
- 数据预处理之独热编码(One-Hot):为什么要使用one-hot编码?
一.问题由来 最近在做ctr预估的实验时,还没思考过为何数据处理的时候要先进行one-hot编码,于是整理学习如下: 在很多机器学习任务如ctr预估任务中,特征不全是连续值,而有可能是分类值.如下: ...
- 【转】数据预处理之独热编码(One-Hot Encoding)
原文链接:http://blog.csdn.net/dulingtingzi/article/details/51374487 问题由来 在很多机器学习任务中,特征并不总是连续值,而有可能是分类值. ...
- 数据预处理:独热编码(One-Hot Encoding)
python机器学习-sklearn挖掘乳腺癌细胞( 博主亲自录制) 网易云观看地址 https://study.163.com/course/introduction.htm?courseId=10 ...
- One-hot数据处理
机器学习 数据预处理之独热编码(One-Hot Encoding)(转) 问题由来 在很多机器学习任务中,特征并不总是连续值,而有可能是分类值. 例如,考虑一下的三个特征: ["male&q ...
- 我的python面试简历
分享前一段我的python面试简历,自我介绍这些根据你自己的来写就行,这里着重分享下我的项目经验.公司职责情况(时间倒序),不一定对每个人适用,但是有适合你的点可以借鉴 我的真实经验:(14年毕业,化 ...
- 机器学习入门-数值特征-连续数据离散化(进行分段标记处理) 1.hist(Dataframe格式直接画直方图)
函数说明: 1. .hist 对于Dataframe格式的数据,我们可以使用.hist直接画出直方图 对于一些像年龄和工资一样的连续数据,我们可以对其进行分段标记处理,使得这些连续的数据变成离散化 就 ...
- SPSS常用基础操作(2)——连续变量离散化
首先说一下什么是离散化以及连续变量离散化的必要性. 离散化是把无限空间中无限的个体映射到有限的空间中去,通俗点讲就是把连续型数据切分为若干“段”,也称bin,离散化在数据分析中特别是数据挖掘中被普遍采 ...
随机推荐
- OpenStack-T版+Ceph
OpenStack OpenStack 中有哪些组件 keystone:授权 [授权后各个组件才可以进行相应的功能] Keystone 认证所有 OpenStack 服务并对其进行授权.同时,它也是所 ...
- Linq关联两个DataTable合并为一个DataTable
DataSet ds ; DataTable dt1= ds.Tables[0]; DataTable dt2= ds.Tables[1]; //关联 var res = from m in dt1. ...
- 代码检视的新姿势!在IDEA中得到沉浸式Code Review新体验
大家好,好久不见,又见面了. 在消失的这段时间里,我做了件大事,见证了儿子的出生并陪伴其一天天的成长.停止更文的200多天里,还能得到小伙伴们持续的支持,让我备受鼓励.对一个技术人员而言,分享技术观点 ...
- 4.1 应用层Hook挂钩原理分析
InlineHook 是一种计算机安全编程技术,其原理是在计算机程序执行期间进行拦截.修改.增强现有函数功能.它使用钩子函数(也可以称为回调函数)来截获程序执行的各种事件,并在事件发生前或后进行自定义 ...
- (数据科学学习手札154)geopandas 0.14版本新特性一览
本文示例代码已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 大家好我是费老师,就在前两天,Python生态中 ...
- MySQL实战实战系列 06 全局锁和表锁 :给表加个字段怎么有这么多阻碍?
今天我要跟你聊聊 MySQL 的锁.数据库锁设计的初衷是处理并发问题.作为多用户共享的资源,当出现并发访问的时候,数据库需要合理地控制资源的访问规则.而锁就是用来实现这些访问规则的重要数据结构. 根据 ...
- 7 个 IntelliJ IDEA 必备插件,显著提升编码效率
首先说一下idea引入外部插件的方式 用插件 1. FindBugs-IDEA 2. Maven Helper 3. VisualVM Launcher 4. GenerateAllSetter 5. ...
- c语言代码练习10
//判断输入的数字是否为素数#define _CRT_SECURE_NO_WARNINGS 1 #include <stdio.h> int main() { int n = 0; int ...
- PostgreSQL学习笔记-7.基础知识:子查询、自增、PRIVILEGES 权限
子查询 子查询或称为内部查询.嵌套查询,指的是在 PostgreSQL 查询中的 WHERE 子句中嵌入查询语句.一个 SELECT 语句的查询结果能够作为另一个语句的输入值.子查询可以与 SELEC ...
- ActivityNotFoundException
activity 加入 AndroidManifest android.content.ActivityNotFoundException: Unable to find explicit acti ...