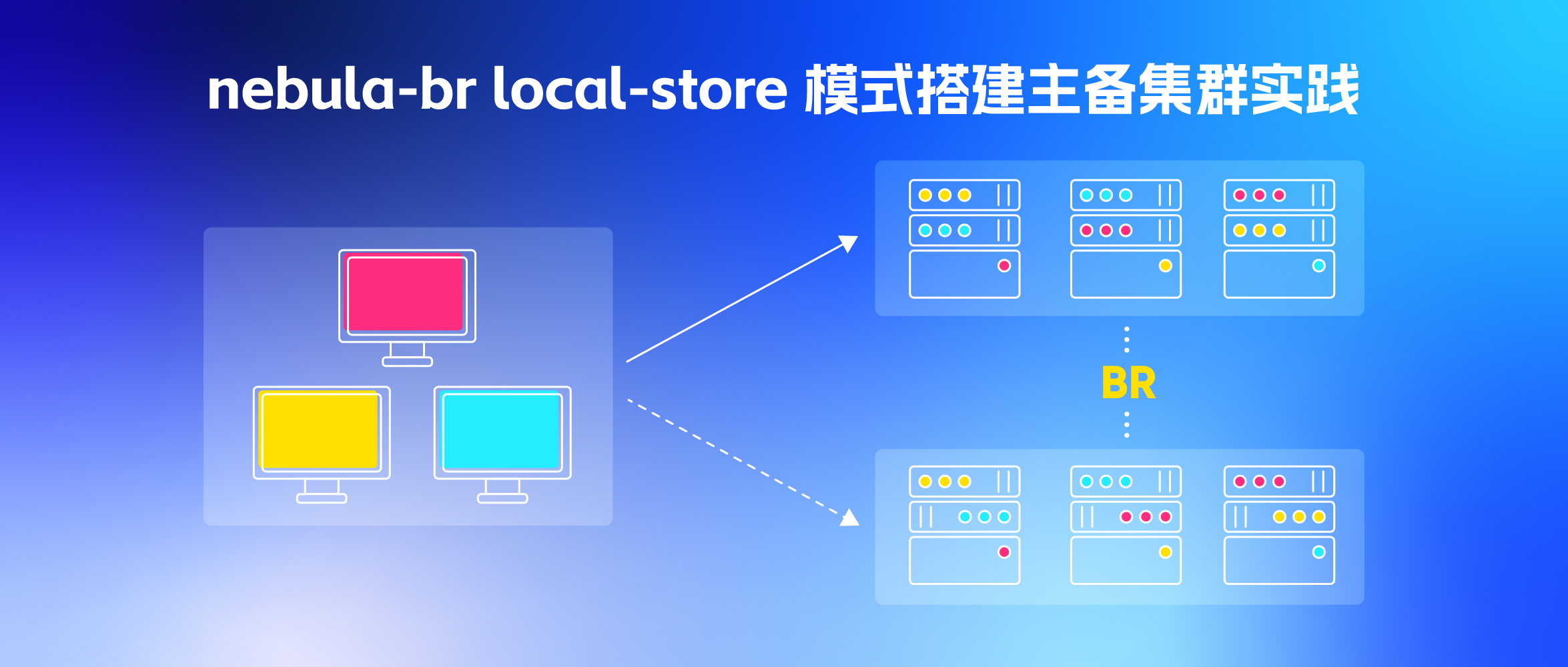
nebula-br local-store 模式,快速搭建主备集群实践
因为线上图数据库目前为单集群,数据量比较大,有以下缺点:
- 单点风险,一旦集群崩溃或者因为某些查询拖垮整个集群,就会导致所有图操作受影响
- 很多优化类但会影响读写的操作不好执行,比如:compact、balance leader 等;
- 双集群在升级的时候也非常有优势,完全可以做到不影响业务运行,比如先升级备集群再升级主集群。总之为了线上数据库更加稳定和高可用需要搭建双集群。
选择 BR 工具的原因
目前,我这边了解到复制集群方案有:
- 新集群重新写入数据,这种情况要么就是写程序 scan 再导入新集群(太慢了),要么就基于底表数据通过 nebula-exchange 再导入新集群(必须得有历史数据)
- (不可靠)完整复制 nebula 数据拷贝到新集群,参考:【复制 data 方式导入】(不过,这个方式我在测试环境测试失败了)
- 通过 nebula-br 备份,再还原到新集群(本文就是基于这种方式)
因为我们线上很难回溯出完整的历史数据,无法基于底表重新构建,此外 scan 方式又太慢了,所以选择了 BR 的方式。
注意:
环境介绍
- nebula 版本:3.6.0
- nebula 安装路径:
/usr/local/nebula - nebula-metad 服务端口:9559 (可以通过安装目录下的
scripts/nebula-metad status查看) - backup 目录:
/usr/local/nebula_backup
备份方式:full(全图备份,也可以指定部分 space)
- 3 台老集群机器(已经有历史数据的):192.168.1.2、192.168.1.3、192.168.1.4
- 3 台新集群机器(没有数据,待从老集群复制数据):192.168.2.2、192.168.2.3、192.168.2.4
备份前新集群 show hosts 情况:

备份前老集群 show hosts 情况:

大体步骤
- 老集群安装 agent(每台机器都要安装)和 br(选择任何其中一台机器安装)工具;
- 新集群安装 agent(每台机器都要安装);
- 在老集群安装 br 的机器上,利用 br 工具生成备份文件,备份 meta 执行老集群的 meta 地址;
- 复制 meta 文件,老集群中只有一台机器的备份目录有 meta,需要将 meta 复制到老集群其他机器;
- 在新集群机器创建和老集群一样的备份目录,比如:老集群备份目录为
/usr/local/nebula_bak/BACKUP_2023_09_14_13_57_33,新集群机器需要创建相同的目录:/usr/local/nebula_bak/BACKUP_2023_09_14_13_57_33; - 复制老集群备份文件到新集群中,这里需要注意因为老集群每台机器都有自己的备份文件,这里需要将所有的备份文件复制到新集群中整合到一起,因为每台机器的 data 下的目录名称都是以
IP + PORT的形式,所以不会有重复; - 在老集群安装 br 的机器上,利用 br 工具恢复备份文件,恢复时 meta 指向新机器 meta 地址;
详细步骤
在老集群所有机器安装 agent,安装方法参考:angent 安装介绍,以当前示例为例,下载 nebula-agent 之后存放在 /usr/local/nebula/bin 目录下, 使用 chmod +x nebula-agent 赋予可执行权限:
192.168.1.2
nohup ./nebula-agent -agent="192.168.1.2:9999" -debug -meta="192.168.1.2:9559" > agent.log 2>&1 &
192.168.1.3
nohup ./nebula-agent -agent="192.168.1.3:9999" -debug -meta="192.168.1.3:9559" > agent.log 2>&1 &
192.168.1.4
nohup ./nebula-agent -agent="192.168.1.4:9999" -debug -meta="192.168.1.4:9559" > agent.log 2>&1 &
下载 br 工具到 nebula 的 bin 目录下,并命名为 nebula-br,并使用 chmod 命令赋予可执行权限。
此时老集群机器拓扑图:

(老集群)选择安装 br 工具的 192.168.1.4 机器执行如下命令进行备份:
./nebula-br backup full --meta="192.168.1.4:9559" --storage="local:///usr/local/nebula_backup"
(老集群)备份后每台机器的备份目录详情如图:

(老集群)复制 meta 到其他机器的备份目录下:
这里是从 192.169.1.2(只有这台机器生成了 meta,这玩意只有在 meta 的 leader 节点生成)机器复制到 192.168.1.3 和 192.168.1.4 机器目录下:

新集群安装 agent:
192.168.2.2
nohup ./nebula-agent -agent="192.168.2.2:9999" -debug -meta="192.168.2.2:9559" > agent.log 2>&1 &
192.168.2.3
nohup ./nebula-agent -agent="192.168.2.3:9999" -debug -meta="192.168.2.3:9559" > agent.log 2>&1 &
192.168.2.4
nohup ./nebula-agent -agent="192.168.2.4:9999" -debug -meta="192.168.2.4:9559" > agent.log 2>&1 &
新集群服务拓扑图:

复制老集群的备份文件到新集群机器下,完成后的拓扑图:
从老集群机器 /usr/local/nebula_backup 拷贝数据到新集群机器 /usr/local/nebula_backup 目录下

(老集群) 选择安装 br 工具的 192.168.1.4 机器执行如下命令进行还原到新集群,这里的 meta 指向新集群机器其中一台 meta 地址,storage 地址为上一步新集群创建的备份地址:
./nebula-br restore full --meta="192.168.2.4:9559" --storage="local:///usr/local/nebula_backup" --name="BACKUP_2023_09_14_13_57_33"
观察日志,不报错的情况下完成了从老集群机器还原到了新集群,可使用 nebula-console 连接新集群查看 space 情况。
新集群 show hosts 情况:

小结
官方其实不推荐 local 模式去做备份还原,操作太过复杂,很容易出错,建议使用 S3 或者 NTF 进行挂载,这样就没必要做老集群拷贝到新集群的工作。
本文正在参加 NebulaGraph 技术社区年度征文活动,征文详情:https://discuss.nebula-graph.com.cn/t/topic/13970
如果你觉得本文对你有所启发,记得给我点个 ️ ,谢谢你的鼓励
nebula-br local-store 模式,快速搭建主备集群实践的更多相关文章
- [转]使用keepalived搭建主备切换环境
使用keepalived搭建主备切换环境 时间 2016-09-15 08:00:00 cpper 原文 http://cpper.info/2016/09/15/keepalived-for-ma ...
- 使用kind快速搭建本地k8s集群
Kind是什么? k8s集群的组成比较复杂,如果纯手工部署的话易出错且时间成本高.而本文介绍的Kind工具,能够快速的建立起可用的k8s集群,降低初学者的学习门槛. Kind是Kubernetes I ...
- LVS+Keepalived-DR模式负载均衡高可用集群
LVS+Keepalived DR模式负载均衡+高可用集群架构图 工作原理: Keepalived采用VRRP热备份协议实现Linux服务器的多机热备功能. VRRP,虚拟路由冗余协议,是针对路由器的 ...
- 扩展Redis的Jedis客户端,哨兵模式读请求走Slave集群
原 扩展Redis的Jedis客户端,哨兵模式读请求走Slave集群 2018年12月06日 14:26:45 温故而知新666 阅读数 897 版权声明:本文为博主原创文章,遵循CC 4.0 b ...
- kubernetes(K8S)快速安装与配置集群搭建图文教程
kubernetes(K8S)快速安装与配置集群搭建图文教程 作者: admin 分类: K8S 发布时间: 2018-09-16 12:20 Kubernetes是什么? 首先,它是一个全新的基于容 ...
- 快速部署一个Kubernetes集群
官方提供的三种部署方式 minikube Minikube是一个工具,可以在本地快速运行一个单点的Kubernetes,仅用于尝试Kubernetes或日常开发的用户使用. 部署地址:https:// ...
- 使用 Bitnami PostgreSQL Docker 镜像快速设置流复制集群
bitnami-docker-postgresql 仓库 源码:bitnami-docker-postgresql https://github.com/bitnami/bitnami-docker- ...
- docker swarm快速部署redis分布式集群
环境准备 四台虚拟机 192.168.2.38(管理节点) 192.168.2.81(工作节点) 192.168.2.100(工作节点) 192.168.2.102(工作节点) 时间同步 每台机器都执 ...
- 基于 Sealos 的镜像构建能力,快速部署自定义 k8s 集群
Sealos 是一个快速构建高可用 k8s 集群的命令行工具,该工具部署时会在第一个 k8s master 节点部署 registry 服务(sealos.hub),该域名通过 hosts 解析到第一 ...
- Harbor快速部署到Kubernetes集群及登录问题解决
Harbor(https://goharbor.io)是一个功能强大的容器镜像管理和服务系统,用于提供专有容器镜像服务.随着云原生架构的广泛使用,原来由VMWare开发的Harbor也加入了云原生基金 ...
随机推荐
- 基于spring security创建基本项目框架
SpringBoot建项目步骤 建表 新建项目 (package name可以自定义,整个项目只能在该包下) 选择可能有到的依赖 (别忘了勾选SQL中的Mybatis Framework,创建项目 如 ...
- CouchDB vs. LevelDB
CouchDB 和 LevelDB 都是数据库系统,但它们在很多方面有着不同的设计和应用重点.下面是对这两个数据库在一些关键点上的对比: 数据模型: CouchDB:CouchDB 是一种面向文档的数 ...
- GitHub要求2FA?不慌,有它们帮你
近日,GitHub宣布,到 2023 年底,所有用户都必须要启用双因素身份验证 (2FA),不能只用密码啦. 正如GitHub的首席安全官Mike Hanley所指出的那样,保护开发者账号是确保软件供 ...
- TienChin 渠道管理-渠道搜索
ChannelController @PreAuthorize("hasPermission('tienchin:channel:list')") @GetMapping(&quo ...
- TienChin 渠道管理-前端展示渠道信息
在编写 Vue 项目的时候我们可以使用 IDEA 当中提供的一个工具叫做 structure,也就是说可以很轻松的列举出当前 Vue 文件的大致结构,点那个就会跳转到对应的地方. 简简单单介绍一个编写 ...
- 【心理学CPCI收录,AP独立出版】 2023年应用心理学与现代化教育国际学术会议(ICAPME 2023)
[心理学CPCI收录,AP独立出版] 2023年应用心理学与现代化教育国际学术会议(ICAPME 2023) 大会官网:www.icapme.org 大会时间:2023年9月22-24日 大会地点: ...
- win10下MySQL安装教程(MySql-8.0.26超级详细)
一.下载安装包: 官网链接:MySQL :: Developer Zone 依次点击步骤如下: 二.MySQL文件配置 解压安装包: 解压后的目录并没有的my.ini文件,没关系可以自行创建在安装根目 ...
- 推荐系统[三]:粗排算法常用模型汇总(集合选择和精准预估),技术发展历史(向量內积,Wide&Deep等模型)以及前沿技术
1.前言:召回排序流程策略算法简介 推荐可分为以下四个流程,分别是召回.粗排.精排以及重排: 召回是源头,在某种意义上决定着整个推荐的天花板: 粗排是初筛,一般不会上复杂模型: 精排是整个推荐环节的重 ...
- trick1---实现tensorflow和pytorch迁移环境教学
相关文章: [一]tensorflow安装.常用python镜像源.tensorflow 深度学习强化学习教学 [二]tensorflow调试报错.tensorflow 深度学习强化学习教学 [三]t ...
- 3.4 DLL注入:全局消息钩子注入
SetWindowHookEx 是Windows系统的一个函数,可用于让一个应用程序安装全局钩子,但读者需要格外注意该方法安装的钩子会由操作系统注入到所有可执行进程内,虽然该注入方式可以用于绕过游戏保 ...