nebula-br local-store 模式,快速搭建主备集群实践
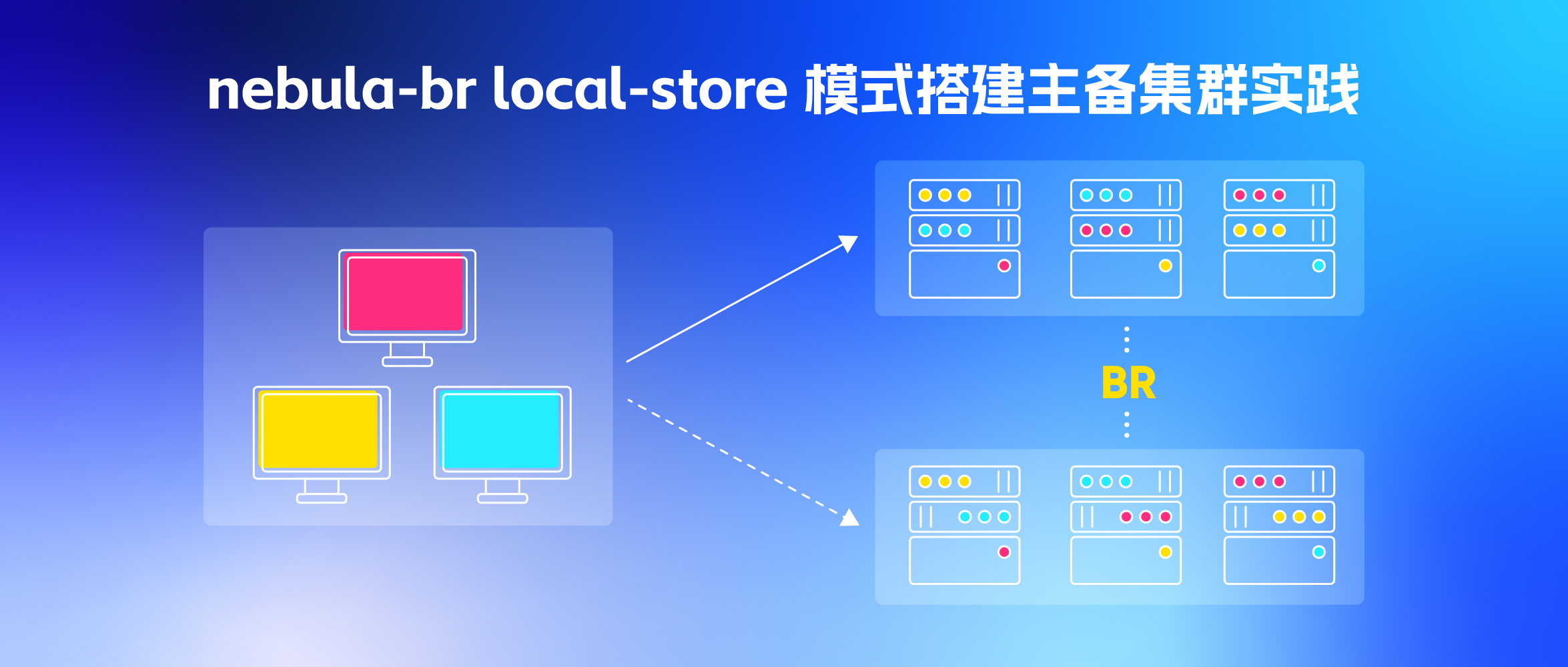
因为线上图数据库目前为单集群,数据量比较大,有以下缺点:
- 单点风险,一旦集群崩溃或者因为某些查询拖垮整个集群,就会导致所有图操作受影响
- 很多优化类但会影响读写的操作不好执行,比如:compact、balance leader 等;
- 双集群在升级的时候也非常有优势,完全可以做到不影响业务运行,比如先升级备集群再升级主集群。总之为了线上数据库更加稳定和高可用需要搭建双集群。
选择 BR 工具的原因
目前,我这边了解到复制集群方案有:
- 新集群重新写入数据,这种情况要么就是写程序 scan 再导入新集群(太慢了),要么就基于底表数据通过 nebula-exchange 再导入新集群(必须得有历史数据)
- (不可靠)完整复制 nebula 数据拷贝到新集群,参考:【复制 data 方式导入】(不过,这个方式我在测试环境测试失败了)
- 通过 nebula-br 备份,再还原到新集群(本文就是基于这种方式)
因为我们线上很难回溯出完整的历史数据,无法基于底表重新构建,此外 scan 方式又太慢了,所以选择了 BR 的方式。
注意:
环境介绍
- nebula 版本:3.6.0
- nebula 安装路径:
/usr/local/nebula - nebula-metad 服务端口:9559 (可以通过安装目录下的
scripts/nebula-metad status查看) - backup 目录:
/usr/local/nebula_backup
备份方式:full(全图备份,也可以指定部分 space)
- 3 台老集群机器(已经有历史数据的):192.168.1.2、192.168.1.3、192.168.1.4
- 3 台新集群机器(没有数据,待从老集群复制数据):192.168.2.2、192.168.2.3、192.168.2.4
备份前新集群 show hosts 情况:

备份前老集群 show hosts 情况:

大体步骤
- 老集群安装 agent(每台机器都要安装)和 br(选择任何其中一台机器安装)工具;
- 新集群安装 agent(每台机器都要安装);
- 在老集群安装 br 的机器上,利用 br 工具生成备份文件,备份 meta 执行老集群的 meta 地址;
- 复制 meta 文件,老集群中只有一台机器的备份目录有 meta,需要将 meta 复制到老集群其他机器;
- 在新集群机器创建和老集群一样的备份目录,比如:老集群备份目录为
/usr/local/nebula_bak/BACKUP_2023_09_14_13_57_33,新集群机器需要创建相同的目录:/usr/local/nebula_bak/BACKUP_2023_09_14_13_57_33; - 复制老集群备份文件到新集群中,这里需要注意因为老集群每台机器都有自己的备份文件,这里需要将所有的备份文件复制到新集群中整合到一起,因为每台机器的 data 下的目录名称都是以
IP + PORT的形式,所以不会有重复; - 在老集群安装 br 的机器上,利用 br 工具恢复备份文件,恢复时 meta 指向新机器 meta 地址;
详细步骤
在老集群所有机器安装 agent,安装方法参考:angent 安装介绍,以当前示例为例,下载 nebula-agent 之后存放在 /usr/local/nebula/bin 目录下, 使用 chmod +x nebula-agent 赋予可执行权限:
192.168.1.2
nohup ./nebula-agent -agent="192.168.1.2:9999" -debug -meta="192.168.1.2:9559" > agent.log 2>&1 &
192.168.1.3
nohup ./nebula-agent -agent="192.168.1.3:9999" -debug -meta="192.168.1.3:9559" > agent.log 2>&1 &
192.168.1.4
nohup ./nebula-agent -agent="192.168.1.4:9999" -debug -meta="192.168.1.4:9559" > agent.log 2>&1 &
下载 br 工具到 nebula 的 bin 目录下,并命名为 nebula-br,并使用 chmod 命令赋予可执行权限。
此时老集群机器拓扑图:

(老集群)选择安装 br 工具的 192.168.1.4 机器执行如下命令进行备份:
./nebula-br backup full --meta="192.168.1.4:9559" --storage="local:///usr/local/nebula_backup"
(老集群)备份后每台机器的备份目录详情如图:

(老集群)复制 meta 到其他机器的备份目录下:
这里是从 192.169.1.2(只有这台机器生成了 meta,这玩意只有在 meta 的 leader 节点生成)机器复制到 192.168.1.3 和 192.168.1.4 机器目录下:

新集群安装 agent:
192.168.2.2
nohup ./nebula-agent -agent="192.168.2.2:9999" -debug -meta="192.168.2.2:9559" > agent.log 2>&1 &
192.168.2.3
nohup ./nebula-agent -agent="192.168.2.3:9999" -debug -meta="192.168.2.3:9559" > agent.log 2>&1 &
192.168.2.4
nohup ./nebula-agent -agent="192.168.2.4:9999" -debug -meta="192.168.2.4:9559" > agent.log 2>&1 &
新集群服务拓扑图:

复制老集群的备份文件到新集群机器下,完成后的拓扑图:
从老集群机器 /usr/local/nebula_backup 拷贝数据到新集群机器 /usr/local/nebula_backup 目录下

(老集群) 选择安装 br 工具的 192.168.1.4 机器执行如下命令进行还原到新集群,这里的 meta 指向新集群机器其中一台 meta 地址,storage 地址为上一步新集群创建的备份地址:
./nebula-br restore full --meta="192.168.2.4:9559" --storage="local:///usr/local/nebula_backup" --name="BACKUP_2023_09_14_13_57_33"
观察日志,不报错的情况下完成了从老集群机器还原到了新集群,可使用 nebula-console 连接新集群查看 space 情况。
新集群 show hosts 情况:

小结
官方其实不推荐 local 模式去做备份还原,操作太过复杂,很容易出错,建议使用 S3 或者 NTF 进行挂载,这样就没必要做老集群拷贝到新集群的工作。
本文正在参加 NebulaGraph 技术社区年度征文活动,征文详情:https://discuss.nebula-graph.com.cn/t/topic/13970
如果你觉得本文对你有所启发,记得给我点个 ️ ,谢谢你的鼓励
nebula-br local-store 模式,快速搭建主备集群实践的更多相关文章
- [转]使用keepalived搭建主备切换环境
使用keepalived搭建主备切换环境 时间 2016-09-15 08:00:00 cpper 原文 http://cpper.info/2016/09/15/keepalived-for-ma ...
- 使用kind快速搭建本地k8s集群
Kind是什么? k8s集群的组成比较复杂,如果纯手工部署的话易出错且时间成本高.而本文介绍的Kind工具,能够快速的建立起可用的k8s集群,降低初学者的学习门槛. Kind是Kubernetes I ...
- LVS+Keepalived-DR模式负载均衡高可用集群
LVS+Keepalived DR模式负载均衡+高可用集群架构图 工作原理: Keepalived采用VRRP热备份协议实现Linux服务器的多机热备功能. VRRP,虚拟路由冗余协议,是针对路由器的 ...
- 扩展Redis的Jedis客户端,哨兵模式读请求走Slave集群
原 扩展Redis的Jedis客户端,哨兵模式读请求走Slave集群 2018年12月06日 14:26:45 温故而知新666 阅读数 897 版权声明:本文为博主原创文章,遵循CC 4.0 b ...
- kubernetes(K8S)快速安装与配置集群搭建图文教程
kubernetes(K8S)快速安装与配置集群搭建图文教程 作者: admin 分类: K8S 发布时间: 2018-09-16 12:20 Kubernetes是什么? 首先,它是一个全新的基于容 ...
- 快速部署一个Kubernetes集群
官方提供的三种部署方式 minikube Minikube是一个工具,可以在本地快速运行一个单点的Kubernetes,仅用于尝试Kubernetes或日常开发的用户使用. 部署地址:https:// ...
- 使用 Bitnami PostgreSQL Docker 镜像快速设置流复制集群
bitnami-docker-postgresql 仓库 源码:bitnami-docker-postgresql https://github.com/bitnami/bitnami-docker- ...
- docker swarm快速部署redis分布式集群
环境准备 四台虚拟机 192.168.2.38(管理节点) 192.168.2.81(工作节点) 192.168.2.100(工作节点) 192.168.2.102(工作节点) 时间同步 每台机器都执 ...
- 基于 Sealos 的镜像构建能力,快速部署自定义 k8s 集群
Sealos 是一个快速构建高可用 k8s 集群的命令行工具,该工具部署时会在第一个 k8s master 节点部署 registry 服务(sealos.hub),该域名通过 hosts 解析到第一 ...
- Harbor快速部署到Kubernetes集群及登录问题解决
Harbor(https://goharbor.io)是一个功能强大的容器镜像管理和服务系统,用于提供专有容器镜像服务.随着云原生架构的广泛使用,原来由VMWare开发的Harbor也加入了云原生基金 ...
随机推荐
- MySQL控制权限
编写顺序和执行顺序是不一样的 编写顺序: SELECT 字段列表 FROM 表名列表 WHERE 条件列表 GROUP BY 分组字段列表 HAVING 分组后条件列表 ORDER BY 排序字段列表 ...
- elementui中表格表头设置背景色
参考的地址: https://www.cnblogs.com/lljun/p/11551128.html 今天在设置表格的表头的时候,我通过类的时候 发现无法设置表格的表头设置不了颜色: 经过查找:原 ...
- Linux慢 进程kswapd0与events/0消耗大量CPU的问题 一次网站宕机的处理
今天下午网站宕了两次机,发工单给阿里云,发现原因是服务器的CPU 100%了. 重启服务器后,使用 top 命令看看是哪些进程消耗那么大的 CPU 使用.盯了有好十几分钟,主要消耗 CPU 的进程有两 ...
- 几种方法验证unity是否为development build
我在月初接入了uwa的性能测试SDK,需要提交一个development build的游戏安装包给uwa进行真人真机测试,本文说下如何判断安装包是否为development build. 直观上判断 ...
- Flask WTForms 表单插件的使用
在Web应用中,表单处理是一个基本而常见的任务.Python的WTForms库通过提供表单的结构.验证和渲染等功能,简化了表单的处理流程.与此同时,Flask的扩展Flask-WTF更进一步地整合了W ...
- 手把手教你-把Kali Linux系统安装到U盘 【超详细】(随身携带/即插即用)
[0-背景说明]: 1)为什么想要把Kali Linux系统安装到U盘? 之前学习渗透测试的时候,有安装过虚拟机,在虚拟机上安装Kali Linux系统,但是因为是在现有系统上安装虚拟机又安装kali ...
- 捉虫日记:使用OpenGL加载模型 (2023/12/11)
前天晚上,花了一个小时解决了编译Assimp时的报错问题,顺便写了篇随笔.今天继续OpenGL的学习,不出意料地再次踩坑,好在最后都解决了. 今天主要学习使用Assimp加载模型,原理很简单: ...
- Mac上SnailSvn checkout报错
- Power BI 6 DAY
Power BI 数据建模与数据汇总分析 层级关系 跨表取字段时类型二可用 父子级关系条件 一个父级下对应多个子级值 一个子级值只属于一个父级 跨表取字段的条件:维度连接用关键字段间是父子级关系时,可 ...
- NC25879 外挂
题目链接 题目 题目描述 我的就是我的,你也是我的,记住了,狐狸! --韩信-白龙吟 对于打赌输了的小T会遭受到制裁,小s修改了数据库使他可以派出许多军队来围攻小T. 很不幸,小T与小s打赌打输了 ...