Prometheus 聚合查询的两个方案
问题背景
多个 Prometheus 集群或者多个 VictoriaMetrics 集群,在 Grafana 和夜莺里通常需要创建多个不同的数据源,这也就意味着,数据没法聚合查询,比如统一做一下 sum 之类的运算会比较麻烦,本文讲述两种 Prometheus 生态的聚合查询方案,以供参考。
场景模拟
我在本地模拟一个这样的场景:两套时序库,比如一套采集的 tomcat 相关机器的指标,一套采集的 oracle 相关机器的指标,相当于按业务切分的两套时序库。这里涉及三个组件:
- node_exporter:仅用于模拟提供监控指标
- prometheus9090:监听在 9090 端口的 prometheus,用于采集 node_exporter 的监控指标,会为数据附加上
service="tomcat"的标签,表示这是 tomcat 业务的监控指标 - prometheus9091:监听在 9091 端口的 prometheus,用于采集 node_exporter 的监控指标,会为数据附加上
service="oracle"的标签,表示这是 oracle 业务的监控指标
prometheus9090 的配置文件 prometheus.9090.yml 如下:
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: "node_exporter"
static_configs:
- targets: ["localhost:9100"]
labels:
service: tomcatprometheus9091 的配置文件 prometheus.9091.yml 如下:
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: "node_exporter"
static_configs:
- targets: ["localhost:9100"]
labels:
service: oracle最后,我把这俩时序库作为数据源配置到夜莺中,你也可以使用 Grafana 测试,分别查询这俩数据源,得到预期结果。
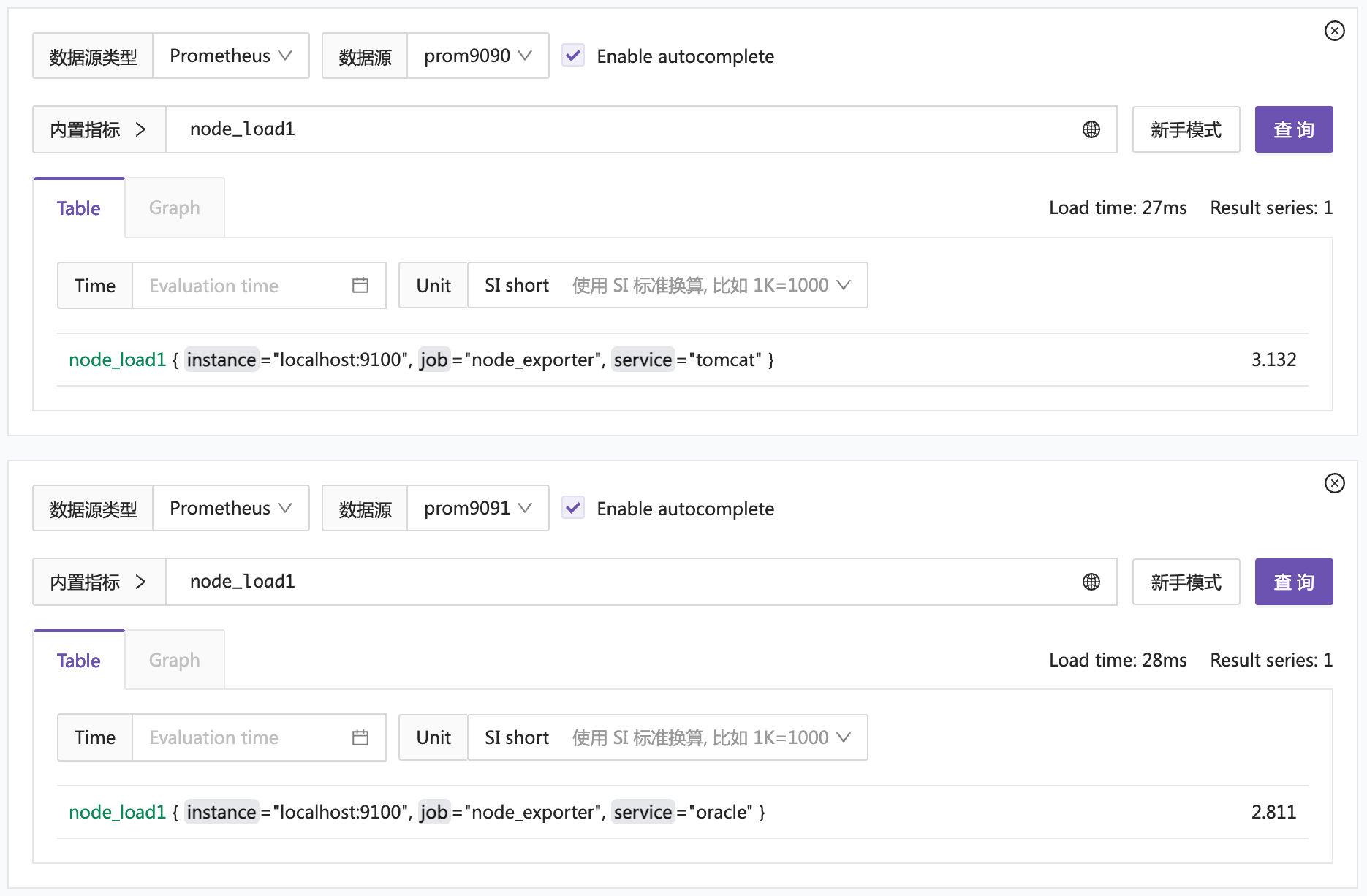
下面我们来看看如何聚合查询这两个数据源。
方案一:promxy
看这个名字就知道了,定位就是 prometheus 的 proxy,promxy 的 Github 地址是:https://github.com/jacksontj/promxy。按照 README 去安装就可以了,我的 promxy 的配置文件内容如下:
global:
evaluation_interval: 5s
promxy:
server_groups:
- static_configs:
- targets:
- localhost:9090
- static_configs:
- targets:
- localhost:9091然后,把 promxy 作为数据源配置到夜莺或者 Grafana 中,注意 promxy 默认监听的端口是 8082,之后,就可以查询这个数据源的数据做测试了。
先查个简单的:node_load1
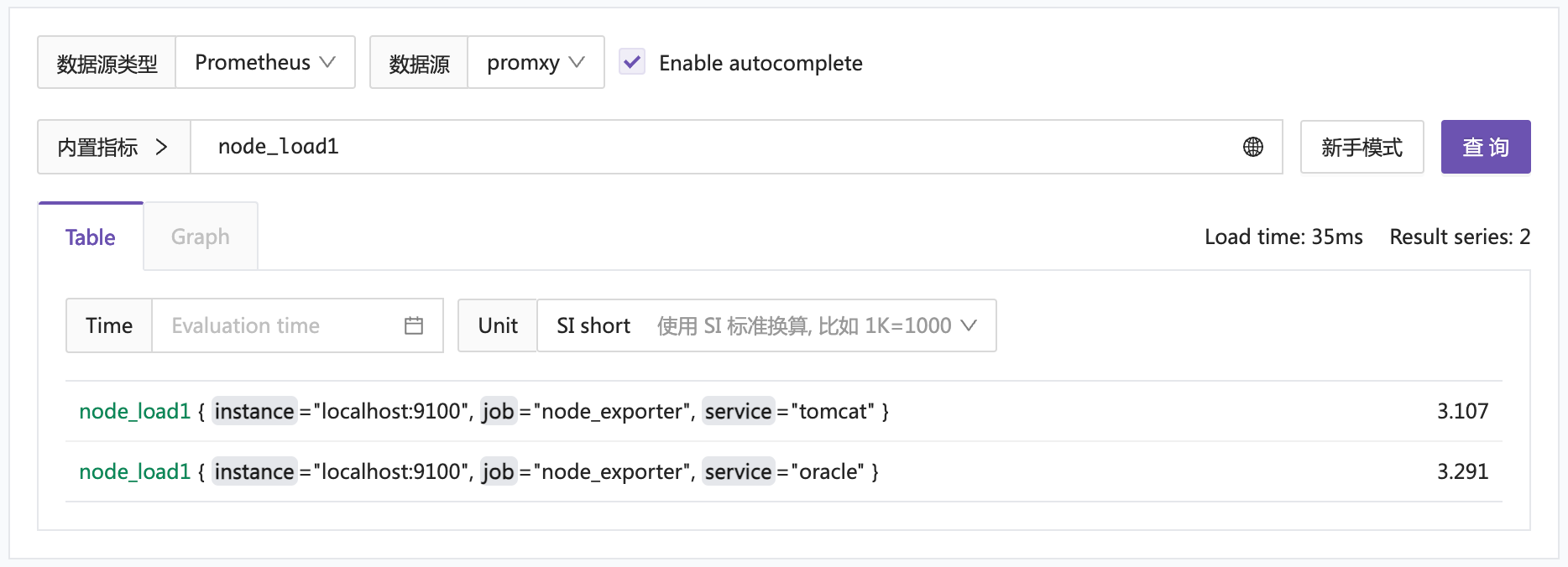
同时查到了两个时序库的数据,挺好的。然后做个聚合查询测试:
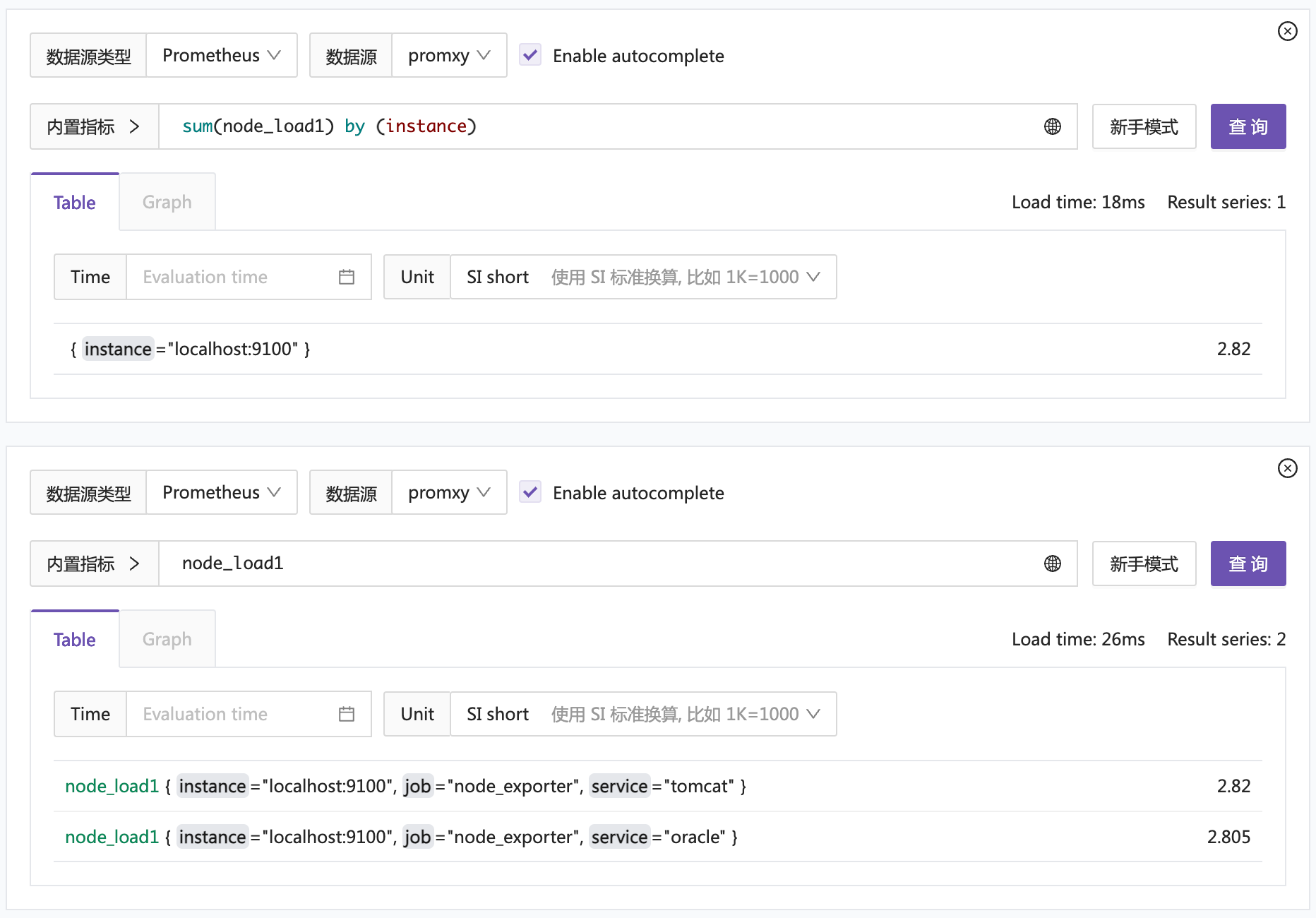
完犊子了,这个 sum 并未生效,看起来像是只查询了一个时序库的数据。这是个很基本的场景,不应该有 bug 才对,为啥会如此呢?我尝试两个解决办法:
- 在夜莺资深用户群扔了这个问题,资深群都是监控重度用户,可能有用过 promxy 的
- 下载了 promxy 的代码,准备从代码找找线索
资深群里确实有人用,有朋友提醒,promxy 中有个 server_group 的概念,是否应该为不同的 server_group 附加不同的标签呢?我直观感觉,应该是不需要的,因为这已经是多个 server_group 了,已经可以区分了才对,而且 TSDB 里已经有 service 标签做区分了。但是,我还是尝试了一下,修改 promxy 的配置文件如下:
global:
evaluation_interval: 5s
promxy:
server_groups:
- static_configs:
- targets:
- localhost:9090
labels:
region: a
- static_configs:
- targets:
- localhost:9091
labels:
region: b额外附加了 region 的标签。然后重启 promxy 再次查询:
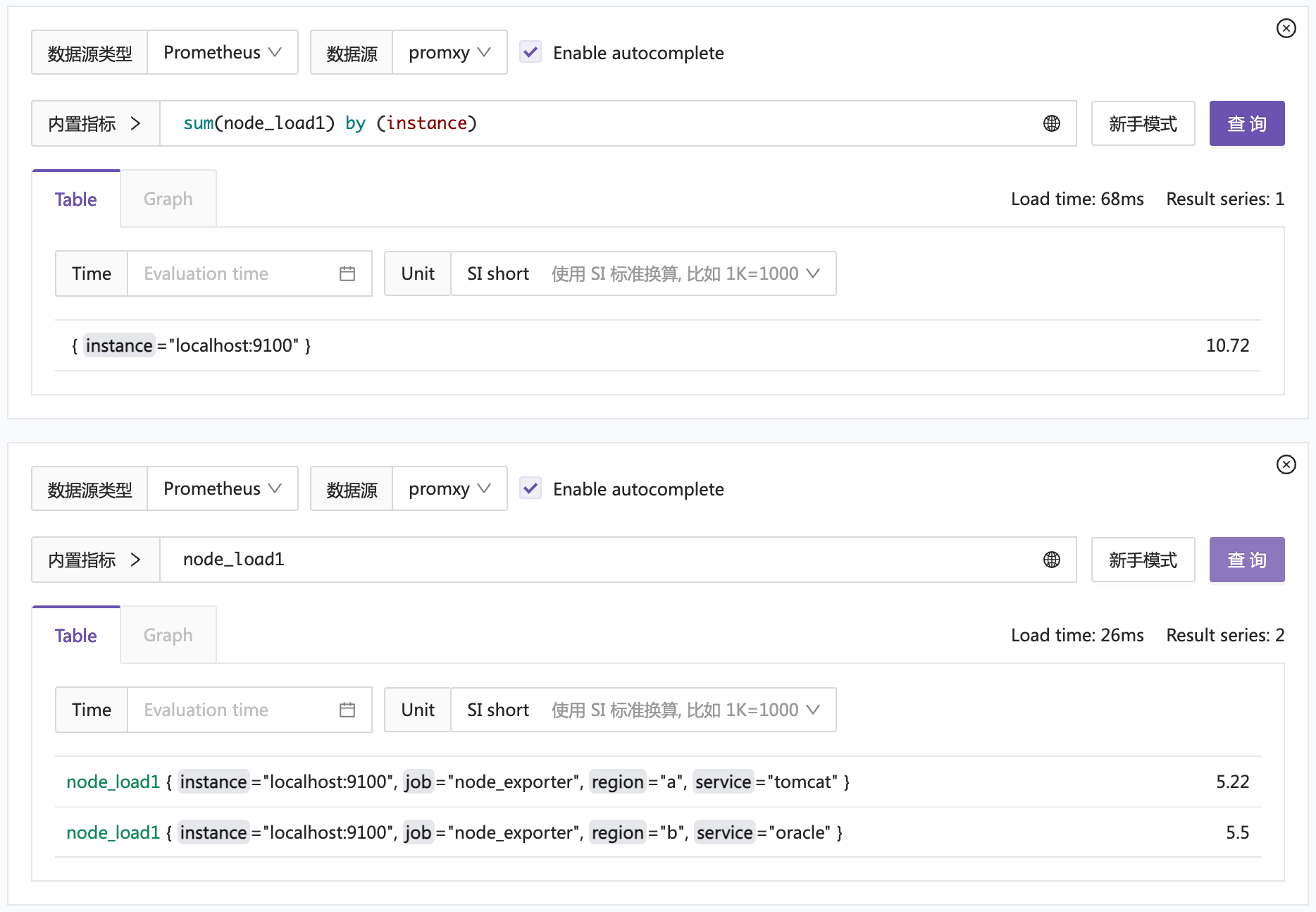
竟然就行了,哈哈。好吧,群里的朋友也反馈,之前他们没有踩到这个坑,是因为他们默认就给附加了标签。也不知道是 promxy 的 bug 还是有意为之。反正大家注意就好了。
方案二:Prometheus remote read
实际上,Prometheus 自身提供 remote read 能力,可以使用这个能力做聚合。我继续启动了一个 Prometheus 进程,监听在 9092 端口,配置文件 prometheus.9092.yml 如下:
global:
scrape_interval: 15s
evaluation_interval: 15s
remote_read:
- url: http://localhost:9090/api/v1/read
- url: http://localhost:9091/api/v1/read把 9090 和 9091 作为 remote read 后端配上即可。然后把 9092 这个 Prometheus 作为数据源配置到夜莺或者 Grafana 中,查询这个数据源的数据做测试。
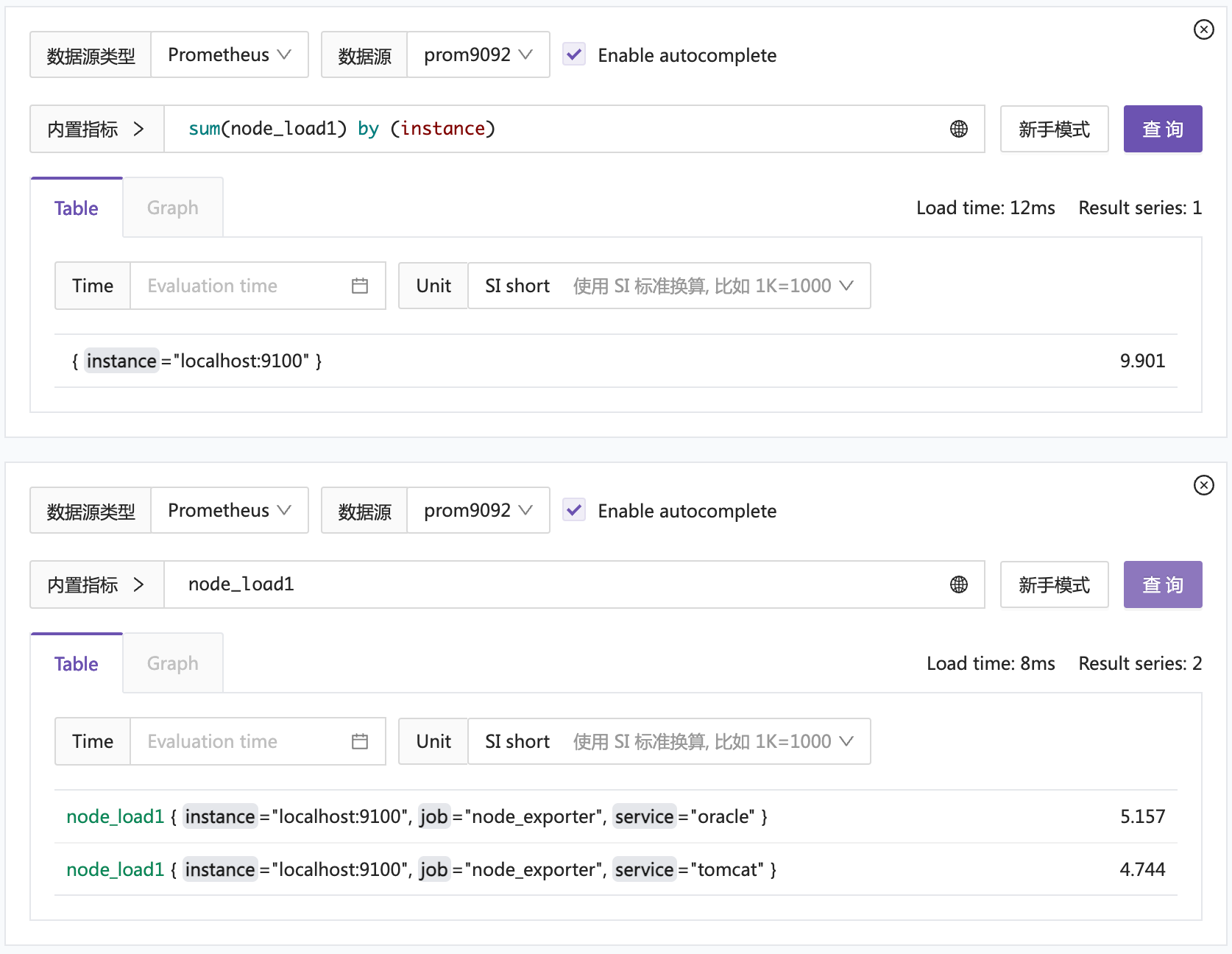
看起来是没问题的,不管是直接查询简单的 selector,还是聚合查询,都没问题。挺好的。
方案对比
首先,Prometheus remote read 方案,在编写 promql 的时候没有提示:

而 promxy 方案有提示:

这个原因是 remote read 方案只能查监控数据,没法查索引,自然也就没法有 suggestion 了。
其次,Prometheus read remote 只能查询那些支持 remote read 的后端,比如 VictoriaMetrics 就不支持 remote read,如果你的后端是 VictoriaMetrics,就只能使用 promxy 了。
如上,希望可以帮到你 :)
另外,本人创业两年了,我们公司主要是做监控、可观测性。我们希望通过合作努力,让中小公司具备行业顶尖的监控/可观测性能力,如果你有这方面的需求,欢迎联系我们:
Prometheus 聚合查询的两个方案的更多相关文章
- MongoDB的使用学习之(七)MongoDB的聚合查询(两种方式)附项目源码
先来张在路上…… 铛铛铛……项目源码下载地址:http://files.cnblogs.com/ontheroad_lee/MongoDBDemo.rar 此项目是用Maven创建的,没有使用Mave ...
- 3W字干货深入分析基于Micrometer和Prometheus实现度量和监控的方案
前提 最近线上的项目使用了spring-actuator做度量统计收集,使用Prometheus进行数据收集,Grafana进行数据展示,用于监控生成环境机器的性能指标和业务数据指标.一般,我们叫这样 ...
- 7.prometheus之查询API
一.格式概述 二.表达式查询 2.1 Instant queries(即时查询) 2.2 范围查询 三.查询元数据 3.1 通过标签匹配器找到度量指标列表 3.2 获取标签名 3.3 查询标签值 四. ...
- ElasticSearch(ES)使用Nested结构存储KV及聚合查询
自建博客地址:https://www.bytelife.net,欢迎访问! 本文为博客同步发表文章,为了更好的阅读体验,建议您移步至我的博客 本文作者: Jeffrey 本文链接: https://w ...
- mongodb高级聚合查询
在工作中会经常遇到一些mongodb的聚合操作,特此总结下.mongo存储的可以是复杂类型,比如数组.对象等mysql不善于处理的文档型结构,并且聚合的操作也比mysql复杂很多. 注:本文基于 mo ...
- ThinkPHP 数据库操作(四) : 聚合查询、时间查询、高级查询
聚合查询 在应用中我们经常会用到一些统计数据,例如当前所有(或者满足某些条件)的用户数.所有用户的最大积分.用户的平均成绩等等,ThinkPHP为这些统计操作提供了一系列的内置方法,包括: 用法示例: ...
- Django-model聚合查询与分组查询
Django-model聚合查询与分组查询 聚合函数包含:SUM AVG MIN MAX COUNT 聚合函数可以单独使用,不一定要和分组配合使用:不过聚合函数一般和group by 搭配使用 agg ...
- python全栈开发day68-ORM操作:一般操作、ForeignKey操作、ManyToManyField、聚合查询和分组查询、F查询和Q查询等
ORM操作 https://www.cnblogs.com/maple-shaw/articles/9403501.html 一.一般操作 1. 必知必会13条 <1> all(): 查询 ...
- django聚合查询
聚合¶ Django 数据库抽象API 描述了使用Django 查询来增删查改单个对象的方法.然而,有时候你需要获取的值需要根据一组对象聚合后才能得到.这份指南描述通过Django 查询来生成和返回聚 ...
- python 全栈开发,Day74(基于双下划线的跨表查询,聚合查询,分组查询,F查询,Q查询)
昨日内容回顾 # 一对多的添加方式1(推荐) # book=Book.objects.create(title="水浒传",price=100,pub_date="164 ...
随机推荐
- 各位 PHPer,Serverless 正当时
简介:PHP 作为一个开发群体的很大的语言其应用范围相当广泛,Serverless 的理念和 PHP 语言的理念都是让开发者最大精力集中在自己的业务价值.那么 PHP 遇见 Serverless 会 ...
- C++ 多态与虚拟:Class 语法语义
1.object与class:在object-oriented programming编程领域,对象(object)有更严格的定义.对象是由数据结构和用于处理该结构的过程(称为methods)组成的实 ...
- [Go] Golang defer 与 MySQL 连接关闭的陷阱 (database is closed)
在 golang 某些 orm 中,你经常会看到这种用法: func main() { db, err := gorm.Open("sqlite3", "test.db& ...
- Unity3D OpenVR 虚拟现实 保龄球打砖块游戏开发
据说水哥买了 Valve Index 设备,既然这个设备这么贵,不开发点有(zhi)趣(zhang)游戏就感觉对不起这个设备.本文将来开始着手开发一个可玩性不大,观赏性极强的保龄球打砖块游戏.这仅仅只 ...
- aspnetcore两种上传图片(文件)的方式
aspnetcore上传图片也就是上传文件有两种方式,一种是通过form-data,一种是binary. 先介绍第一种form-data: 该方式需要显示指定一个IFormFile类型,该组件会动态通 ...
- C语言程序设计-笔记7-指针
C语言程序设计-笔记7-指针 例8-1 利用指针模拟密码开锁游戏. #include<stdio.h> int main(void) { int x=5342; //变 ...
- 通过虚拟机镜像部署zabbix
前言 由于基础镜像的缘故,zabbix部署过程中很可能出现各种缺少依赖包的情况,如果环境中又无法连接互联网,系统部署会非常麻烦.为此zabbix官方提供了虚拟机镜像,导入后可以直接在平台上拉起虚拟机, ...
- Web3连接以太网
1. Infura Infura 是一种托管服务,提供对各种区块链网络的安全可靠访问,消除了管理区块链基础设施的复杂性,使开发者能够专注于构建创新的 Web3 应用程序. Infura 作为连接应用程 ...
- SpringMVC 项目集成 PageOffice V6 最简单代码
本文描述了PageOffice产品在SpringMVC项目中如何集成调用. 新建SpringMVC项目:pageoffice6-springmvc-simple 在您项目的pom.xml中通过下面的代 ...
- 用pageOffice控件实现 office word文档在线编辑 表格中写数据的方法
PageOffice对Word文档中Table的操作,包括给单元格赋值和动态添加行的效果. 1 应用场景 OA办公中,经常要在文档的指定位置表格,填充后端指定数据. 如word文档中,表格数据 如下表 ...