kubernets之横向伸缩pod与集群节点
一 pod的自动伸缩容的应用背景
在面对负载并发过高的时候,我们或许希望能够提高RS,RC以及Deployment等的replicas的参数来增加pod的cpu,mem等,或者是通过提高每个容器的requests的值,进而来提升系统的负载能力,但是我们可以通过手动的方式去调节RS,RC以及deployment的replicas的值,但是在面对突如其来的高负载进入,又或者是在夜深人静的夜晚突然到来的流量,通过手动的方式去扩容这些pod的方法,在某种意义上面而言,显得过于劳民伤财,并且也不一定及时。
二 pod的横向自动伸缩
2.1 横向pod的自动伸缩是指由控制器管理的pod副本数量的自动伸缩功能,它由Horizontal控制器执行,我们需要通过创建一个HorizontalpodAutoSccler(HPA)资源来启用和配置Horizontal的控制器,该控制器周期性检查pod度量,计算满足HPA资源目标值所需的副本数量,进而调整目标资源的replcas的数量来实现自动化伸缩。
- 获取被伸缩的pod资源对象所管理pod的度量
- 计算使目标资源度量数值接近或者达到目标数值所需的pod数量
- 更新被伸缩资源的replicas字段
2.2 获取pod的度量
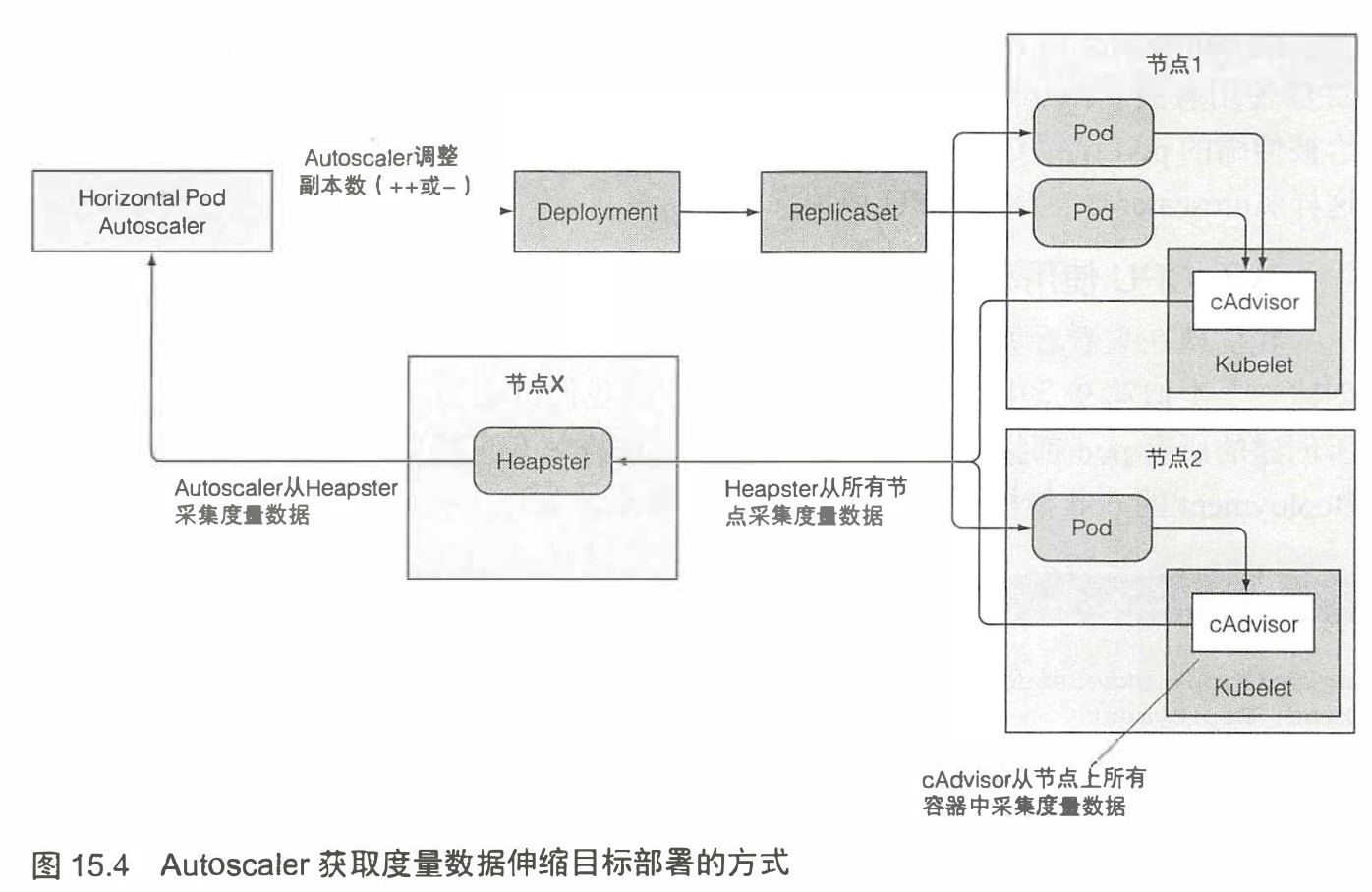
大概流程是每个节点上面的kubelet上面的cAdvsor的agent会去采集该节点上面的所有pod的资源使用量,之后这些数据将由集群级别的组件Heapster聚会,HPA控制器向Heapster发起post
请求调用所有pod的数量度量,整个数据的 采集调用链如图所示:

2.3 计算所需的pod数量
对于只一个指标例如cpu的度量,只需要采集节点上面的cpu消耗之和,之后除以标准的值就是那个时刻该pod的最佳量,当然遇到分数或者小数的时候进行取整,也就是需要调整到的量
但是对于多个需要的度量,例如cpu以及QPS 有2个度量的时候,其每个度量都可以单独的按照度量标准计算,之后对于每个度量取得的最佳pod数量取最大值,这个文字描述可能不算准确,可以通过下面的一幅图来直观的描述上面的内容
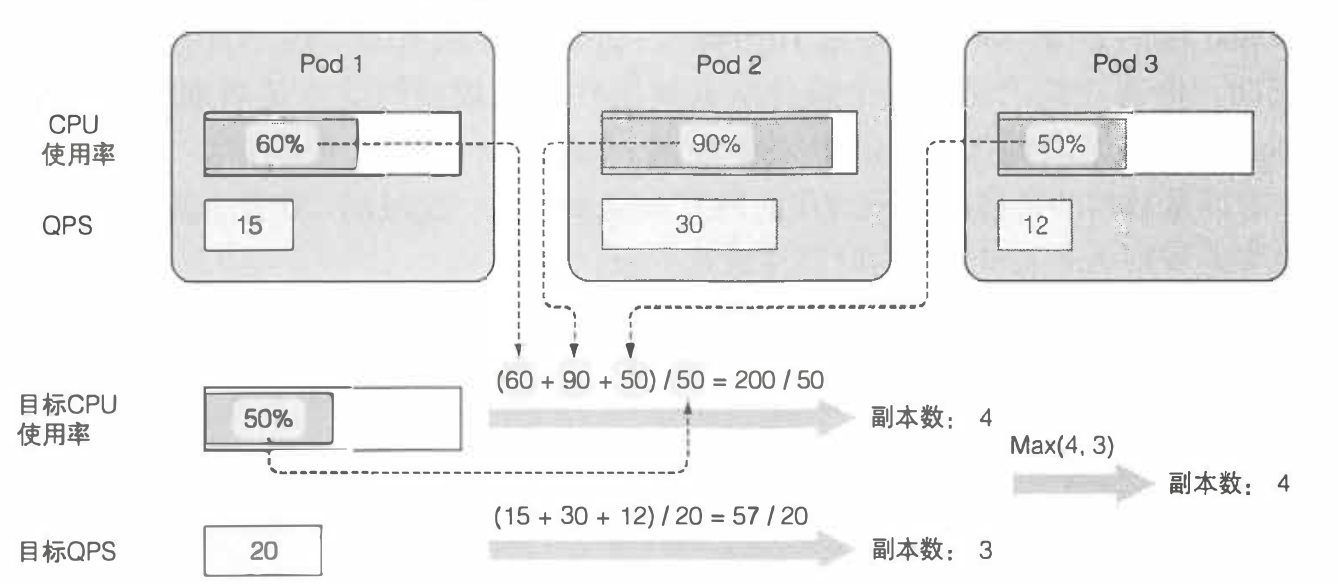
- 这三个pod的QPS以及CPU使用率的标准值是50,以及20
- 通过计算总和除以均值分别得到pod的数量应为3,4,这里我们应当取最大值
2.4 更新被伸缩资源的副本数
Autoscale控制器通过子资源Scale子资源来修改replicas进入达到对replicas进行修改,进而实现对pod进行阔缩容

2.5 只要API服务器为某个可伸缩资源爆露了子Scale资源,AutoScale即可以操作该资源,目前暴露子资源的有
- Deployment
- ReplicaSet
- ReplicationController
- StatefulSet
2.6 下面用一幅图来描述整个伸缩的过程
值得一提的是,由于cAdvisor需要周期性的拉取节点上面pod的配置,同理Heapster以及HPA控制器都是如此,所以在探测到需要扩缩容到实际完成的话,需要相当的一段时间,具体如下图所示
三 通过一个实例来描述整个流程是什么样子的
3.1 创建一个用来伸缩的deployment
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: kubia
spec:
replicas: 3
template:
metadata:
name: kubia
labels:
app: kubia
spec:
containers:
- image: luksa/kubia:v1
name: nodejs
resources:
requests:
cpu: 100m
memory: 100Mi
3.2 之后创建一个HPA用以对这个deployment进行伸缩管控
k autoscale deployment kubia --cpu-percent=30 --min=1 --max=5 [root@node01 Chapter15]# k get hpa -o yaml
apiVersion: v1
items:
- apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
......
spec:
maxReplicas: 5
minReplicas: 1
scaleTargetRef:
apiVersion: extensions/v1beta1
kind: Deployment
name: kubia
targetCPUUtilizationPercentage: 30
status:
currentReplicas: 3
desiredReplicas: 0
kind: List
metadata:
resourceVersion: ""
selfLink: ""
- 这里分别注明来最大的副本数量以及最小的副本数量
- scaleTargetRef里面加上来伸缩的对象
- 同样上面红色部分还显示了pod的标准值以及资源状态
3.3 第一状态,由于一开始创建之初,并没有任何的流量会进来,所以hpa会通过scale将pod的副本数量逐渐缩容到1,并且当使用k describe hpa的时候会显示整个事情发生的过程,
之后需要让其扩容,通过一个服务来暴露这个deployment,最简单的就是使用
k expose deployment kubia --port=80 --target-port=8080
3.4 了解伸缩操作的最大速率
在伸缩的时候一般是当前已经存在的一倍,不会超过最大以及最小值
3.5 集群的横向伸缩
当在部署一个pod的时候,如果集群中任意一个节点都无法容纳它,那么我们就说这个集群里面的节点需要扩容了,并且在集群长时间资源空闲的时候下线机器,以此来对kubernetes来提供最大的机器资源利用量,这个操作对象叫clusterAutoscale,当某个节点上面的所有pod的请求量的cpu以及内存的使用量都不超过请求量的50%,那么clusterAutoScale则将会其视为需要下线的节点之一,第二个条件就是会检查上面是否存在不能挪走的pod例如系统pod,换言之,即该机器上面的pod都可以重新的去调度到其他的节点上面就可以标记下线,被标记下线的节点会被标记为不可调度。
3.6 确保即使因为节点上面被下线了,也能保证pod能够足量运行的资源podDisruptionBudget
通过命令行的形式创建一个pdb形式如下
k create pdb kubia-pdb --selector=app=kubia --min-available=3
kubernets之横向伸缩pod与集群节点的更多相关文章
- Kubernetes从懵圈到熟练:读懂这一篇,集群节点不下线
排查完全陌生的问题,完全不熟悉的系统组件,是售后工程师的一大工作乐趣,当然也是挑战.今天借这篇文章,跟大家分析一例这样的问题.排查过程中,需要理解一些自己完全陌生的组件,比如systemd和dbus. ...
- k8s集群节点更换ip 或者 k8s集群添加新节点
1.需求情景:机房网络调整,突然要回收我k8s集群上一台node节点机器的ip,并调予新的ip到这台机器上,所以有了k8s集群节点更换ip一说:同时,k8s集群节点更换ip也相当于k8s集群添加新节点 ...
- 被集群节点负载不均所困扰?TKE 重磅推出全链路调度解决方案
引言 在 K8s 集群运营过程中,常常会被节点 CPU 和内存的高使用率所困扰,既影响了节点上 Pod 的稳定运行,也会增加节点故障的几率.为了应对集群节点高负载的问题,平衡各个节点之间的资源使用率, ...
- 基于CentOS与VmwareStation10搭建Oracle11G RAC 64集群环境:4.安装Oracle RAC FAQ-4.3.Oracle 集群节点间连通失败
1.检查节点连通性的错误 [grid@linuxrac1 grid]$ ./runcluvfy.sh stage -post hwos -n linuxrac1,linuxrac2 -verbose ...
- Akka(12): 分布式运算:Cluster-Singleton-让运算在集群节点中自动转移
在很多应用场景中都会出现在系统中需要某类Actor的唯一实例(only instance).这个实例在集群环境中可能在任何一个节点上,但保证它是唯一的.Akka的Cluster-Singleton提供 ...
- 【故障公告】10:30-10:45 左右 docker swarm 集群节点问题引发故障
非常抱歉,今天 10:30-10:45 左右由于 docker swarm 集群节点出现问题,造成除博客之外的站点出现访问异常,由此给您带来很大的麻烦,请您谅解. 故障开始时出现有时访问正常有时访问出 ...
- Rabbitmq关于集群节点功能的读书笔记
消息和队列可以指定是否持久化,如果指定持久化则会保存到硬盘上 ,不然只在内存里 普通集群模式下持久化的队列不能重建了 内存节点和磁盘节点的区别就是将元数据放在了内存还是硬盘,仅此而已,当在集群中声明队 ...
- Quartz的集群模式和单机模式共存-让一个非集群的Quartz与集群节点并行着运行
假如你让一个非集群的 Quartz 应用与集群节点并行着运行,设法使用 JobInitializationPlugin和 RAMJobStore Quartz支持可选节点执行jobquartz集群,会 ...
- 删除RAC集群节点
删除GRID集群节点:参考oracle database 11g RAC手册(第二版) 目前GRID集群中节点信息:[grid@node1 ~]$ olsnodesnode1node2node3nod ...
- 如何诊断 11.2 集群节点驱逐问题 (文档 ID 1674872.1)
适用于: Oracle Database - Enterprise Edition - 版本 11.2.0.1 到 11.2.0.2 [发行版 11.2]本文档所含信息适用于所有平台 用途 这篇文档提 ...
随机推荐
- MySQL基本手册
MySQL配置文件 MySQL软件使用的配置文件名为my.ini,在安装目录下. MySQL常用配置参数: 1.default-character-set:客户端默认字符集. 2.character- ...
- Git 11 设置项目提交人
前面介绍了可以给 Git 设置全局提交人,这样当前电脑所有项目提交人都会变成设置的值. 但实际开发中有时候需要给不同项目设置不同提交人. 比如工作的项目是一个提交人,自己维护的开源项目又是另一个提交人 ...
- windows下redis主从配置
1,复制两个redis文件夹,粘贴在同级目录下 2,分别修改6380和6381文件夹中的redis.window.conf文件 port:分别改为6380.6381 均增加:slaveof 127.0 ...
- modbus通信案例简单介绍
介绍: 1.仪表等其他智能设备的modbus通信协议,确定其内部功能码地址.以型号U-MIK-P350-SCN2的杭州美控公司的压力变送器为例.查看对应手册20页.2.PLC端的编程配置.以西门子s7 ...
- webkit简介
WebKit是一款开源的浏览器引擎,主要用于渲染HTML网页和执行JavaScript代码.WebKit起源于苹果公司,最初是为了开发Safari浏览器而创建的.现在,它已经成为许多浏览器(如苹果的S ...
- gRPC入门学习之旅(七)
gRPC入门学习之旅(一) gRPC入门学习之旅(二) gRPC入门学习之旅(三) gRPC入门学习之旅(四) gRPC入门学习之旅(五) gRPC入门学习之旅(六) 3.6.创建gRPC的桌面应用客 ...
- 转载 | 如何把 thinkphp5 的项目迁移到阿里云函数计算来应对流量洪峰?
简介: 函数计算评测局的优秀征文! 如何把thinkphp5的项目迁移到阿里云函数计算来应对流量洪峰? 1. 为什么要迁移到阿里云函数? 我的项目是一个节日礼品领取项目,过节的时候会有短时间的流量洪峰 ...
- [GPT] 提高个人网站的访问量的 30 种详细方式
内容优化:提高网站的质量和价值,让用户喜欢并分享你的内容. SEO优化:通过关键词优化.网站结构优化等方式,提高搜索引擎排名. 社交媒体:在社交媒体上分享你的内容,吸引更多人来访问你的网站. 广告投放 ...
- WPF 基于 .NET 5 框架和 .NET 6 的 SDK 进行完全单文件发布
本文来告诉大家如何基于 .NET 5 框架和 .NET 6 SDK 进行完全单文件发布,这是对 WPF 应用程序进行独立发布,生成的是完全单文件的方法 在之前的版本,尽管也是基于 .NET 5 框架的 ...
- 鸿蒙HarmonyOS实战-ArkUI事件(键鼠事件)
前言 键鼠事件是指在计算机操作中,用户通过键盘和鼠标来与计算机进行交互的行为.常见的键鼠事件包括按下键盘上的键.移动鼠标.点击鼠标左键或右键等等.键鼠事件可以触发许多不同的操作,比如在文本编辑器中输入 ...