防缓存穿透利器-布隆滤器(BloomFilter)
布隆过滤器
1、布隆过滤器原理
1.1 什么是布隆过滤器
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。
主要用于判断一个元素是否在一个集合中,0代表不存在某个数据,1代表存在某个数据。
总结: 一个元素一定不存在 或者 可能存在! 存在一定的误判率{通过代码调节}
1.2 使用场景
大数据量的时候, 判断一个元素是否在一个集合中。解决缓存穿透问题
1.3 原理
存入过程
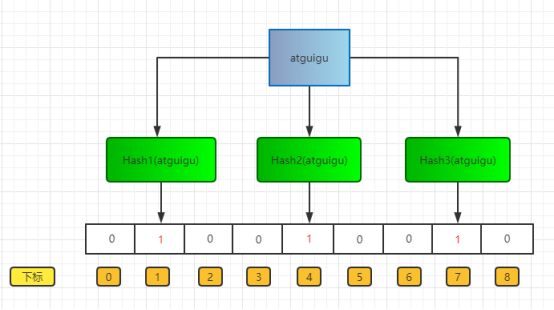
布隆过滤器上面说了,就是一个二进制数据的集合。当一个数据加入这个集合时,经历如下:
通过K个哈希函数计算该数据,返回K个计算出的hash值
这些K个hash值映射到对应的K个二进制的数组下标
将K个下标对应的二进制数据改成1。
例如,第一个哈希函数返回x,第二个第三个哈希函数返回y与z,那么: X、Y、Z对应的二进制改成1。
如图所示:
查询过程
布隆过滤器主要作用就是查询一个数据,在不在这个二进制的集合中,查询过程如下:
1、通过K个哈希函数计算该数据,对应计算出的K个hash值
2、通过hash值找到对应的二进制的数组下标
3、判断:如果存在一处位置的二进制数据是0,那么该数据不存在。如果都是1,该数据存在集合中。
1.4 布隆过滤器的优缺点
- 优点
- 由于存储的是二进制数据,所以占用的空间很小
- 它的插入和查询速度是非常快的,时间复杂度是O(K),空间复杂度:O (M)。
K: 是哈希函数的个数
M: 是二进制位的个数
- 保密性很好,因为本身不存储任何原始数据,只有二进制数据
- 缺点:
添加数据是通过计算数据的hash值,那么很有可能存在这种情况:两个不同的数据计算得到相同的hash值。
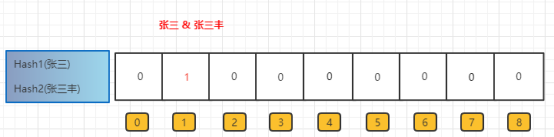
例如图中的“张三”和“张三丰”,假如最终算出hash值相同,那么他们会将同一个下标的二进制数据改为1。
这个时候,你就不知道下标为1的二进制,到底是代表“张三”还是“张三丰”。
由此得出以下缺点:
1、存在误判
假如上面的图没有存 “张三”,只存了 “张三丰”,那么用"张三"来查询的时候,会判断"张三"存在集合中。
因为“张三”和“张三丰”的hash值是相同的,通过相同的hash值,找到的二进制数据也是一样的,都是1。
误判率:
受三个因素影响: 二进制位的个数m, 哈希函数的个数k, 数据规模n (添加到布隆过滤器中的数据)
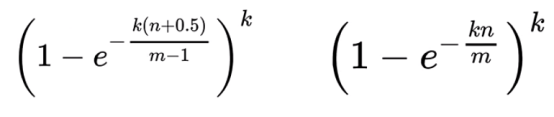
已知误判率p, 数据规模n, 求二进制的个数m,哈希函数的个数k {m,k 程序会自动计算 ,你只需要告诉我数据规模,误判率就可以了}
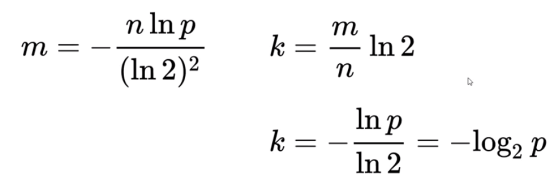
ln: 自然对数是以常数e为底数的对数,记作lnN(N>0)。在物理学,生物学等自然科学中有重要的意义,一般表示方法为lnx。数学中也常见以logx表示自然对数。
2、删除困难
还是用上面的举例,因为“张三”和“张三丰”的hash值相同,对应的数组下标也是一样的。
如果你想去删除“张三”,将下标为1里的二进制数据,由1改成了0。
那么你是不是连“张三丰”都一起删了。
2、实现方式
2.1 初始化skuId的布隆过滤器
我在service-product模块中操作
2.1.1 RedisConst常量类
public class RedisConst {
public static final String SKUKEY_PREFIX = "sku:";
public static final String SKUKEY_SUFFIX = ":info";
//单位:秒
public static final long SKUKEY_TIMEOUT = 24 * 60 * 60;
// 定义变量,记录空对象的缓存过期时间
public static final long SKUKEY_TEMPORARY_TIMEOUT = 10 * 60;
//单位:秒 尝试获取锁的最大等待时间
public static final long SKULOCK_EXPIRE_PX1 = 100;
//单位:秒 锁的持有时间
public static final long SKULOCK_EXPIRE_PX2 = 10;
public static final String SKULOCK_SUFFIX = ":lock";
public static final String USER_KEY_PREFIX = "user:";
public static final String USER_CART_KEY_SUFFIX = ":cart";
public static final long USER_CART_EXPIRE = 60 * 60 * 24 * 30;
//用户登录
public static final String USER_LOGIN_KEY_PREFIX = "user:login:";
// public static final String userinfoKey_suffix = ":info";
public static final int USERKEY_TIMEOUT = 60 * 60 * 24 * 7;
//秒杀商品前缀
public static final String SECKILL_GOODS = "seckill:goods";
public static final String SECKILL_ORDERS = "seckill:orders";
public static final String SECKILL_ORDERS_USERS = "seckill:orders:users";
public static final String SECKILL_STOCK_PREFIX = "seckill:stock:";
public static final String SECKILL_USER = "seckill:user:";
//用户锁定时间 单位:秒
public static final int SECKILL__TIMEOUT = 60 * 60 * 1;
// 布隆过滤器使用!
public static final String SKU_BLOOM_FILTER="sku:bloom:filter";
}
123456789101112131415161718192021222324252627282930313233343536
2.1.2 修改启动类
@SpringBootApplication
@ComponentScan({"com.atguigu.gmall"})
@EnableDiscoveryClient
public class ServiceProductApplication implements CommandLineRunner {
@Autowired
private RedissonClient redissonClient;
public static void main(String[] args) {
SpringApplication.run(ServiceProductApplication.class,args);
}
//初始化布隆过滤器
@Override
public void run(String... args) throws Exception {
//获取布隆过滤器
RBloomFilter<Object> bloomFilter = redissonClient.getBloomFilter(RedisConst.SKU_BLOOM_FILTER);
//初始化布隆过滤器:计算元素的数量 比如预计有多少个sku
bloomFilter.tryInit(10001,0.001);
}
}
123456789101112131415161718192021
2.2 给商品详情页添加布隆过滤器
1、查看商品详情页添加布隆过滤器
操作模块:service-item
更改ItemserviceImpl.item方法
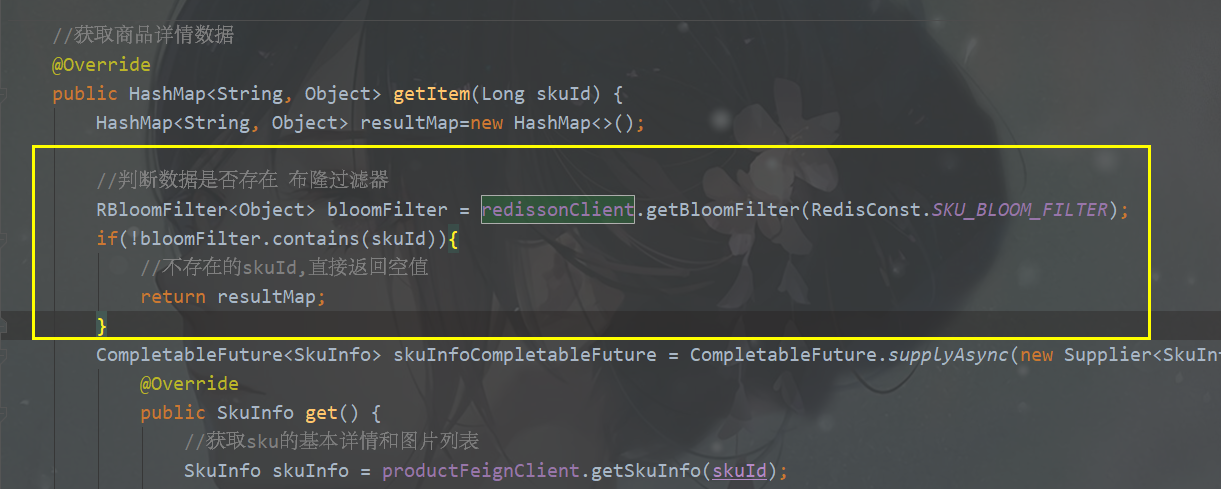
2、添加商品sku加入布隆过滤器数据
操作模块:service-product
更改ManageServiceImpl.saveSkuInfo方法
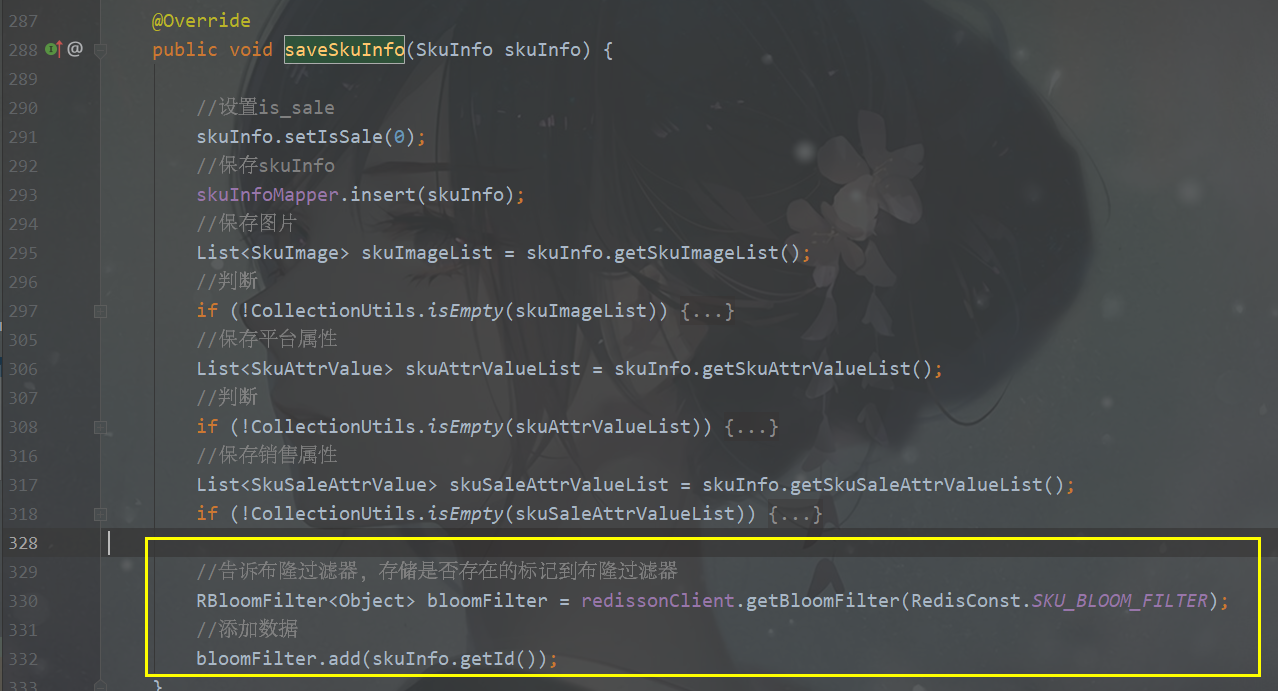
这样就避免了别人用一个不存在的key去疯狂攻击我们的缓存数据库。
我们在分布式锁中将查询结果是null的也进行缓存,但是如果有人用随机数去疯狂请求我们的接口,那我们的Redis可能会扛不住,所以在这里用布隆过滤器,只需要在初始化的时候,指定我们存储数据的数据量和可以承受的误判率即可。
布隆过滤器指导有哪些数据,这样别人使用随机数攻击的时候直接就给他返回,不用再去查Redis了。
防缓存穿透利器-布隆滤器(BloomFilter)的更多相关文章
- Redis缓存穿透问题及解决方案
上周在工作中遇到了一个问题场景,即查询商品的配件信息时(商品:配件为1:N的关系),如若商品并未配置配件信息,则查数据库为空,且不会加入缓存,这就会导致,下次在查询同样商品的配件时,由于缓存未命中,则 ...
- Redis缓存穿透和缓存雪崩以及解决方案
Redis缓存穿透和缓存雪崩以及解决方案 Redis缓存穿透和缓存雪崩以及解决方案缓存穿透解决方案布隆过滤缓存空对象比较缓存雪崩解决方案保证缓存层服务高可用性依赖隔离组件为后端限流并降级数据预热缓存并 ...
- Redis: 缓存过期、缓存雪崩、缓存穿透、缓存击穿(热点)、缓存并发(热点)、多级缓存、布隆过滤器
Redis: 缓存过期.缓存雪崩.缓存穿透.缓存击穿(热点).缓存并发(热点).多级缓存.布隆过滤器 2019年08月18日 16:34:24 hanchao5272 阅读数 1026更多 分类专栏: ...
- Bloom Filter(布隆过滤器)如何解决缓存穿透
本文摘抄自我的微信公众号"程序员柯南",欢迎关注!原文阅读 缓存穿透是什么? 关于缓存穿透,简单来说就是系统处理了大量不存在的数据查询.正常的使用缓存流程大致是,数据查询先进行缓存 ...
- redis缓存穿透穿透解决方案-布隆过滤器
redis缓存穿透穿透解决方案-布隆过滤器 我们先来看一段代码 cache_key = "id:1" cache_value = GetValueFromRedis(cache_k ...
- Redis缓存穿透、缓存雪崩、redis并发问题 并发竞争key的解决方案 (阿里)
阿里的人问我 缓存雪崩(大量数据在同一时间过期了)了如何处理,缓存击穿了如何处理,回答的很烂,做了总结: 把redis作为缓存使用已经是司空见惯,但是使用redis后也可能会碰到一系列的问题,尤其是数 ...
- redis缓存雪崩、缓存穿透、数据库和redis数据一致性
一.缓存雪崩 回顾一下我们为什么要用缓存(Redis):减轻数据库压力或尽可能少的访问数据库. 在前面学习我们都知道Redis不可能把所有的数据都缓存起来(内存昂贵且有限),所以Redis需要对数据设 ...
- Redis基础用法、高级特性与性能调优以及缓存穿透等分析
一.Redis介绍 Redis是一个开源的,基于内存的结构化数据存储媒介,可以作为数据库.缓存服务或消息服务使用.Redis支持多种数据结构,包括字符串.哈希表.链表.集合.有序集合.位图.Hype ...
- 缓存与数据库一致性之三:缓存穿透、缓存雪崩、key重建方案
一.缓存穿透预防及优化 缓存穿透是指查询一个根本不存在的数据,缓存层和存储层都不会命中,但是出于容错的考虑,如果从存储层查不到数据则不写入缓存层,如图 11-3 所示整个过程分为如下 3 步: 缓存层 ...
- Redis缓存雪崩、缓存穿透、热点Key解决方案和分析
缓存穿透 缓存系统,按照KEY去查询VALUE,当KEY对应的VALUE一定不存在的时候并对KEY并发请求量很大的时候,就会对后端造成很大的压力. (查询一个必然不存在的数据.比如文章表,查询一个不存 ...
随机推荐
- 【ACM组合数学 | 错排公式】写信
题目链接:https://ac.nowcoder.com/acm/contest/54484/B 题意很简单,但是数据范围偏大. 错排公式 首先来推导一下错排公式: \[D(n) = n!\sum_{ ...
- c/c++零基础坐牢第三天
c/c++从入门到入土(3) 开始时间2023-04-17 19:07:20 结束时间2023-04-17 20:53:40 前言:经过三天的算法训练,大家肯定对后面的编程知识产生浓厚的兴趣,有了前两 ...
- C# 强行关闭其他软件对文件的占用
using System.Diagnostics; // 获取占用文件的进程并强制结束 public void CloseProcessByFileName(string fileName) { Pr ...
- 产品质量管理利器,华为云发布CodeArts Defect缺陷管理服务
摘要:近日,华为云CodeArts Defect缺陷管理服务正式上线,提供结构化缺陷跟踪流程和标准化的质量度量模型. 本文分享自华为云社区<产品质量管理利器,华为云发布CodeArts Defe ...
- [Pytorch框架] 1.1、Pytorch简介
文章目录 1.1 Pytorch 简介 1.1.1 PyTorch的由来 1.1.2 Torch是什么? 1.1.3 重新介绍 PyTorch 1.1.4 对比PyTorch和Tensorflow 1 ...
- 2021牛客OI赛前集训营-提高组(第二场)第三题 树数树题解
题目描述 牛牛有一棵 \(n\) 个点的有根树,根为 \(1\). 我们称一个长度为 \(m\) 的序列 \(a\) 是好的,当且仅当: \(\forall i \in (1,m]\),\(a_i\) ...
- 点&边双连通分量
双连通分量 参考博客:https://www.cnblogs.com/jiamian/p/11202189.html#_2 概念 双连通分量有点双连通分量和边双连通分量两种.若一个无向图中的去掉任意一 ...
- 【CSS】画出宽度为1像素的线或边框
由于多倍的设计图在移动设备上显示时会将设计图进行缩小到视口宽度,而1px的边框没有随着页面进行缩小而导致效果太粗,想要还原设计图1px的显示效果,因此需要一些方法来实现边框宽度小于1px. 实现方法很 ...
- 基于APM模式的异步实现及跨线程操作窗体或控件方法的实现示例
最近在一家某电力外派公司开发相关于GIS的功能,在实现代码的过程中出现了一些常见的问题比如: 1.跨线程执行窗体或控件操作(直接使用委拖) 2.异步模式执行某长时间耗时方法 经过一系列摸索可算找到解决 ...
- Hibernate 基本操作、懒加载以及缓存
前言 上一篇咱们介绍了 Hibernate 以及写了一个 Hibernate 的工具类,快速入门体验了一波 Hibernate 的使用,我们只需通过 Session 对象就能实现数据库的操作了. 现在 ...