[转帖]043、TiDB特性_缓存表和分区表
针对于优化器在索引存在时依然使⽤全表扫描的情况下,使⽤缓存表和分区表是提升查询性能的有效⼿段。
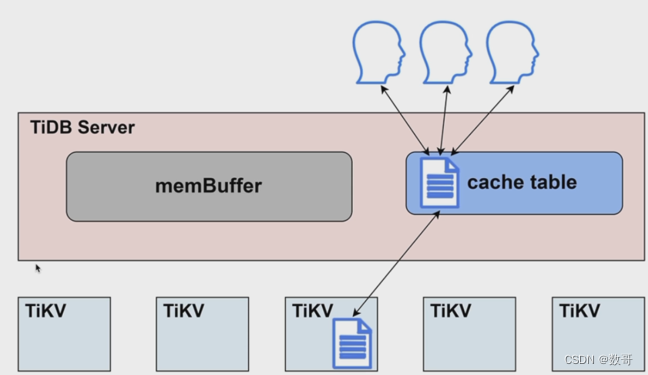
缓存表
- 缓存表是将表的内容完全缓存到 TiDB Server 的内存中
- 表的数据量不⼤,⼏乎不更改
- 读取很频繁
- 缓存控制: ALTER TABLE table_name CACHE|NOCACHE;
# 使用trace跟踪下
tidb> TRACE SELECT * FROM test.c1;
+-------------------------------------------+-----------------+---
---------+
| operation | startTS |
duration |
+-------------------------------------------+-----------------+---
---------+
| trace | 18:39:25.485266 |
501.582µs |
| ├─session.ExecuteStmt | 18:39:25.485270 |
432.208µs |
| │ ├─executor.Compile | 18:39:25.485281 |
132.616µs |
| │ └─session.runStmt | 18:39:25.485433 |
249.488µs |
| │ └─UnionScanExec.Open | 18:39:25.485572 |
72.776µs |
| │ ├─TableReaderExecutor.Open | 18:39:25.485575 |
13.24µs |
| │ ├─buildMemTableReader | 18:39:25.485605 |
3.283µs |
| │ └─memTableReader.getMemRows | 18:39:25.485615 | # memTableReader.getMemRows 表示从缓存取数
20.558µs |
| ├─*executor.ProjectionExec.Next | 18:39:25.485712 |
12.911µs |
| │ └─*executor.UnionScanExec.Next | 18:39:25.485714 |
3.823µs |
| └─*executor.ProjectionExec.Next | 18:39:25.485733 |
8.943µs |
| └─*executor.UnionScanExec.Next | 18:39:25.485735 |
1.33µs |
+-------------------------------------------+-----------------+---
---------+
12 rows in set (0.00 sec)
小表缓存-原理
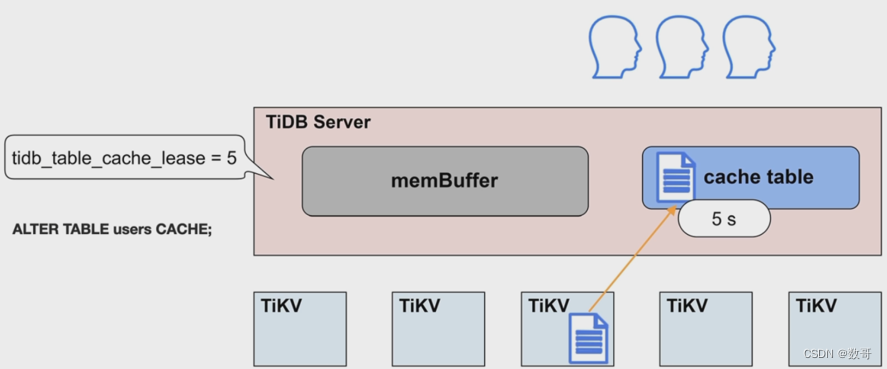
缓存租约
租约时间内,无法进行写操作
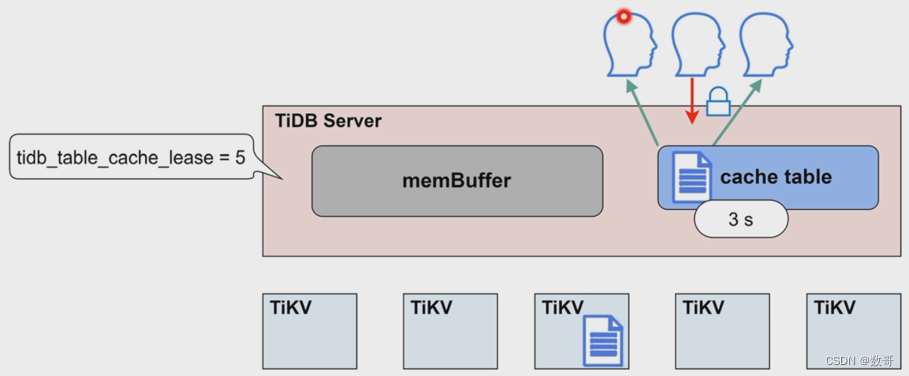
租约到期,数据过期
写操作不再被阻塞
读写直接到TiKV节点上执行
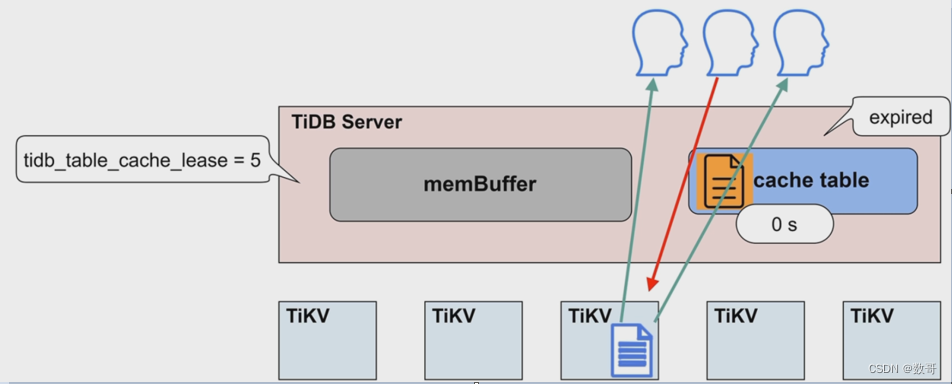
数据更新完毕,租约继续开启
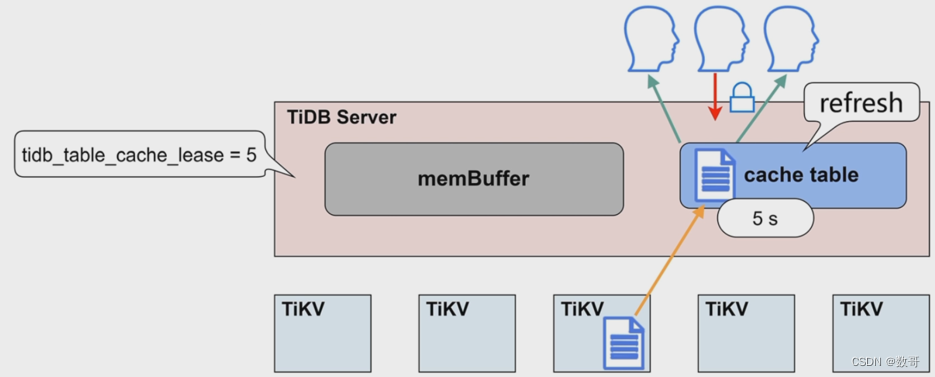
应用场景
- 每张缓存表的大小限制为64MB
- 适用于查询频繁、数据量不大、修改极少的场景
- 在租约(tidb_table_cache_lease) 时间内,写操作会被阻塞
- 当租约到期(tidb_table_cache_lease)时,读性能会下降
- 不支持对缓存表直接做DDL操作,需要先关闭
- 对于表加载较慢或者极少修改的表,可以适当延长tidb_table_cache_lease保持读性能稳定
分区表
分区类型与适用场景
- range: 分区剪裁,节省IO开销
- Hash: 用于大规模写入的情况下将数据打散,平均地分配到各个分区里
Range分区表
create table t1(x int) partition by name(x) (
partition p0 values less than(5),
partition p1 values less than (10));
)
分区类型与适⽤场景
- Range
分区裁剪, 节省 I/O 开销
/* Range Partition t1 */
drop table if exists test.t1;
create table test.t1 (x int) partition by range (x) (
partition p0 values less than (5),
partition p1 values less than (10));
insert into test.t1 values (0),(1),(2),(3),(4),(5),(6),(7),(8),(9);
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
/* Check Partition Pruning */
explain select * from test.t1 where x between 1 and 4;
查看执行计划
mysql> explain select * from test.t1 where x between 1 and 4;
+-------------------------+-----------+-----------+------------------------+------------------------------------+
| id | estRows | task | access object | operator info |
+-------------------------+-----------+-----------+------------------------+------------------------------------+
| TableReader_9 | 12288.00 | root | | data:Selection_8 |
| └─Selection_8 | 12288.00 | cop[tikv] | | ge(test.t1.x, 1), le(test.t1.x, 4) |
| └─TableFullScan_7 | 491520.00 | cop[tikv] | table:t1, partition:p0 | keep order:false |
+-------------------------+-----------+-----------+------------------------+------------------------------------+
3 rows in set (0.03 sec)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
/* Check regions */
show table test.t1 regions;
mysql> show table test.t1 regions;
+-----------+-----------+---------+-----------+-----------------+-------+------------+---------------+------------+----------------------+------------------+
| REGION_ID | START_KEY | END_KEY | LEADER_ID | LEADER_STORE_ID | PEERS | SCATTERING | WRITTEN_BYTES | READ_BYTES | APPROXIMATE_SIZE(MB) | APPROXIMATE_KEYS |
+-----------+-----------+---------+-----------+-----------------+-------+------------+---------------+------------+----------------------+------------------+
| 5019 | t_79_ | t_80_ | 5020 | 1001 | 5020 | 0 | 0 | 0 | 67 | 877551 |
| 1002 | t_80_ | | 1003 | 1001 | 1003 | 0 | 0 | 0 | 24 | 421921 |
+-----------+-----------+---------+-----------+-----------------+-------+------------+---------------+------------+----------------------+------------------+
2 rows in set (0.02 sec)
- Hash
可以⽤于⼤规模写⼊的情况下将数据打散, 平均地分配到各个分区⾥
/* Hash Partition t1 */
drop table if exists test.t1;
CREATE TABLE test.t1 (x INT)
PARTITION BY HASH(x)
PARTITIONS 4;
insert into test.t1 values (0),(1),(2),(3),(4),(5),(6),(7),(8),(9);
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
查看分区的执行计划
- 默认是通过mod方式分配分区
/* Check Partition Distribution */
explain select from test.t1 where x=0;
explain select from test.t1 where x=1;
explain select from test.t1 where x=2;
explain select from test.t1 where x=3;
explain select from test.t1 where x=4;
explain select from test.t1 where x=5;
explain select from test.t1 where x=6;
explain select from test.t1 where x=7;
explain select from test.t1 where x=8;
explain select from test.t1 where x=9;
/* Negative /
explain select from test.t1 where x between 7 and 9;
mysql> explain select * from test.t1 where x between 7 and 9;
+------------------------------+----------+-----------+------------------------+------------------------------------+
| id | estRows | task | access object | operator info |
+------------------------------+----------+-----------+------------------------+------------------------------------+
| PartitionUnion_10 | 750.00 | root | | |
| ├─TableReader_13 | 250.00 | root | | data:Selection_12 |
| │ └─Selection_12 | 250.00 | cop[tikv] | | ge(test.t1.x, 7), le(test.t1.x, 9) |
| │ └─TableFullScan_11 | 10000.00 | cop[tikv] | table:t1, partition:p0 | keep order:false, stats:pseudo |
| ├─TableReader_16 | 250.00 | root | | data:Selection_15 |
| │ └─Selection_15 | 250.00 | cop[tikv] | | ge(test.t1.x, 7), le(test.t1.x, 9) |
| │ └─TableFullScan_14 | 10000.00 | cop[tikv] | table:t1, partition:p1 | keep order:false, stats:pseudo |
| └─TableReader_19 | 250.00 | root | | data:Selection_18 |
| └─Selection_18 | 250.00 | cop[tikv] | | ge(test.t1.x, 7), le(test.t1.x, 9) |
| └─TableFullScan_17 | 10000.00 | cop[tikv] | table:t1, partition:p3 | keep order:false, stats:pseudo |
+------------------------------+----------+-----------+------------------------+------------------------------------+
10 rows in set (12.69 sec)
查看region分布情况
/* Check regions */
# 查看对应的region情况,在4个region上
mysql> show table test.t1 regions;
+-----------+-----------+---------+-----------+-----------------+-------+------------+---------------+------------+----------------------+------------------+
| REGION_ID | START_KEY | END_KEY | LEADER_ID | LEADER_STORE_ID | PEERS | SCATTERING | WRITTEN_BYTES | READ_BYTES | APPROXIMATE_SIZE(MB) | APPROXIMATE_KEYS |
+-----------+-----------+---------+-----------+-----------------+-------+------------+---------------+------------+----------------------+------------------+
| 9003 | t_84_ | t_85_ | 9004 | 1001 | 9004 | 0 | 18449249 | 14117466 | 13 | 141205 |
| 9005 | t_85_ | t_86_ | 9006 | 1001 | 9006 | 0 | 18443067 | 14024508 | 10 | 58475 |
| 9007 | t_86_ | t_87_ | 9008 | 1001 | 9008 | 0 | 12295360 | 8703102 | 5 | 27228 |
| 1002 | t_87_ | | 1003 | 1001 | 1003 | 0 | 12295959 | 9218671 | 4 | 26666 |
+-----------+-----------+---------+-----------+-----------------+-------+------------+---------------+------------+----------------------+------------------+
4 rows in set (2 min 46.43 sec)
[转帖]043、TiDB特性_缓存表和分区表的更多相关文章
- (转载)详解网络传输中的三张表,MAC地址表、ARP缓存表以及路由表
郑重声明:原文转载于http://dengqi.blog.51cto.com/5685776/1223132 向好文章致敬!!! 一:MAC地址表详解 说到MAC地址表,就不得不说一下交换机的工作原理 ...
- Spring4.1新特性——Spring缓存框架增强(转)
目录 Spring4.1新特性——综述 Spring4.1新特性——Spring核心部分及其他 Spring4.1新特性——Spring缓存框架增强 Spring4.1新特性——异步调用和事件机制的异 ...
- ARP缓存表的构成ARP协议全面实战协议详解、攻击与防御
ARP缓存表的构成ARP协议全面实战协议详解.攻击与防御 1.4.3 ARP缓存表的构成 在局域网的任何一台主机中,都有一个ARP缓存表.该缓存表中保存中多个ARP条目.每个ARP条目都是由一个IP ...
- Oracle11g新特性导致空表不能导出问题
ORACLE 11G在用EXP导出时,发现空表(没有数据或者没有用过的表)不能导出了. 查了一下资料,说是Oracle 11G中有个新特性,当表无数据时,不分配segment,以节省空 ...
- 关于我们_ | 腕表时代watchtimes.com.cn
关于我们_ | 腕表时代watchtimes.com.cn 关于我们 腕表时代是北京兰会时光科技有限公司旗下运营的手表网站.腕表时代于2013年5月17日正式上线.秉承专业.生动.实用 ...
- 网络传输中的三张表,MAC地址表、ARP缓存表以及路由表
一:MAC地址表详解 说到MAC地址表,就不得不说一下交换机的工作原理了,因为交换机是根据MAC地址表转发数据帧的.在交换机中有一张记录着局域网主机MAC地址与交换机接口的对应关系的表,交换机就是根据 ...
- SQL基本查询_单表查询(实验二)
SQL基本查询_单表查询(实验二) 查询目标表结构及数据 emp empno ename job hiedate sal comn deptno 1007 马明 内勤 1992-6-12 4000 2 ...
- SQL基本查询_多表查询(实验三)
SQL基本查询_多表查询(实验三) 题目要求(一) 针对emp.dept两表完成如下查询,并验证查询结果的正确性 使用显式内连接查询所有员工的信息,显示其编号.姓名.薪水.入职日期及部门名称: 使用隐 ...
- SQL Server 表的管理_关于表的操作增删查改的操作的详解(案例代码)
SQL Server 表的管理_关于表的操作增删查改的操作的详解(案例代码) 概述: 表由行和列组成,每个表都必须有个表名. SQL CREATE TABLE 语法 CREATE TABLE tabl ...
- 缓存表 内存表(将表keep到内存)
缓存表 内存表(将表keep到内存) 一.引言: 有时候一些基础表需要非常的频繁访问,尤其是在一些循环中,对该表中的访问速度将变的非常重要.为了提高系统的处理性能,可以考虑将一些表及索引读取并 ...
随机推荐
- sed 命令进阶
sed 是面向行处理的,但是有时可能希望针对多行作为一个单位进行处理,在 sed 中这也是可行的,本文将介绍如何使用 sed 来同时处理多行文本 理论基础 模式空间(Pattern Space):是一 ...
- LeetCode DFS、BFS篇(102、200、111、752)
102. 二叉树的层序遍历 给你一个二叉树,请你返回其按 层序遍历 得到的节点值. (即逐层地,从左到右访问所有节点). 示例: 二叉树:[3,9,20,null,null,15,7], 3 / 9 ...
- 过亿云资源运维管控难?华为云CloudMap带你喝着咖啡做运维
摘要:华为云站点数字化平台CloudMap携手华为云图引擎GES打造云服务全栈拓扑,网络流量路径和云服务动态依赖等空间关系数据,支撑现网运行态风险识别和分钟级定位定界,构建业界领先的数字化能力. 本文 ...
- 鸿蒙轻内核M核源码分析:中断Hwi
摘要:本文带领大家一起剖析了鸿蒙轻内核的中断模块的源代码,掌握中断相关的概念,中断初始化操作,中断创建.删除,开关中断操作等. 本文分享自华为云社区<鸿蒙轻内核M核源码分析系列五 中断Hwi&g ...
- 面试官:说一下Jena推理
摘要:本文介绍了Jena的推理子系统,并构建了一个简单的RDF图.基于该RDF图,我们搭建了一个Jena推理引擎,并进行自动化推理. 本文分享自华为云社区<知识推理之基于jena的知识推理(三) ...
- 谁说Redis不能存大key
摘要:推荐使用GaussDB(for Redis)搞定"大key"存储,从根本上解决社区版Redis使用风险. 本文分享自华为云社区<华为云GaussDB(for Redis ...
- Solon 的热插拔能力框架 “solon.hotplug” 介绍
<dependency> <groupId>org.noear</groupId> <artifactId>solon.hotplug</arti ...
- MongoDB 读写分离——SpringBoot读写分离
application.yml data: mongodb: uri: mongodb://127.0.0.1:27017,127.0.0.1:27018,127.0.0.1:27019/fecg_d ...
- 台大李宏毅机器学习公开课2020版登陆B站
课程简介: 真正大师的课程往往都是免费的,诸如吴恩达,李飞飞等.不过大家应该对李宏毅老师也不陌生吧?很多机器学习初学者,首选李宏毅老师.毕竟中文授课,而且他讲课通俗易懂.课程案例生动有趣(还记得宝可梦 ...
- Windows 环境下安装与配置 Node.js
一.下载Node.js安装包 下载地址:http://nodejs.cn/download/ 本教程以msi安装包为例 点击Windows 安装包下载 二.安装Node.js 1.打开安装包 欢迎页: ...